
使用神經網絡(NN)預測市場上的股票價格走勢的想法與NN一樣古老。憑直覺,僅憑過去就很難預測未來的價格走勢。如何使用LSTM預測成交量加權平均價格,這是一個既有挑戰性又很有趣的問題。
本文將使用PyTorch訓練有關比特幣交易數據的Long Short Term Memory Neural Network(LSTM, 長短記憶神經網絡),並使用它預測看不見的交易數據的價格。
加載必要的依賴項
我們首先導入將用於數據處理、可視化、訓練模型等相關的庫。我們將使用PyTorch庫訓練LSTM。
%matplotlib inline
import glob
import matplotlib
import numpy as np
import pandas as pd
import sklearn
import torch加載數據
我們將分析來自BitMex的XBTUSD交易數據。每日數據文件可從下載公開獲取(無需編寫代碼即可自動下載數據,隻需單擊幾次即可下載文件)。
列出所有文件,將它們讀取到pandas DataFrame並通過XBTUSD符號過濾交易數據。請務必按時間戳對DataFrame進行排序,因為有多個文件,以免混淆。
files = sorted(glob.glob('data/*.csv.gz'))
df = pd.concat(map(pd.read_csv, files))
df = df[df.symbol == 'XBTUSD']
df.timestamp = pd.to_datetime(df.timestamp.str.replace('D', 'T')) # covert to timestamp type
df = df.sort_values('timestamp')
df.set_index('timestamp', inplace=True) # set index to timestamp
df.head()
每行代表一項交易,字段說明如下:
- timestamp, 時間戳(以微秒為單位),
- symbol, 交易合約符號,
- side, 買賣雙方,
- size, 代表合約數量(交易的美元數量),
- price, 合同價格,
- tickDirection, 描述自上次交易以來價格的增/減,
- trdMatchID, 是唯一的交易ID,
- grossValue, 是交換的比特幣satoshis的數量,
- homeNotional, 是交易中XBT的金額,
- foreignNotional, 是交易中的美元金額。
我們將使用其中3列:timestamp、price和foreignNotional。
數據預處理
計算每1分鍾的時間間隔內成交量加權平均價(VWAP)。我們按照預定義的時間間隔對交易進行分組的數據表示形式稱為時間條(Time Bar)。
備注:這是代表用於建模的貿易數據的最佳方法嗎?根據洛佩茲·德普拉多(Lopez de Prado)的說法,市場上的交易不會隨著時間的推移而均勻分布。有一些活動活躍的時期(例如,剛好在合約到期之前),以預定義的時間間隔對數據進行分組會在某些時間範圍內對數據進行過采樣,而在其他時間範圍內則對數據進行欠采樣。
df_vwap = df.groupby(pd.Grouper(freq="1Min")).apply(
lambda row: pd.np.sum(row.price * row.foreignNotional) / pd.np.sum(row.foreignNotional))
該圖顯示了從2019年8月1日到2019年9月17日的帶有VWAP的時間條。我們將使用數據的第一部分作為訓練集,將中間部分作為驗證集,並將數據的最後一部分作為測試集。 (其中垂直線是三部分定界符)。可以觀察到VWAP的波動性很明顯,價格在8月上旬達到了高點,在8月底達到了低點。最高和最低是在訓練集中捕獲的,這一點很重要,因為該模型很可能在看不見的VWAP間隔內無法很好地工作。
標準化數據
為了幫助LSTM模型更快收斂,標準化數據非常重要。輸入中的較大值可能會減慢學習速度。我們將使用sklearn庫中的StandardScaler來縮放標準化數據。
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
train_arr = scaler.fit_transform(df_train)
val_arr = scaler.transform(df_val)
test_arr = scaler.transform(df_test)轉換數據
標準化之後,我們需要將數據轉換為適合LSTM建模的格式。我們將較長的數據序列轉換為許多較短的序列(每個序列100個時間條)。
from torch.autograd import Variable
def transform_data(arr, seq_len):
x, y = [], []
for i in range(len(arr) - seq_len):
x_i = arr[i : i + seq_len]
y_i = arr[i + 1 : i + seq_len + 1]
x.append(x_i)
y.append(y_i)
x_arr = np.array(x).reshape(-1, seq_len)
y_arr = np.array(y).reshape(-1, seq_len)
x_var = Variable(torch.from_numpy(x_arr).float())
y_var = Variable(torch.from_numpy(y_arr).float())
return x_var, y_var
seq_len = 100
x_train, y_train = transform_data(train_arr, seq_len)
x_val, y_val = transform_data(val_arr, seq_len)
x_test, y_test = transform_data(test_arr, seq_len)下圖顯示了訓練集中的第一序列和第二序列。兩個序列的長度均為100個時間條。我們可以觀察到兩個序列的目標與特征幾乎相同,不同之處在於第一個和最後一個時間條。

LSTM在訓練階段如何使用序列?
