
使用神经网络(NN)预测市场上的股票价格走势的想法与NN一样古老。凭直觉,仅凭过去就很难预测未来的价格走势。如何使用LSTM预测成交量加权平均价格,这是一个既有挑战性又很有趣的问题。
本文将使用PyTorch训练有关比特币交易数据的Long Short Term Memory Neural Network(LSTM, 长短记忆神经网络),并使用它预测看不见的交易数据的价格。
加载必要的依赖项
我们首先导入将用于数据处理、可视化、训练模型等相关的库。我们将使用PyTorch库训练LSTM。
%matplotlib inline
import glob
import matplotlib
import numpy as np
import pandas as pd
import sklearn
import torch加载数据
我们将分析来自BitMex的XBTUSD交易数据。每日数据文件可从下载公开获取(无需编写代码即可自动下载数据,只需单击几次即可下载文件)。
列出所有文件,将它们读取到pandas DataFrame并通过XBTUSD符号过滤交易数据。请务必按时间戳对DataFrame进行排序,因为有多个文件,以免混淆。
files = sorted(glob.glob('data/*.csv.gz'))
df = pd.concat(map(pd.read_csv, files))
df = df[df.symbol == 'XBTUSD']
df.timestamp = pd.to_datetime(df.timestamp.str.replace('D', 'T')) # covert to timestamp type
df = df.sort_values('timestamp')
df.set_index('timestamp', inplace=True) # set index to timestamp
df.head()
每行代表一项交易,字段说明如下:
- timestamp, 时间戳(以微秒为单位),
- symbol, 交易合约符号,
- side, 买卖双方,
- size, 代表合约数量(交易的美元数量),
- price, 合同价格,
- tickDirection, 描述自上次交易以来价格的增/减,
- trdMatchID, 是唯一的交易ID,
- grossValue, 是交换的比特币satoshis的数量,
- homeNotional, 是交易中XBT的金额,
- foreignNotional, 是交易中的美元金额。
我们将使用其中3列:timestamp、price和foreignNotional。
数据预处理
计算每1分钟的时间间隔内成交量加权平均价(VWAP)。我们按照预定义的时间间隔对交易进行分组的数据表示形式称为时间条(Time Bar)。
备注:这是代表用于建模的贸易数据的最佳方法吗?根据洛佩兹·德普拉多(Lopez de Prado)的说法,市场上的交易不会随着时间的推移而均匀分布。有一些活动活跃的时期(例如,刚好在合约到期之前),以预定义的时间间隔对数据进行分组会在某些时间范围内对数据进行过采样,而在其他时间范围内则对数据进行欠采样。
df_vwap = df.groupby(pd.Grouper(freq="1Min")).apply(
lambda row: pd.np.sum(row.price * row.foreignNotional) / pd.np.sum(row.foreignNotional))
该图显示了从2019年8月1日到2019年9月17日的带有VWAP的时间条。我们将使用数据的第一部分作为训练集,将中间部分作为验证集,并将数据的最后一部分作为测试集。 (其中垂直线是三部分定界符)。可以观察到VWAP的波动性很明显,价格在8月上旬达到了高点,在8月底达到了低点。最高和最低是在训练集中捕获的,这一点很重要,因为该模型很可能在看不见的VWAP间隔内无法很好地工作。
标准化数据
为了帮助LSTM模型更快收敛,标准化数据非常重要。输入中的较大值可能会减慢学习速度。我们将使用sklearn库中的StandardScaler来缩放标准化数据。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
train_arr = scaler.fit_transform(df_train)
val_arr = scaler.transform(df_val)
test_arr = scaler.transform(df_test)转换数据
标准化之后,我们需要将数据转换为适合LSTM建模的格式。我们将较长的数据序列转换为许多较短的序列(每个序列100个时间条)。
from torch.autograd import Variable
def transform_data(arr, seq_len):
x, y = [], []
for i in range(len(arr) - seq_len):
x_i = arr[i : i + seq_len]
y_i = arr[i + 1 : i + seq_len + 1]
x.append(x_i)
y.append(y_i)
x_arr = np.array(x).reshape(-1, seq_len)
y_arr = np.array(y).reshape(-1, seq_len)
x_var = Variable(torch.from_numpy(x_arr).float())
y_var = Variable(torch.from_numpy(y_arr).float())
return x_var, y_var
seq_len = 100
x_train, y_train = transform_data(train_arr, seq_len)
x_val, y_val = transform_data(val_arr, seq_len)
x_test, y_test = transform_data(test_arr, seq_len)下图显示了训练集中的第一序列和第二序列。两个序列的长度均为100个时间条。我们可以观察到两个序列的目标与特征几乎相同,不同之处在于第一个和最后一个时间条。

LSTM在训练阶段如何使用序列?
