用法:
Series.plot.kde(bw_method=None, ind=None, **kwargs)使用高斯核生成核密度估計圖。
在統計學中,kernel density estimation (KDE) 是一種估計隨機變量概率密度函數 (PDF) 的非參數方法。此函數使用高斯核並包括自動帶寬確定。
- bw_method:str,標量或可調用,可選
用於計算估計器帶寬的方法。這可以是‘scott’, ‘silverman’、標量常量或可調用對象。如果無(默認),則使用‘scott’。有關詳細信息,請參閱
scipy.stats.gaussian_kde。- ind:NumPy 數組或 int,可選
估計 PDF 的評估點。如果無(默認),則使用 1000 個等距點。如果
ind是 NumPy 數組,則在傳遞的點處評估 KDE。如果ind是整數,則使用ind等距點數。- **kwargs:
其他關鍵字參數記錄在
DataFrame.plot()中。
- matplotlib.axes.Axes 或其中的 numpy.ndarray
參數:
返回:
例子:
給定從未知分布中隨機采樣的一係列點,使用具有自動帶寬確定函數的 KDE 估計其 PDF 並繪製結果,在 1000 個等間距點處評估它們(默認):
>>> s = pd.Series([1, 2, 2.5, 3, 3.5, 4, 5]) >>> ax = s.plot.kde()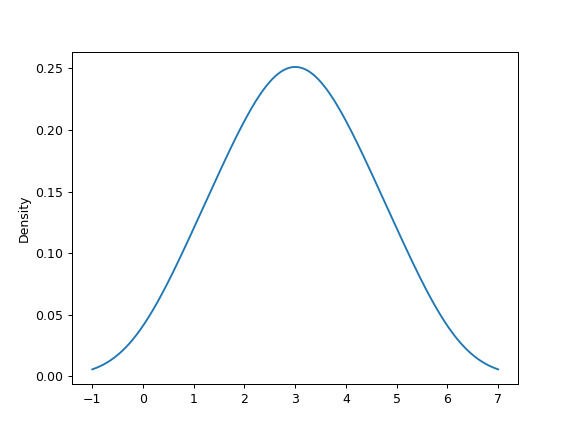
可以指定標量帶寬。使用較小的帶寬值會導致 over-fitting,而使用較大的帶寬值可能會導致 under-fitting:
>>> ax = s.plot.kde(bw_method=0.3)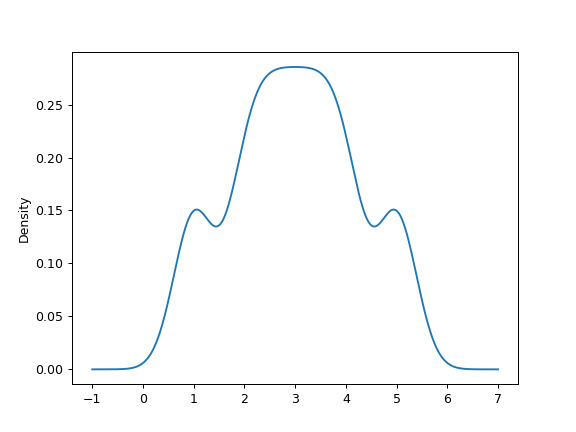
>>> ax = s.plot.kde(bw_method=3)
最後,
ind參數確定估計 PDF 繪圖的評估點:>>> ax = s.plot.kde(ind=[1, 2, 3, 4, 5])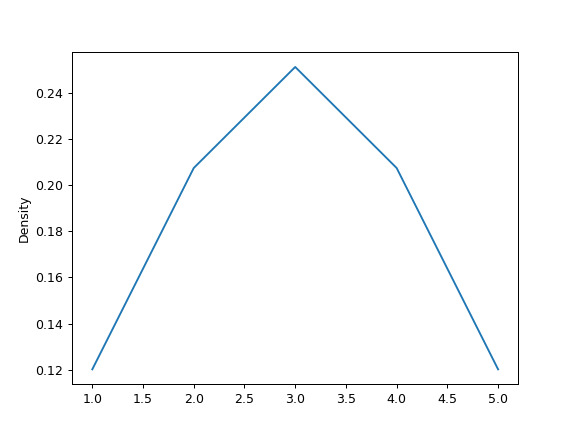
對於 DataFrame,它的工作方式相同:
>>> df = pd.DataFrame({ ... 'x': [1, 2, 2.5, 3, 3.5, 4, 5], ... 'y': [4, 4, 4.5, 5, 5.5, 6, 6], ... }) >>> ax = df.plot.kde()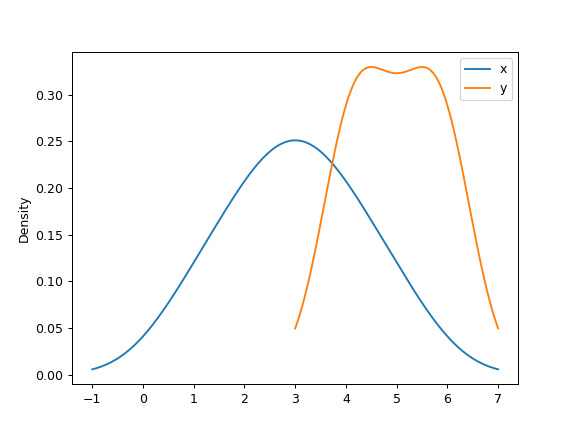
可以指定標量帶寬。使用較小的帶寬值會導致 over-fitting,而使用較大的帶寬值可能會導致 under-fitting:
