Pandas 係列是帶有軸標簽的一維ndarray。標簽不必是唯一的,但必須是可哈希的類型。該對象同時支持基於整數和基於標簽的索引,並提供了許多方法來執行涉及索引的操作。
Pandas Series.truncate()函數用於在某個索引值之前和之後截斷Series或DataFrame。這是基於高於或低於某些閾值的索引值進行布爾索引的有用捷徑。
用法: Series.truncate(before=None, after=None, axis=None, copy=True)
參數:
before:截斷此索引值之前的所有行。
after:截斷此索引值之後的所有行。
axis:截斷軸。默認情況下截斷索引(行)。
copy:返回截斷部分的副本。
返回:截斷的Series或DataFrame。
範例1:采用Series.truncate()函數可在給定日期之前截斷該係列中的某些數據。
# importing pandas as pd
import pandas as pd
# Creating the Series
sr = pd.Series(['New York', 'Chicago', 'Toronto', 'Lisbon', 'Rio', 'Moscow'])
# Create the Datetime Index
didx = pd.DatetimeIndex(start ='2014-08-01 10:00', freq ='W',
periods = 6, tz = 'Europe/Berlin')
# set the index
sr.index = didx
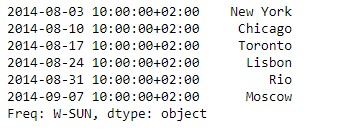
# Print the series
print(sr)輸出:
現在我們將使用Series.truncate()函數可截斷給定Series對象中“ 2014-08-17 10:00:00 + 02:00”之前的數據。
# truncate data prior to the given date
sr.truncate(before = '2014-08-17 10:00:00 + 02:00')輸出:
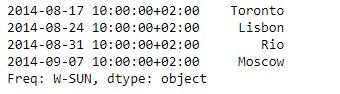
正如我們在輸出中看到的,Series.truncate()函數已成功截斷了上述日期之前的所有數據。
範例2:采用Series.truncate()函數在給定索引標簽之前和給定索引標簽之後截斷序列中的某些數據。
# importing pandas as pd
import pandas as pd
# Creating the Series
sr = pd.Series([19.5, 16.8, 22.78, 20.124, 18.1002])
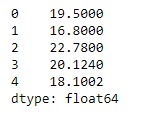
# Print the series
print(sr)輸出:
現在我們將使用Series.truncate()函數截斷給定Series對象中第一個索引標簽之前和第三個索引標簽之後的數據。
# truncate data outside the given range
sr.truncate(before = 1, after = 3)輸出:

正如我們在輸出中看到的,Series.truncate()函數已成功截斷了上述索引標簽之前和之後的所有數據。
相關用法
- Python pandas.map()用法及代碼示例
- Python Pandas Series.str.len()用法及代碼示例
- Python Pandas.factorize()用法及代碼示例
- Python Pandas TimedeltaIndex.name用法及代碼示例
- Python Pandas dataframe.ne()用法及代碼示例
- Python Pandas Series.between()用法及代碼示例
- Python Pandas DataFrame.where()用法及代碼示例
- Python Pandas Series.add()用法及代碼示例
- Python Pandas.pivot_table()用法及代碼示例
- Python Pandas Series.mod()用法及代碼示例
- Python Pandas Dataframe.at[ ]用法及代碼示例
- Python Pandas Dataframe.iat[ ]用法及代碼示例
- Python Pandas.pivot()用法及代碼示例
- Python Pandas dataframe.mul()用法及代碼示例
- Python Pandas.melt()用法及代碼示例
注:本文由純淨天空篩選整理自Shubham__Ranjan大神的英文原創作品 Python | Pandas Series.truncate()。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。