
在本文中,我将讨论什么是Elasticsearch以及如何在Python中使用Elasticsearch(简称ES)。
什么是ElasticSearch?
ElasticSearch(ES)是基于Apache Lucene构建的分布式高可用开源搜索引擎。ES使用JAVA开发,可用于很多平台。ES以JSON格式存储非结构化数据,可以作为NoSQL数据库。ES不但具有NoSQL数据库特性,还提供了搜索及很多其他相关功能。
ElasticSearch用例
可以将ES用于多种用途,下面提供了其中的几个例子:
- 您正在运行的网站提供许多动态内容。无论是电子商务网站还是博客,通过部署ES,不仅可以为Web应用程序提供强大的搜索能力,还可以在应用程序中提供本机自动补全功能。
- 您可以收集不同种类的日志数据,然后借助ES查找趋势和统计数据。
设置和运行
安装ElasticSearch的最简单方法是下载它并运行可执行文件。必须确保使用的是Java 7或更高版本。
下载后,解压缩并运行其二进制文件。
elasticsearch-6.2.4 bin/elasticsearch滚动窗口中将有很多文本,如果您看到类似下面的内容,则表明启动成功。
[2018-05-27T17:36:11,744][INFO ][o.e.h.n.Netty4HttpServerTransport] [c6hEGv4] publish_address {127.0.0.1:9200}, bound_addresses {[::1]:9200}, {127.0.0.1:9200}为了进一步验证一切正常,请访问该URL:http://localhost:9200,可以在浏览器中打开或通过cURL,ES会返回以下内容。
{
"name" : "c6hEGv4",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "HkRyTYXvSkGvkvHX2Q1-oQ",
"version" : {
"number" : "6.2.4",
"build_hash" : "ccec39f",
"build_date" : "2018-04-12T20:37:28.497551Z",
"build_snapshot" : false,
"lucene_version" : "7.2.1",
"minimum_wire_compatibility_version" : "5.6.0",
"minimum_index_compatibility_version" : "5.0.0"
},
"tagline" : "You Know, for Search"
}ES提供了REST API,我们尝试使用它来执行不同的任务。
基本范例
要做的第一件事就是创建一个索引(Index)。一切都存储在索引中。 RDBMS(关系数据库管理系统)跟这里所说的索引(Index)相对应的是一个数据库。因此,请勿将这里的Index与您在RDBMS中学习的典型索引概念相混淆。这里用用PostMan运行REST API。
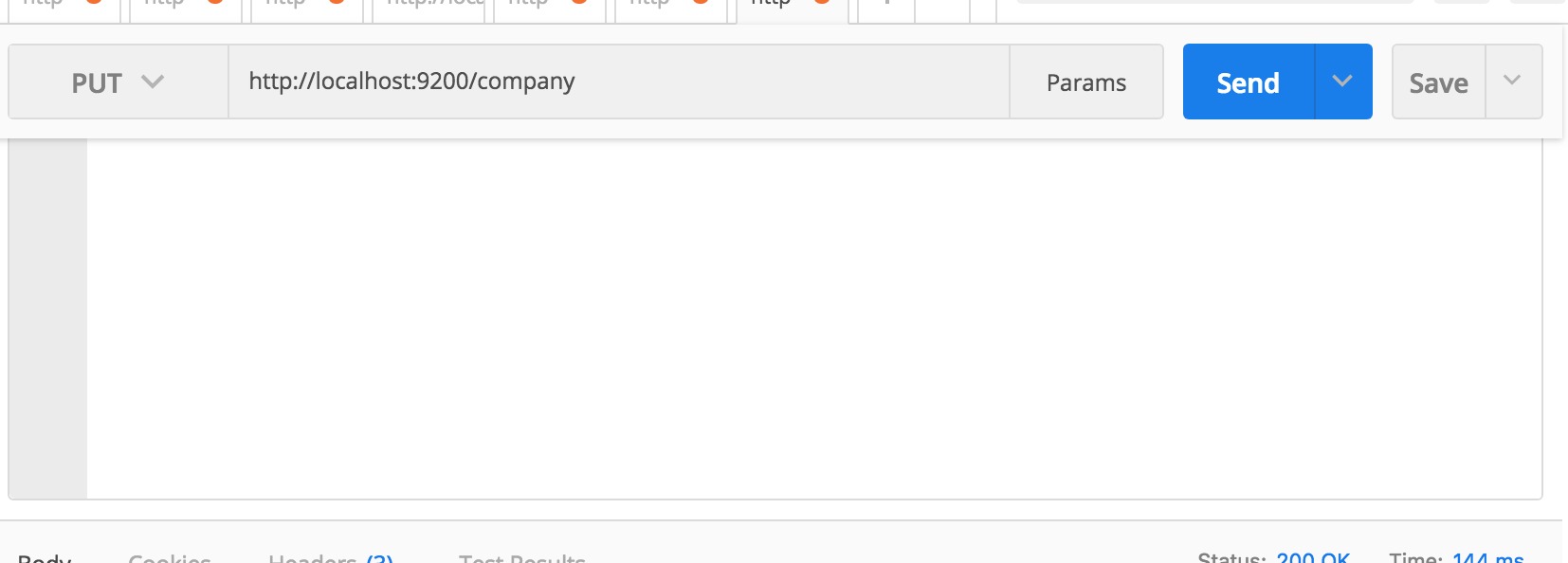
如果运行成功,您将看到如下类似的响应。
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "company"
}即,我们创建了一个数据库,名称为company。换句话说,我们创建了一个Index叫company。如果从浏览器访问http://localhost:9200/company,您将看到类似以下内容:
{
"company": {
"aliases": {
},
"mappings": {
},
"settings": {
"index": {
"creation_date": "1527638692850",
"number_of_shards": "5",
"number_of_replicas": "1",