首先来看第一个序列。该模型采用索引为0的时间条的特征,并尝试预测索引1的时间条的目标。然后,模型采用索引为1的时间条的特征,并尝试预测索引2处时间条的目标。第二个序列的特征比第一个序列的特征偏移了1个时间条,第3个序列的特征从第2个序列的特征偏移了1个时间条,以此类推。即按单个时间条移动。
请注意,在分类或回归任务中,我们通常具有一组要尝试预测的特征和目标。在使用LSTM的此示例中,特征和目标来自同一序列,唯一的区别是目标移动了1个时间栏。
长短期记忆神经网络(LSTM)
LSTM是递归神经网络(RNN)的一种。 RNN使用以前的时间事件来预知后面的事件。例如,为了对电影中要发生的事件进行分类,模型需要使用有关先前事件的信息。如果问题仅需要最新信息来执行当前任务,则RNN会很好地工作。如果问题需要长期依赖,RNN将很难对其进行建模。 LSTM旨在学习长期依赖关系。它会长时间记住该信息。 LSTM由S Hochreiter,J施密德湖伯在1997年引入。要了解有关LSTM的更多信息,请阅读科拉博客文章,这里提供了很好的解释。
以下代码是用于时间序列预测的有状态LSTM的实现。它具有LSTMCell单元和线性层,可对时间序列进行建模。该模型可以生成时间序列的未来值,并且可以使用teacher forcing方法(将在稍后描述的概念)对其进行训练。
import torch.nn as nn
import torch.optim as optim
class Model(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(Model, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.lstm = nn.LSTMCell(self.input_size, self.hidden_size)
self.linear = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input, future=0, y=None):
outputs = []
# reset the state of LSTM
# the state is kept till the end of the sequence
h_t = torch.zeros(input.size(0), self.hidden_size, dtype=torch.float32)
