多标签分类数据及可视化说明
本示例模拟多标签(multi-label)文档分类问题。模拟数据集是根据以下过程随机生成的:
- 选择标签数:n〜Poisson(n_labels) ,即n采样自泊松分布。
- n次,每次选择一个类c:c〜多项式(theta),即c采样自多项式分布。
- 选择文档长度:k〜泊松(长度),即k采样子泊松分布。
- k次,选择一个单词:w〜多项式(theta_c),即单词k满足多项式分布。
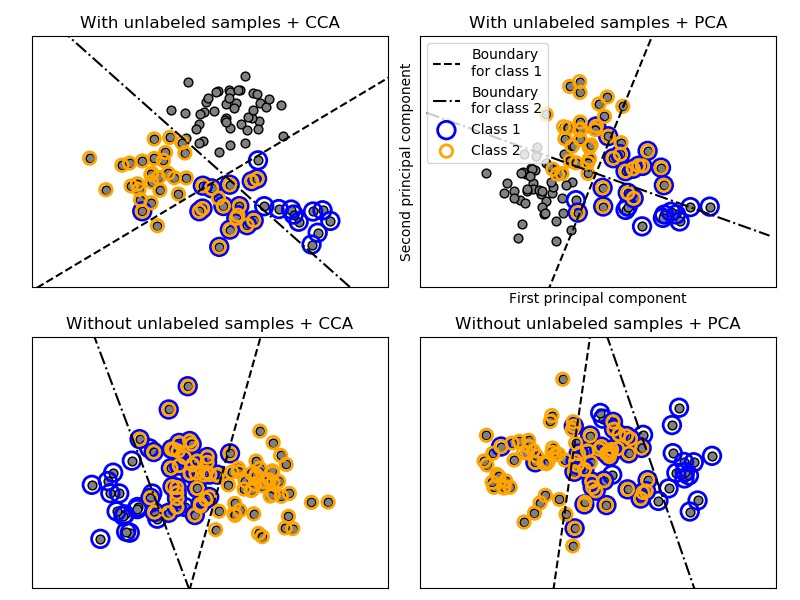
在以上过程中,使用拒绝抽样来确保n大于2,并且文档长度永远不会为零。同样,我们拒绝已经选择的类。分配给两个类别的文档被两个彩色圆圈包围。
通过将PCA和CCA发现的前两个主要成分做投影来进行分类的可视化,然后使用sklearn.multiclass.OneVsRestClassifier元分类器使用两个带有线性核的SVC来学习每个类的判别模型。请注意,PCA用于执行无监督的降维,而CCA用于执行有监督的降维。
注意:在图中,“unlabeled samples”并不意味着我们不知道标签(就像在半监督学习中一样),而是样本只是没有某一个标签。
代码实现[Python]
# -*- coding: utf-8 -*-
# Authors: Vlad Niculae, Mathieu Blondel
# License: BSD 3 clause
print(__doc__)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_multilabel_classification
from sklearn.multiclass import OneVsRestClassifier
from sklearn.svm import SVC
from sklearn.decomposition import PCA
from sklearn.cross_decomposition import CCA
def plot_hyperplane(clf, min_x, max_x, linestyle, label):
# get the separating hyperplane
w = clf.coef_[0]
a = -w[0] / w[1]
xx = np.linspace(min_x - 5, max_x + 5) # make sure the line is long enough
yy = a * xx - (clf.intercept_[0]) / w[1]
plt.plot(xx, yy, linestyle, label=label)
def plot_subfigure(X, Y, subplot, title, transform):
if transform == "pca":
X = PCA(n_components=2).fit_transform(X)
elif transform == "cca":
X = CCA(n_components=2).fit(X, Y).transform(X)
else:
raise ValueError
min_x = np.min(X[:, 0])
max_x = np.max(X[:, 0])
min_y = np.min(X[:, 1])
max_y = np.max(X[:, 1])
classif = OneVsRestClassifier(SVC(kernel='linear'))
classif.fit(X, Y)
plt.subplot(2, 2, subplot)
plt.title(title)
zero_class = np.where(Y[:, 0])
one_class = np.where(Y[:, 1])
plt.scatter(X[:, 0], X[:, 1], s=40, c='gray', edgecolors=(0, 0, 0))
plt.scatter(X[zero_class, 0], X[zero_class, 1], s=160, edgecolors='b',
facecolors='none', linewidths=2, label='Class 1')
plt.scatter(X[one_class, 0], X[one_class, 1], s=80, edgecolors='orange',
facecolors='none', linewidths=2, label='Class 2')
plot_hyperplane(classif.estimators_[0], min_x, max_x, 'k--',
'Boundary\nfor class 1')
plot_hyperplane(classif.estimators_[1], min_x, max_x, 'k-.',
'Boundary\nfor class 2')
plt.xticks(())
plt.yticks(())
plt.xlim(min_x - .5 * max_x, max_x + .5 * max_x)
plt.ylim(min_y - .5 * max_y, max_y + .5 * max_y)
if subplot == 2:
plt.xlabel('First principal component')
plt.ylabel('Second principal component')
plt.legend(loc="upper left")
plt.figure(figsize=(8, 6))
X, Y = make_multilabel_classification(n_classes=2, n_labels=1,
allow_unlabeled=True,
random_state=1)
plot_subfigure(X, Y, 1, "With unlabeled samples + CCA", "cca")
plot_subfigure(X, Y, 2, "With unlabeled samples + PCA", "pca")
X, Y = make_multilabel_classification(n_classes=2, n_labels=1,
allow_unlabeled=False,
random_state=1)
plot_subfigure(X, Y, 3, "Without unlabeled samples + CCA", "cca")
plot_subfigure(X, Y, 4, "Without unlabeled samples + PCA", "pca")
plt.subplots_adjust(.04, .02, .97, .94, .09, .2)
plt.show()
代码执行
代码运行时间大约:0分0.093秒。
运行代码输出的图片内容如下:
源码下载
- Python版源码文件: plot_multilabel.py
- Jupyter Notebook版源码文件: plot_multilabel.ipynb