"uuid": "RnT-gXISSxKchyowgjZOkQ",
"version": {
"created": "6020499"
},
"provided_name": "company"
}
}
}
}暂时忽略其中的mappings,这个我们稍后再讨论。creation_date是创建时间戳。number_of_shards告诉将保留此Index数据的分区数。如果您正在运行包含多个Elastic节点的集群,则整个数据将在节点之间拆分。简而言之,如果有5个分片,则整个数据可在5个分片上使用,并且ElasticSearch集群可以从它的任何节点处理请求。
number_of_replicas是指数据的镜像。如果您熟悉数据库主从(master-slave)的概念,那么这对您来说并不新鲜。可以从这里了解有关基本ES概念的更多信息。
使用cURL创建索引可以一行代码搞定:
➜ elasticsearch-6.2.4 curl -X PUT localhost:9200/company
{"acknowledged":true,"shards_acknowledged":true,"index":"company"}%您还可以一次执行索引创建和记录插入任务,要做的就是以JSON格式传递数据记录。对应的PostMan用法如下:
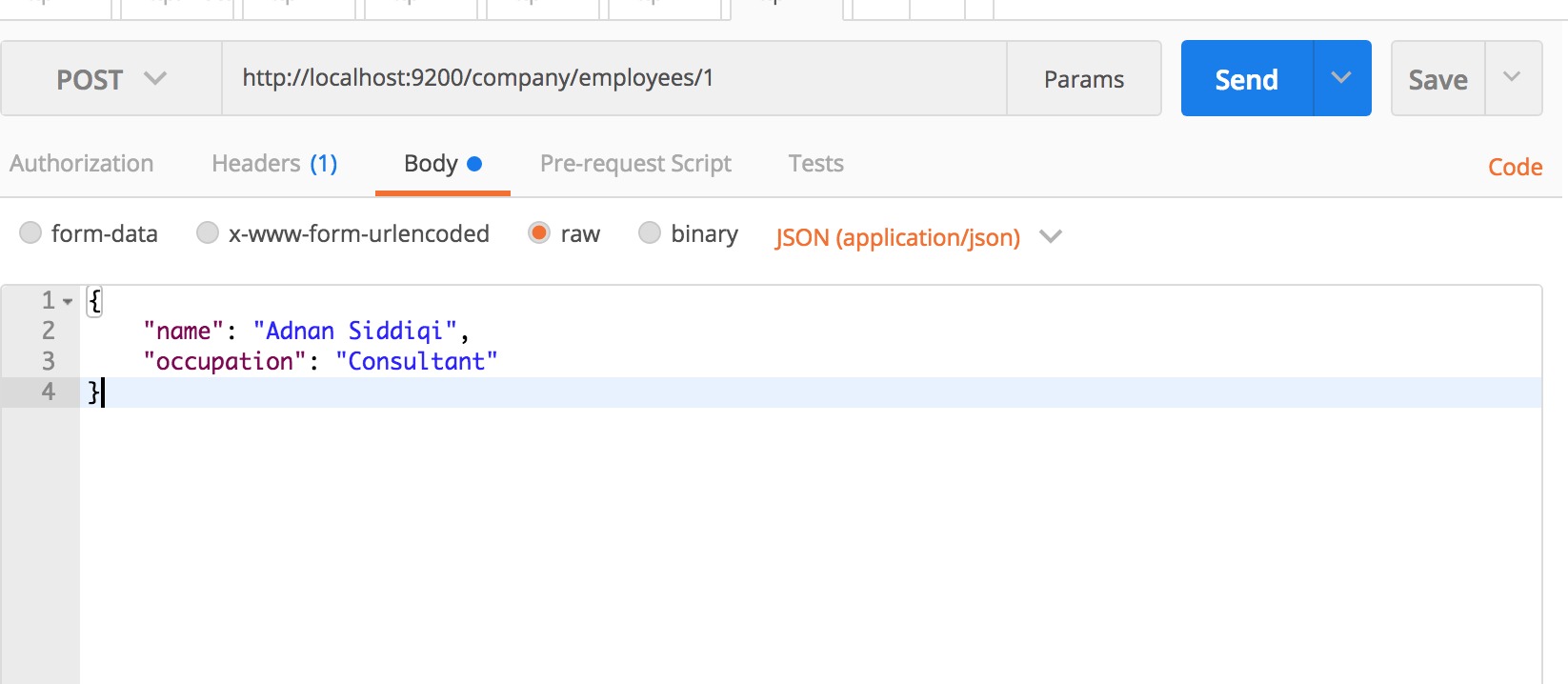
确保设置Content-Type为application/json
它将创建一个名为company的索引(如果不存在),然后创建一个新的Type(类型)叫employees。ES中的Type(类型)实际上对应在RDBMS中的Table。
上面的请求将输出以下JSON结构:
{
"_index": "company",
"_type": "employees",
"_id": "1",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 0,
"_primary_term": 1
}然后,您以JSON格式传入数据,该数据最终将作为新记录或文档插入。如果您从浏览器访问http://localhost:9200/company/employees/1,将看到以下内容。
{"_index":"company","_type":"employees","_id":"1","_version":1,"found":true,"_source":{
"name": "Adnan Siddiqi",
"occupation": "Consultant"
}}可以看到实际记录以及元数据。如果您愿意,可以将请求更改为http://localhost:9200/company/employees/1/_source则只会输出记录的JSON结构。
cURL版本为:
➜ elasticsearch-6.2.4 curl -X POST \
> http://localhost:9200/company/employees/1 \
> -H 'content-type: application/json' \
> -d '{
quote> "name": "Adnan Siddiqi",
quote> "occupation": "Consultant"
quote> }'
{"_index":"company","_type":"employees","_id":"1","_version":1,"result":"created","_shards":{"total":2,"successful":1,"failed":0},"_seq_no":0,"_primary_term":1}%如果您想更新该记录怎么办?也很简单。您要做的就是更改JSON记录。如下所示:

它将生成以下输出:
{
"_index": "company",
"_type": "employees",
"_id": "1",