c_t = torch.zeros(input.size(0), self.hidden_size, dtype=torch.float32)
for i, input_t in enumerate(input.chunk(input.size(1), dim=1)):
h_t, c_t = self.lstm(input_t, (h_t, c_t))
output = self.linear(h_t)
outputs += [output]
for i in range(future):
if y is not None and random.random() > 0.5:
output = y[:, [i]] # teacher forcing
h_t, c_t = self.lstm(output, (h_t, c_t))
output = self.linear(h_t)
outputs += [output]
outputs = torch.stack(outputs, 1).squeeze(2)
return outputs训练LSTM
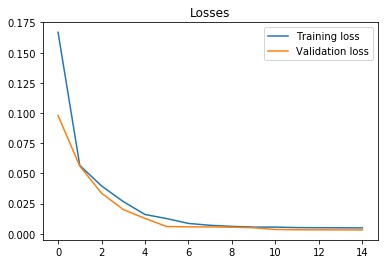
我们用21个隐藏单元训练LSTM。使用的单元数较少,因此LSTM不太可能完美记住该序列。我们使用均方误差损失函数和Adam优化器。学习率设置为0.001,并且每5轮(epochs)衰减一次。我们以每批100个序列的方式训练模型,供使用15轮(epochs)。从下面的图中可以看出,训练和验证损失在第六个epoch后收敛。
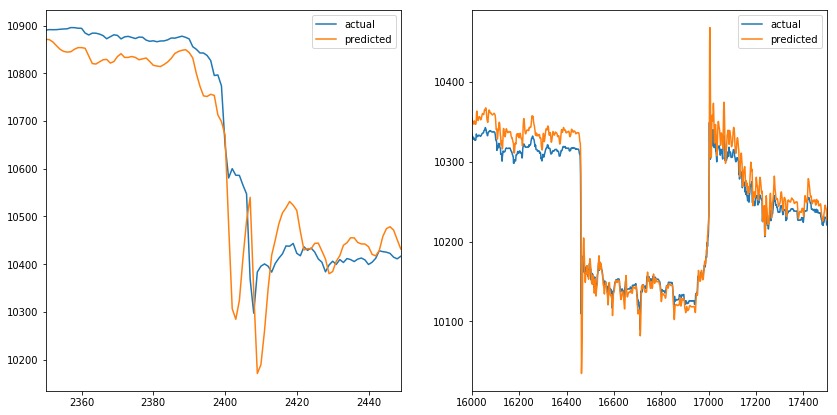
让我们在测试集中评估模型。 future参数设置为5,这意味着该模型预测接下来的5个时间条(在我们的示例中为5分钟)输出VWAP。
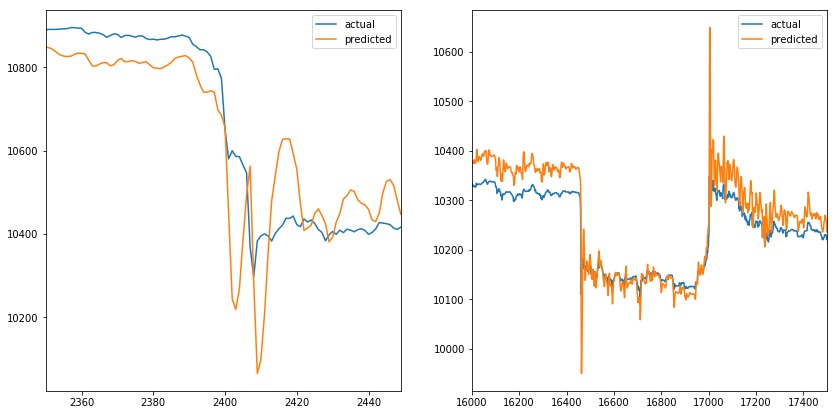
在下图中,我们可以看到预测值与VWAP的实际值非常匹配,乍一看似乎很棒。但是future参数设置为5,这意味着橙色线应该在出现尖峰之前做出反应,而不是覆盖它。

当我们放大峰值时(一个在时间序列的开始,另一个在时间序列的结束)。我们可以观察到预测值模拟实际值。当实际值改变方向时,预测值伴随做相应改变。当我们增加future参数时,也会发生同样的情况(例如,它不会影响预测线)。
让我们为模型的第一个测试序列生成1000个时间条,并比较预测的、生成的和实际的VWAP。我们可以观察到,虽然模型输出的是预测值,但它们接近实际值。而对于生成值时,其输出几乎类似于正弦波。在特定时间段后,值收敛到9600。
