Python是进行数据分析的一种出色语言,主要是因为以数据为中心的python软件包具有奇妙的生态系统。 Pandas是其中的一种,使导入和分析数据更加容易。
Pandas dataframe.take()函数沿轴返回给定位置索引中的元素。这意味着我们没有根据对象的index属性中的实际值建立索引。我们正在根据元素在对象中的实际位置建立索引。
用法:DataFrame.take(indices, axis=0, convert=None, is_copy=True, **kwargs)
参数:
indices:一个整数数组,指示要采取的位置。
axis:选择元素的轴。 0表示我们正在选择行,1表示我们正在选择列
convert:是否将负索引转换为正索引。例如,-1将映射到len(axis)-1。转换类似于索引常规Python列表的行为。
is_copy:是否返回原始对象的副本。
** kwargs:为了与numpy.take()兼容。对输出没有影响。
返回:array-like包含从对象获取的元素。
要链接到代码中使用的CSV文件,请单击此处
范例1:采用take()函数在索引轴上获取一些值。
# importing pandas as pd
import pandas as pd
# Creating the dataframe
df = pd.read_csv("nba.csv")
# Print the dataframe
df
现在,我们将修改索引标签以进行演示。现在,标签的编号从0到914。
# double the value of index labels
df.index = df.index * 2
# Print the modified dataframe
df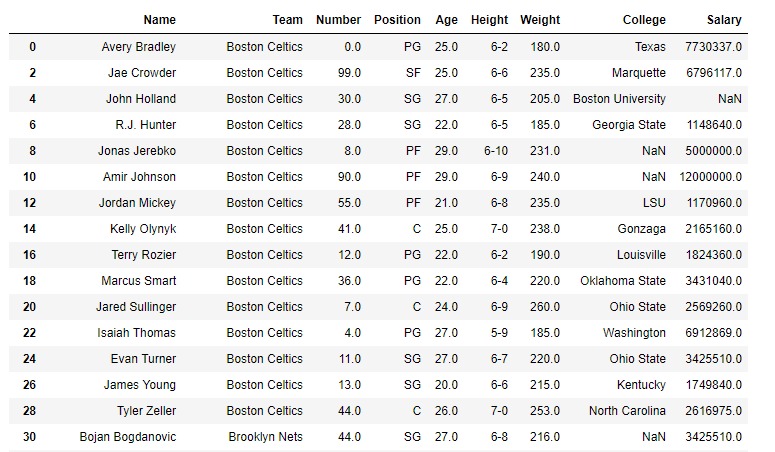
让我们取0、1和2位置的值
# take values at input position over the index axis
df.take([0, 1, 2], axis = 0)输出:

正如我们在输出中看到的那样,值是根据位置而不是索引标签选择的。
范例2:采用take()函数在列轴上的位置0、1和2处取值。
# importing pandas as pd
import pandas as pd
# Creating the dataframe
df = pd.read_csv("nba.csv")
# Print the dataframe
df
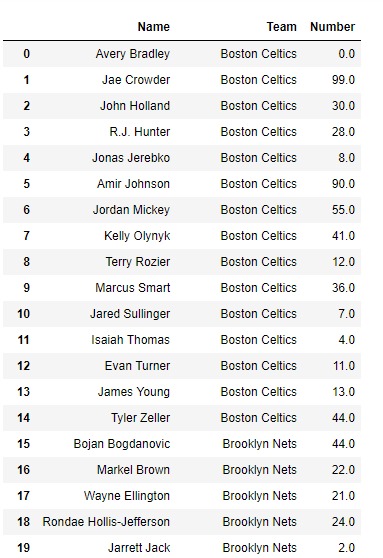
现在,我们将在列轴上的位置0、1和2处获取值。
# take values over the column axis.
df.take([0, 1, 2], axis = 1)输出:
相关用法
- Python pandas.map()用法及代码示例
- Python Pandas Timestamp.now用法及代码示例
- Python Pandas Timestamp.second用法及代码示例
- Python Pandas DataFrame.abs()用法及代码示例
- Python Pandas Series.lt()用法及代码示例
- Python Pandas dataframe.all()用法及代码示例
- Python Pandas DataFrame.ix[ ]用法及代码示例
- Python Pandas Series.pop()用法及代码示例
- Python Pandas TimedeltaIndex.max用法及代码示例
- Python Pandas Timestamp.dst用法及代码示例
- Python Pandas Timestamp.tz用法及代码示例
- Python Pandas Series.mean()用法及代码示例
- Python Pandas TimedeltaIndex.min用法及代码示例
- Python Pandas Series.ptp()用法及代码示例
- Python Pandas dataframe.cov()用法及代码示例
注:本文由纯净天空筛选整理自Shubham__Ranjan大神的英文原创作品 Python | Pandas dataframe.take()。非经特殊声明,原始代码版权归原作者所有,本译文未经允许或授权,请勿转载或复制。