"_version": 2,
"result": "updated",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}注意_result现在设置为updated(替代created)。
当然,您也可以删除某些记录。

如果要删除所有数据,可以用命令:curl -XDELETE localhost:9200/_all【谨慎操作!】。
接下来尝试一些基本的检索。如果你运行:http://localhost:9200/company/employees/_search?q=adnan,它将搜索employees类型下的所有字段并返回相关记录。
{
"took": 7,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1,
"max_score": 0.2876821,
"hits": [
{
"_index": "company",
"_type": "employees",
"_id": "1",
"_score": 0.2876821,
"_source": {
"name": "Adnan Siddiqi",
"occupation": "Software Consultant"
}
}
]
}
}max_score字段表明记录的相关性,即记录的最高分数。
您还可以通过传递字段名称来将搜索条件限制为某个字段。例如,http://localhost:9200/company/employees/_search?q=name:Adnan,将仅搜索name文档的字段。它实际上等效于SQL:SELECT * from table where name='Adnan'
ES还可以做很多事情,可以另行参考文档。这里我们切换到介绍如何使用Python访问ES。
在Python中访问ElasticSearch
老实说,ES的REST API足够好,您可以使用requests库来执行所有任务。不过,您也可以使用Python库处理ElasticSearch从而专注于您的主要任务,而不必担心如何创建请求。
通过pip安装ES,然后可以在Python程序中访问它。
pip install elasticsearch
为确保已正确安装,请从命令行运行以下基本代码段:
➜ elasticsearch-6.2.4 python
Python 3.6.4 |Anaconda custom (64-bit)| (default, Jan 16 2018, 12:04:33)
[GCC 4.2.1 Compatible Clang 4.0.1 (tags/RELEASE_401/final)] on darwin
Type "help", "copyright", "credits" or "license" for more information.
>>> from elasticsearch import Elasticsearch
>>> es = Elasticsearch([{'host': 'localhost', 'port': 9200}])
>>> es
<Elasticsearch([{'host': 'localhost', 'port': 9200}])>网页抓取和Elasticsearch
让我们讨论一下使用Elasticsearch的一些实际用例。目的是访问在线食谱并将其存储在Elasticsearch中用于搜索和分析目的。我们将首先从Allrecipes抓取数据并将其存储在ES中。要注意的是,我们需要创建一个严格的Schema或Mapping,以确保以正确的格式和类型对数据进行索引。具体步骤如下:
抓取数据
