Python是进行数据分析的一种出色语言,主要是因为以数据为中心的python软件包具有奇妙的生态系统。 Pandas是其中的一种,使导入和分析数据更加容易。
Pandas Index.factorize()函数将对象编码为枚举类型或分类变量。当所有重要的事情是识别不同的值时,此方法对于获取数组的数字表示很有用。 factorize既可以用作顶层函数pandas.factorize(),也可以作为方法Series.factorize()和Index.factorize()使用。
用法: Index.factorize(sort=False, na_sentinel=-1)
参数:
sort:排序唯一性和随机标签以保持关系。
na_sentinel:标记“not found”的值。
返回:整数ndarray,是唯一性的索引器。 uniques.take(labels)将具有与值相同的值。
范例1:采用Index.factorize()函数将给定的Index值编码为分类形式。
# importing pandas as pd
import pandas as pd
# Creating the Index
idx = pd.Index(['Labrador', 'Beagle', 'Labrador',
'Lhasa', 'Husky', 'Beagle'])
# Print the Index
idx输出:
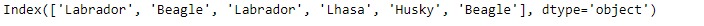
让我们分解给定的索引。
# convert it into categorical values.
idx.factorize()输出:

正如我们在输出中看到的,Index.factorize()函数已将Index中的每个标签转换为一个类别,并为其分配了数值。
范例2:采用Index.factorize()函数根据其排序顺序将索引值分解。
# importing pandas as pd
import pandas as pd
# Creating the Index
idx = pd.Index(['Jan', 'Feb', 'Mar', 'Apr', 'May', 'Jun',
'Jul', 'Aug', 'Sep', 'Oct', 'Nov', 'Dec'])
# Print the Index
idx输出:

让我们根据排序顺序将其分解。仅在对索引中的值进行排序后才分配数值。
# Factorize the sorted labels
idx.factorize(sort = True)输出:

正如我们在输出中看到的那样,在为索引值分配数值之前,已经对其进行了排序。
相关用法
- Python pandas.map()用法及代码示例
- Python Pandas DatetimeIndex.second用法及代码示例
- Python Pandas.CategoricalDtype()用法及代码示例
- Python Pandas PeriodIndex.day用法及代码示例
- Python Pandas Series.gt()用法及代码示例
- Python Pandas Index.contains()用法及代码示例
- Python Pandas dataframe.add()用法及代码示例
- Python Pandas Series.get()用法及代码示例
- Python Pandas.to_datetime()用法及代码示例
- Python Pandas Series.str.contains()用法及代码示例
- Python Pandas Timestamp.tz用法及代码示例
- Python Pandas Timestamp.dst用法及代码示例
- Python Pandas Series.abs()用法及代码示例
- Python Pandas Timestamp.day用法及代码示例
- Python Pandas Series.where用法及代码示例
注:本文由纯净天空筛选整理自Shubham__Ranjan大神的英文原创作品 Python | Pandas Index.factorize()。非经特殊声明,原始代码版权归原作者所有,本译文未经允许或授权,请勿转载或复制。