>>> ax = df.plot.kde(bw_method=0.3)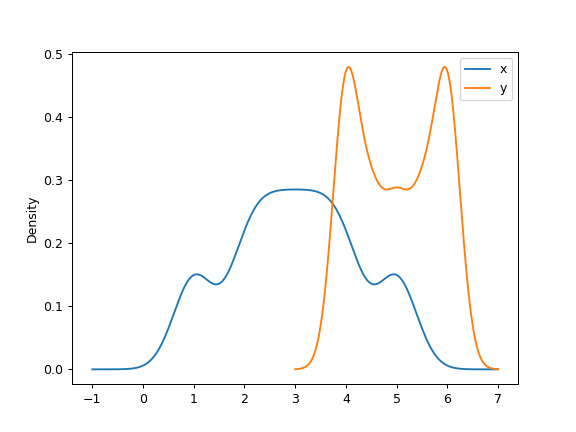
>>> ax = df.plot.kde(bw_method=3)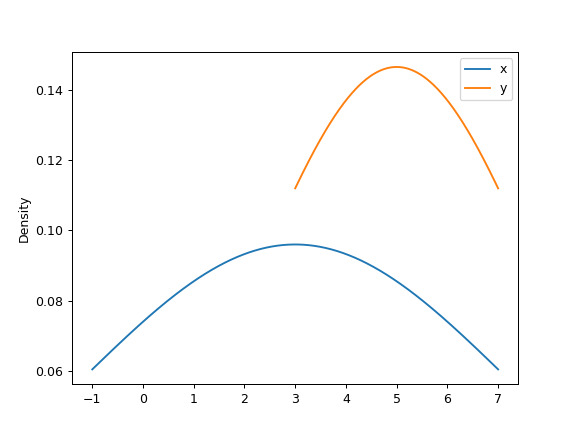
最後,
ind參數確定估計 PDF 繪圖的評估點:>>> ax = df.plot.kde(ind=[1, 2, 3, 4, 5, 6])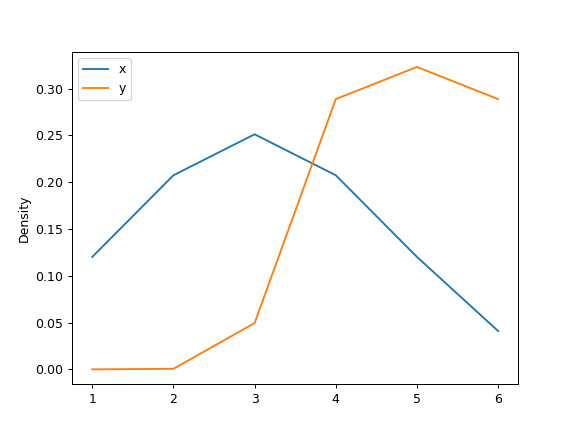
相關用法
- Python pandas.Series.plot.line用法及代碼示例
- Python pandas.Series.plot.hist用法及代碼示例
- Python pandas.Series.plot.box用法及代碼示例
- Python pandas.Series.plot.pie用法及代碼示例
- Python pandas.Series.plot.bar用法及代碼示例
- Python pandas.Series.plot.area用法及代碼示例
- Python pandas.Series.plot.barh用法及代碼示例
- Python pandas.Series.plot.density用法及代碼示例
- Python pandas.Series.pop用法及代碼示例
- Python pandas.Series.pow用法及代碼示例
- Python pandas.Series.product用法及代碼示例
- Python pandas.Series.pipe用法及代碼示例
- Python pandas.Series.pct_change用法及代碼示例
- Python pandas.Series.prod用法及代碼示例
- Python pandas.Series.add_prefix用法及代碼示例
- Python pandas.Series.map用法及代碼示例
- Python pandas.Series.max用法及代碼示例
- Python pandas.Series.str.isdecimal用法及代碼示例
- Python pandas.Series.str.get用法及代碼示例
- Python pandas.Series.to_csv用法及代碼示例
注:本文由純淨天空篩選整理自pandas.pydata.org大神的英文原創作品 pandas.Series.plot.kde。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。