import json from time import sleepimport requests from bs4 import BeautifulSoupdef parse(u): title = '-' submit_by = '-' description = '-' calories = 0 ingredients = [] rec = {}try: r = requests.get(u, headers=headers)if r.status_code == 200: html = r.text soup = BeautifulSoup(html, 'lxml') # title title_section = soup.select('.recipe-summary__h1') # submitter submitter_section = soup.select('.submitter__name') # description description_section = soup.select('.submitter__description') # ingredients ingredients_section = soup.select('.recipe-ingred_txt')# calories calories_section = soup.select('.calorie-count') if calories_section: calories = calories_section[0].text.replace('cals', '').strip()if ingredients_section: for ingredient in ingredients_section: ingredient_text = ingredient.text.strip() if 'Add all ingredients to list' not in ingredient_text and ingredient_text != '': ingredients.append({'step': ingredient.text.strip()})if description_section: description = description_section[0].text.strip().replace('"', '')if submitter_section: submit_by = submitter_section[0].text.strip()if title_section: title = title_section[0].textrec = {'title': title, 'submitter': submit_by, 'description': description, 'calories': calories, 'ingredients': ingredients} except Exception as ex: print('Exception while parsing') print(str(ex)) finally: return json.dumps(rec)if __name__ == '__main__': headers = { 'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.181 Safari/537.36', 'Pragma': 'no-cache' } url = 'https://www.allrecipes.com/recipes/96/salad/' r = requests.get(url, headers=headers) if r.status_code == 200: html = r.text soup = BeautifulSoup(html, 'lxml') links = soup.select('.fixed-recipe-card__h3 a') for link in links: sleep(2) result = parse(link['href']) print(result) print('=================================')