首先來看第一個序列。該模型采用索引為0的時間條的特征,並嘗試預測索引1的時間條的目標。然後,模型采用索引為1的時間條的特征,並嘗試預測索引2處時間條的目標。第二個序列的特征比第一個序列的特征偏移了1個時間條,第3個序列的特征從第2個序列的特征偏移了1個時間條,以此類推。即按單個時間條移動。
請注意,在分類或回歸任務中,我們通常具有一組要嘗試預測的特征和目標。在使用LSTM的此示例中,特征和目標來自同一序列,唯一的區別是目標移動了1個時間欄。
長短期記憶神經網絡(LSTM)
LSTM是遞歸神經網絡(RNN)的一種。 RNN使用以前的時間事件來預知後麵的事件。例如,為了對電影中要發生的事件進行分類,模型需要使用有關先前事件的信息。如果問題僅需要最新信息來執行當前任務,則RNN會很好地工作。如果問題需要長期依賴,RNN將很難對其進行建模。 LSTM旨在學習長期依賴關係。它會長時間記住該信息。 LSTM由S Hochreiter,J施密德湖伯在1997年引入。要了解有關LSTM的更多信息,請閱讀科拉博客文章,這裏提供了很好的解釋。
以下代碼是用於時間序列預測的有狀態LSTM的實現。它具有LSTMCell單元和線性層,可對時間序列進行建模。該模型可以生成時間序列的未來值,並且可以使用teacher forcing方法(將在稍後描述的概念)對其進行訓練。
import torch.nn as nn
import torch.optim as optim
class Model(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(Model, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.lstm = nn.LSTMCell(self.input_size, self.hidden_size)
self.linear = nn.Linear(self.hidden_size, self.output_size)
def forward(self, input, future=0, y=None):
outputs = []
# reset the state of LSTM
# the state is kept till the end of the sequence
h_t = torch.zeros(input.size(0), self.hidden_size, dtype=torch.float32)