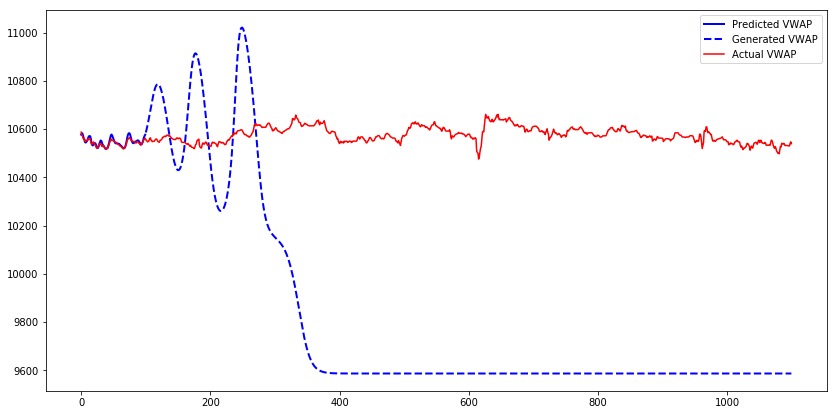
发生这种现象的原因是,仅使用真实输入而不使用生成的输入来训练模型。当模型从生成的输出获取输入时,它在生成下一个值方面做得很差。Teacher forcing是一个解决此问题的概念。
Teacher forcing[强制教学]
Teacher forcing是一种训练递归神经网络的方法,该方法将前一时间步长的输出用作输入。训练RNN后,它可以通过使用先前的输出作为当前输入来生成序列。训练期间可以使用相同的过程,但是模型可能变得不稳定或无法收敛。Teacher forcing是一种在训练过程中解决这些问题的方法。它通常在语言模型中使用。
我们将使用Teacher forcing的扩展,称为预定采样。在训练期间,模型将以一定的概率将其生成的输出用作输入。初始阶段,模型看到其生成的输出的可能性很小,然后在训练过程中逐渐增加。请注意,在本示例中,我们使用了随机概率,该概率在训练过程中不会增加。
接下来训练一个模型,该模型具有与以前相同的参数,但启用了Teacher forcing。 7个epochs后,训练和验证损失会收敛。
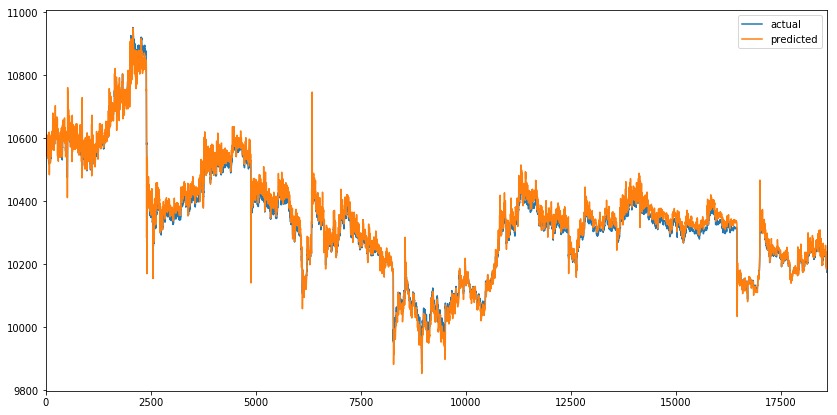
我们可以观察到与以前相似的预测序列。当我们放大峰值时,可以观察到模型的类似行为,其中预测值模拟实际值。Teacher forcing似乎并没有解决问题。
让我们使用具有Teacher forcing训练的模型为第一个测试序列生成1000个时间条。
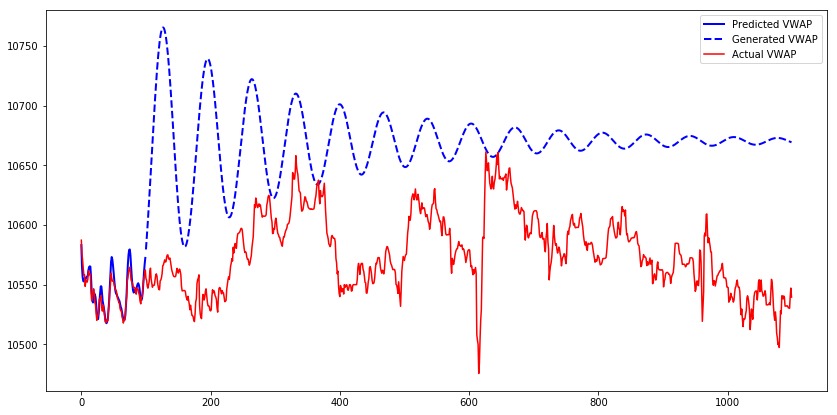
由具有Teacher forcing训练的模型生成的序列需要更长的时间收敛。关于生成的序列的另一个观察结果是,当序列增加时,它将继续增加到某个点,然后开始减少,并且模式会重复直到序列收敛为止。图案看起来像正弦波,其幅度逐渐减小。
结论
该实验的结果是模型的预测模拟了序列的实际值。第一和第二个模型不会在价格变化发生之前就对其进行检测。添加另一个特征(例如数量volume)可能有助于模型在价格变化发生之前检测出来,但是模型将需要生成两个特征,以将这些输出用作下一步的输入,这会使模型变得复杂。使用更复杂的模型(多个LSTMCells,增加隐藏单元的数量)可能无济于事,因为该模型已经具有预测VWAP时间序列的能力,如上图所示。Teacher forcing 的更高级方法可能会有所帮助,它能使模型提高序列生成技能。