以上是提取数据的基本程序。由于需要JSON格式的数据,因此我进行了相应的转换。
创建索引
有了所需的数据之后,接下来考虑如何存储。我们要做的第一件事就是创建Index(索引)。将索引命名为recipes,Type为salads。要做的另一件事是给文档结构创建一个 mapping(映射)。
在创建索引之前,我们必须连接ElasticSearch服务器。
import logging def connect_elasticsearch(): _es = None _es = Elasticsearch([{'host': 'localhost', 'port': 9200}]) if _es.ping(): print('Yay Connect') else: print('Awww it could not connect!') return _esif __name__ == '__main__': logging.basicConfig(level=logging.ERROR)
其中_es.ping()对服务器发送ping请求,如果连接上的话返回True。
def create_index(es_object, index_name='recipes'):
created = False
# index settings
settings = {
"settings": {
"number_of_shards": 1,
"number_of_replicas": 0
},
"mappings": {
"members": {
"dynamic": "strict",
"properties": {
"title": {
"type": "text"
},
"submitter": {
"type": "text"
},
"description": {
"type": "text"
},
"calories": {
"type": "integer"
},
}
}
}
}
try:
if not es_object.indices.exists(index_name):
# Ignore 400 means to ignore "Index Already Exist" error.
es_object.indices.create(index=index_name, ignore=400, body=settings)
print('Created Index')
created = True
except Exception as ex:
print(str(ex))
finally:
return created对上面的代码做个简要说明:
首先,我们传递了一个config变量,其中包含整个文档结构的映射。Mapping是Elastic的Schema术语。就像我们在数据库Table表中设置某些字段数据类型一样,我们在这里做类似的事情。除了calories是Integer之外,所有其他字段均为text类型。
然后,我要确保索引根本不存在,然后再创建它。参数ignore=400在检查之后不再需要它,但是如果您不检查是否存在,则可以抑制该错误并覆盖现有索引。不过这有风险,就像覆盖数据库一样。
如果索引创建成功,则可以通过访问http://localhost:9200/recipes/_mappings 进行验证,它将打印如下内容:
{
"recipes": {
"mappings": {
"salads": {
"dynamic": "strict",
"properties": {
"calories": {
"type": "integer"
},
"description": {
"type": "text"
},
"submitter": {
"type": "text"
},
"title": {
"type": "text"
}
}
}
}
}