c_t = torch.zeros(input.size(0), self.hidden_size, dtype=torch.float32)
for i, input_t in enumerate(input.chunk(input.size(1), dim=1)):
h_t, c_t = self.lstm(input_t, (h_t, c_t))
output = self.linear(h_t)
outputs += [output]
for i in range(future):
if y is not None and random.random() > 0.5:
output = y[:, [i]] # teacher forcing
h_t, c_t = self.lstm(output, (h_t, c_t))
output = self.linear(h_t)
outputs += [output]
outputs = torch.stack(outputs, 1).squeeze(2)
return outputs訓練LSTM
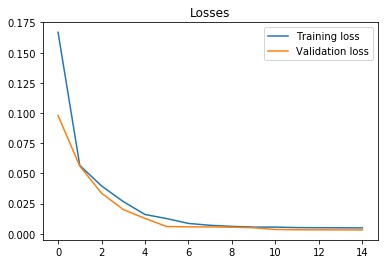
我們用21個隱藏單元訓練LSTM。使用的單元數較少,因此LSTM不太可能完美記住該序列。我們使用均方誤差損失函數和Adam優化器。學習率設置為0.001,並且每5輪(epochs)衰減一次。我們以每批100個序列的方式訓練模型,供使用15輪(epochs)。從下麵的圖中可以看出,訓練和驗證損失在第六個epoch後收斂。
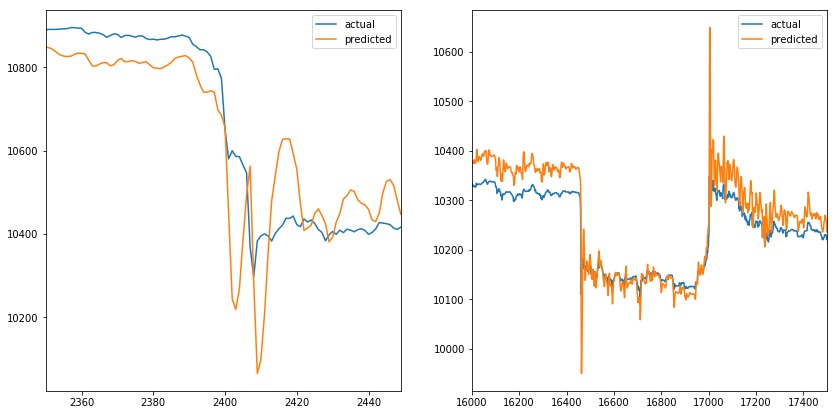
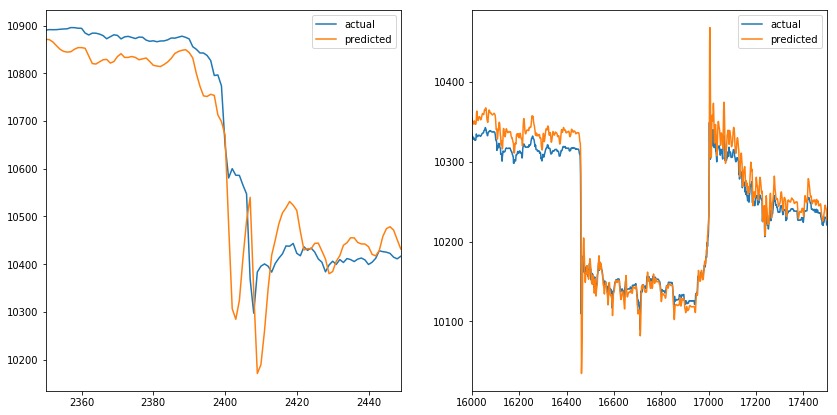
讓我們在測試集中評估模型。 future參數設置為5,這意味著該模型預測接下來的5個時間條(在我們的示例中為5分鍾)輸出VWAP。
在下圖中,我們可以看到預測值與VWAP的實際值非常匹配,乍一看似乎很棒。但是future參數設置為5,這意味著橙色線應該在出現尖峰之前做出反應,而不是覆蓋它。

當我們放大峰值時(一個在時間序列的開始,另一個在時間序列的結束)。我們可以觀察到預測值模擬實際值。當實際值改變方向時,預測值伴隨做相應改變。當我們增加future參數時,也會發生同樣的情況(例如,它不會影響預測線)。
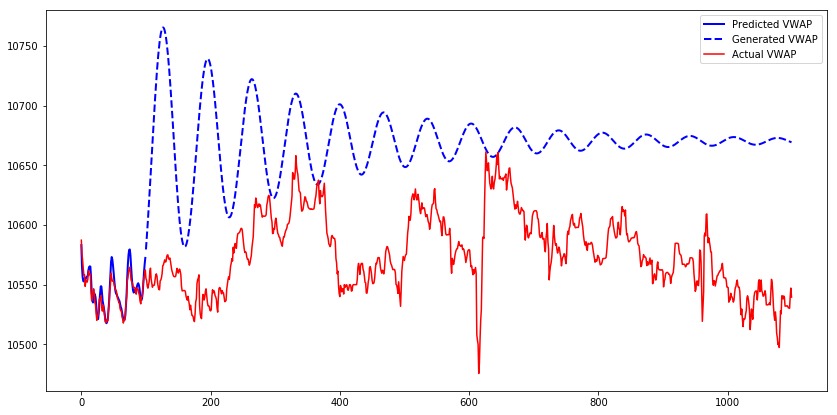
