scipy.stats.skew(array, axis=0, bias=True)函數計算數據集的偏度。
skewness = 0 : normally distributed. skewness > 0 : more weight in the left tail of the distribution. skewness < 0 : more weight in the right tail of the distribution.
其公式-
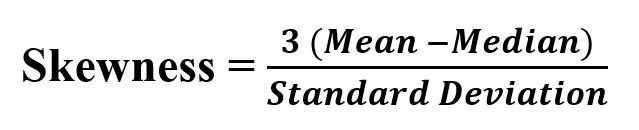
參數:
array :具有元素的輸入數組或對象。
axis :要測量偏度值的軸。默認情況下,軸= 0。
bias :布爾如果設置為False,則針對統計偏差對計算進行校正。
返回值:數據集沿軸的偏度值。
代碼1:
# Graph using numpy.linspace()
# finding Skewness
from scipy.stats import skew
import numpy as np
import pylab as p
x1 = np.linspace( -5, 5, 1000 )
y1 = 1./(np.sqrt(2.*np.pi)) * np.exp( -.5*(x1)**2 )
p.plot(x1, y1, '*')
print( '\nSkewness for data : ', skew(y1))輸出:
Skewness for data : 1.1108237139164436
代碼2:
# Graph using numpy.linspace()
# finding Skewness
from scipy.stats import skew
import numpy as np
import pylab as p
x1 = np.linspace( -5, 12, 1000 )
y1 = 1./(np.sqrt(2.*np.pi)) * np.exp( -.5*(x1)**2 )
p.plot(x1, y1, '.')
print( '\nSkewness for data : ', skew(y1))輸出:
Skewness for data : 1.917677776148478
代碼3:關於隨機數據
# finding Skewness
from scipy.stats import skew
import numpy as np
# random values based on a normal distribution
x = np.random.normal(0, 2, 10000)
print ("X : \n", x)
print('\nSkewness for data : ', skew(x))輸出:
X : [ 0.03255323 -6.18574775 -0.58430139 ... 3.22112446 1.16543279 0.84083317] Skewness for data : 0.03248837584866293
相關用法
- Python Scipy stats.chi()用法及代碼示例
- Python Scipy stats.f()用法及代碼示例
- Python Scipy stats.hmean()用法及代碼示例
- Python Scipy stats.halflogistic()用法及代碼示例
- Python Scipy stats.alpha()用法及代碼示例
- Python Scipy stats.halfnorm()用法及代碼示例
- Python Scipy stats.gompertz()用法及代碼示例
- Python Scipy stats.genlogistic()用法及代碼示例
- Python Scipy stats.fatiguelife()用法及代碼示例
- Python Scipy stats.fisk()用法及代碼示例
- Python Scipy stats.tmean()用法及代碼示例
- Python Scipy stats.genexpon()用法及代碼示例
- Python Scipy stats.genpareto()用法及代碼示例
- Python Scipy stats.mean()用法及代碼示例
- Python Scipy stats.gumbel_r()用法及代碼示例
注:本文由純淨天空篩選整理自vishal3096大神的英文原創作品 scipy stats.skew() | Python。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。