}通过传入dynamic:strict,我们强迫Elasticsearch对所有传入文档进行严格检查。这里,salads实际上是文档类型。
存入索引
下一步是存储实际数据或文档。
def store_record(elastic_object, index_name, record):
try:
outcome = elastic_object.index(index=index_name, doc_type='salads', body=record)
except Exception as ex:
print('Error in indexing data')
print(str(ex))运行它,您将看到以下输出:
Error in indexing data
TransportError(400, 'strict_dynamic_mapping_exception', 'mapping set to strict, dynamic introduction of [ingredients] within [salads] is not allowed')你能猜出为什么会这样吗?由于在我们的映射中没有设置ingredients,ES不允许我们存储包含ingredients字段的文档。现在,我们认识到了Mapping的好处,它可以避免破坏数据。现在,让我们对映射进行一些更改,如下所示:
"mappings": {
"salads": {
"dynamic": "strict",
"properties": {
"title": {
"type": "text"
},
"submitter": {
"type": "text"
},
"description": {
"type": "text"
},
"calories": {
"type": "integer"
},
"ingredients": {
"type": "nested",
"properties": {
"step": {"type": "text"}
}
},
}
}
}我们在Mapping中增加了ingrdients,其类型为nested。然后设置了其内部字段的数据类型,也就是text
nested数据类型让您设置嵌套JSON对象的类型。再次运行它,将会看到以下输出:
{
'_index': 'recipes',
'_type': 'salads',
'_id': 'OvL7s2MBaBpTDjqIPY4m',
'_version': 1,
'result': 'created',
'_shards': {
'total': 1,
'successful': 1,
'failed': 0
},
'_seq_no': 0,
'_primary_term': 1
}由于您没有通过_id设置文档ID,ES为存储的文档分配了动态ID。我在Chrome浏览器中使用ES数据查看器查看数据,它的工具名为ElasticSearch工具箱。
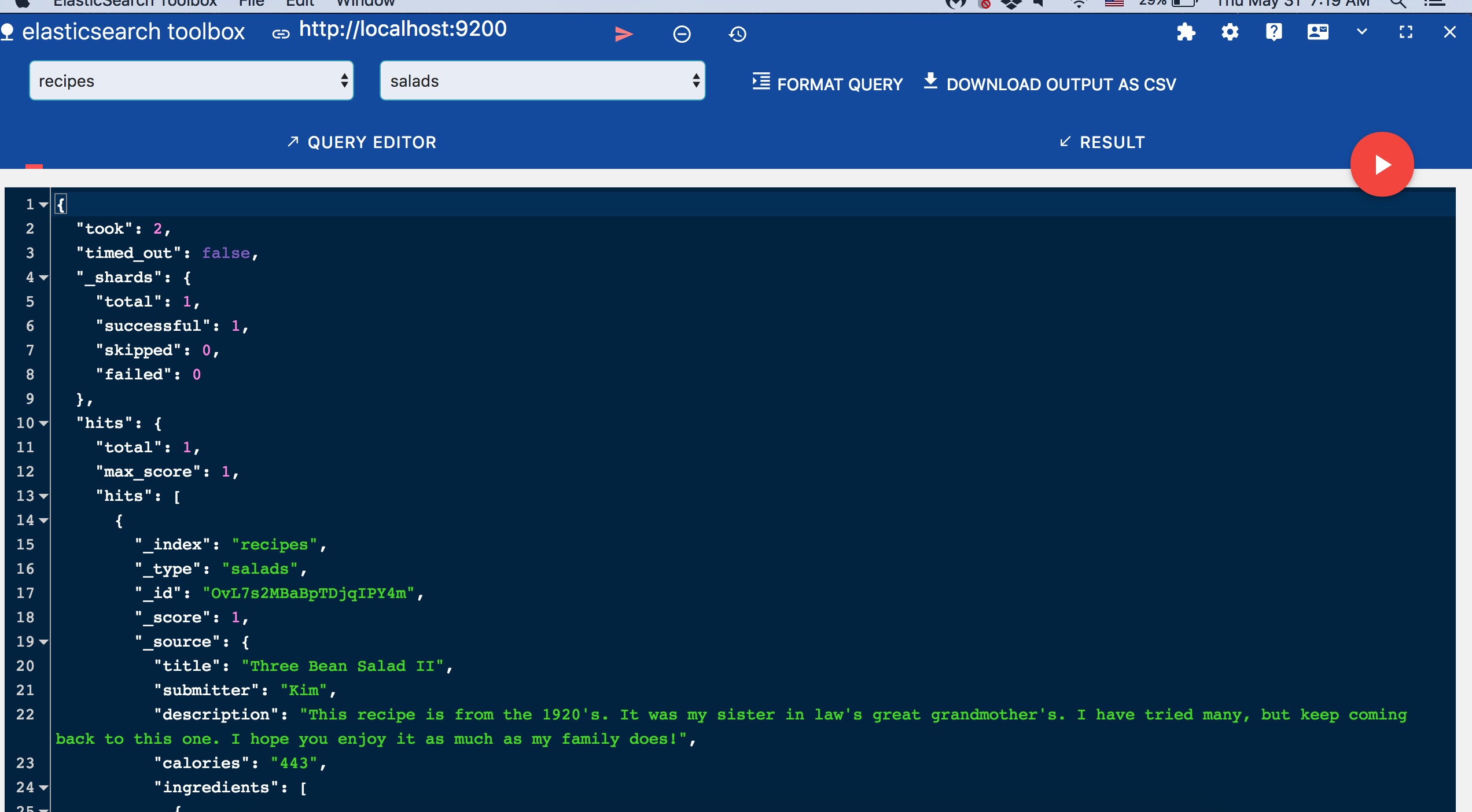
在继续之前,我们先存储一个字符串给calories字段,看看情况如何。(记住我们已经将calories设置为integer类型)。结果会出现以下错误:
TransportError(400, 'mapper_parsing_exception', 'failed to parse [calories]')
现在我们进一步了解到为文档设置Mapping的好处。当然,如果您不这样做也可以,因为Elasticsearch将在运行时自动进行基本的默认映射。
查询记录
建好索引之后,可以根据需要进行查询。我要创建一个名为search()的函数,它将显示查询结果。
def search(es_object, index_name, search):
res = es_object.search(index=index_name, body=search)这让我们尝试一些查询。