讓我們為模型的第一個測試序列生成1000個時間條,並比較預測的、生成的和實際的VWAP。我們可以觀察到,雖然模型輸出的是預測值,但它們接近實際值。而對於生成值時,其輸出幾乎類似於正弦波。在特定時間段後,值收斂到9600。
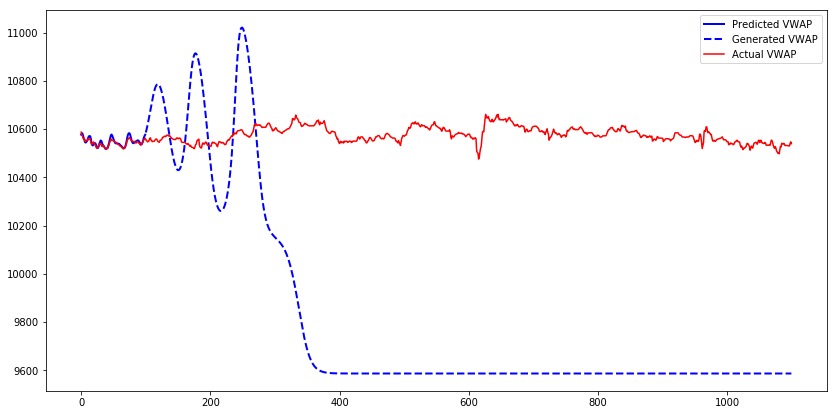
發生這種現象的原因是,僅使用真實輸入而不使用生成的輸入來訓練模型。當模型從生成的輸出獲取輸入時,它在生成下一個值方麵做得很差。Teacher forcing是一個解決此問題的概念。
Teacher forcing[強製教學]
Teacher forcing是一種訓練遞歸神經網絡的方法,該方法將前一時間步長的輸出用作輸入。訓練RNN後,它可以通過使用先前的輸出作為當前輸入來生成序列。訓練期間可以使用相同的過程,但是模型可能變得不穩定或無法收斂。Teacher forcing是一種在訓練過程中解決這些問題的方法。它通常在語言模型中使用。
我們將使用Teacher forcing的擴展,稱為預定采樣。在訓練期間,模型將以一定的概率將其生成的輸出用作輸入。初始階段,模型看到其生成的輸出的可能性很小,然後在訓練過程中逐漸增加。請注意,在本示例中,我們使用了隨機概率,該概率在訓練過程中不會增加。
接下來訓練一個模型,該模型具有與以前相同的參數,但啟用了Teacher forcing。 7個epochs後,訓練和驗證損失會收斂。
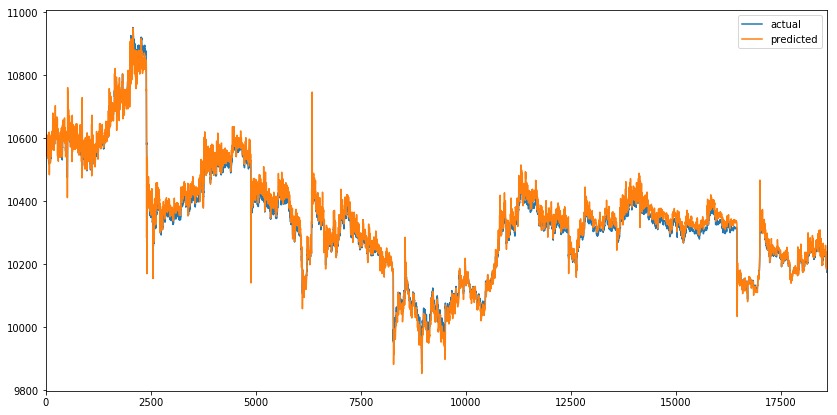
我們可以觀察到與以前相似的預測序列。當我們放大峰值時,可以觀察到模型的類似行為,其中預測值模擬實際值。Teacher forcing似乎並沒有解決問題。
讓我們使用具有Teacher forcing訓練的模型為第一個測試序列生成1000個時間條。
由具有Teacher forcing訓練的模型生成的序列需要更長的時間收斂。關於生成的序列的另一個觀察結果是,當序列增加時,它將繼續增加到某個點,然後開始減少,並且模式會重複直到序列收斂為止。圖案看起來像正弦波,其幅度逐漸減小。
結論
該實驗的結果是模型的預測模擬了序列的實際值。第一和第二個模型不會在價格變化發生之前就對其進行檢測。添加另一個特征(例如數量volume)可能有助於模型在價格變化發生之前檢測出來,但是模型將需要生成兩個特征,以將這些輸出用作下一步的輸入,這會使模型變得複雜。使用更複雜的模型(多個LSTMCells,增加隱藏單元的數量)可能無濟於事,因為該模型已經具有預測VWAP時間序列的能力,如上圖所示。Teacher forcing 的更高級方法可能會有所幫助,它能使模型提高序列生成技能。