if __name__ == '__main__':
es = connect_elasticsearch()
if es is not None:
search_object = {'query': {'match': {'calories': '102'}}}
search(es, 'recipes', json.dumps(search_object))上面的查询将返回其中calories等于102的所有记录。在我们的例子中,输出为:
{'_shards': {'failed': 0, 'skipped': 0, 'successful': 1, 'total': 1},
'hits': {'hits': [{'_id': 'YkTAuGMBzBKRviZYEDdu',
'_index': 'recipes',
'_score': 1.0,
'_source': {'calories': '102',
'description': "I've been making variations of "
'this salad for years. I '
'recently learned how to '
'massage the kale and it makes '
'a huge difference. I had a '
'friend ask for my recipe and I '
"realized I don't have one. "
'This is my first attempt at '
'writing a recipe, so please '
'let me know how it works out! '
'I like to change up the '
'ingredients: sometimes a pear '
'instead of an apple, '
'cranberries instead of '
'currants, Parmesan instead of '
'feta, etc. Great as a side '
'dish or by itself the next day '
'for lunch!',
'ingredients': [{'step': '1 bunch kale, large '
'stems discarded, '
'leaves finely '
'chopped'},
{'step': '1/2 teaspoon salt'},
{'step': '1 tablespoon apple '
'cider vinegar'},
{'step': '1 apple, diced'},
{'step': '1/3 cup feta cheese'},
{'step': '1/4 cup currants'},
{'step': '1/4 cup toasted pine '
'nuts'}],
'submitter': 'Leslie',
'title': 'Kale and Feta Salad'},
'_type': 'salads'}],
'max_score': 1.0,
'total': 1},
'timed_out': False,
'took': 2}如果您想在其中获取calories大于20的记录怎么办?
search_object = {'_source': ['title'], 'query': {'range': {'calories': {'gte': 20}}}}
您还可以指定要返回的列或字段。上面的查询将返回所有calories大于20的记录。
结论
Elasticsearch是一个功能强大的工具,能够为各种应用提供丰富准确的查询功能。我们刚刚介绍了要点,可以进一步阅读文档来熟悉这个工具。特别是模糊搜索功能非常出色。如果有机会,我将在以后的文章中介绍Query DSL。
注:本文代码可以在Github找到。
本文最初发表于这里。