Pandas 係列是帶有軸標簽的一維ndarray。標簽不必是唯一的,但必須是可哈希的類型。該對象同時支持基於整數和基於標簽的索引,並提供了許多方法來執行涉及索引的操作。
Pandas Series.sem()函數返回所請求軸上的平均值的無偏標準誤差。默認情況下,結果由N-1歸一化。可以使用ddof參數進行更改。
用法: Series.sem(axis=None, skipna=None, level=None, ddof=1, numeric_only=None, **kwargs)
參數:
axis:{索引(0)}
skipna:排除NA /空值。
level:如果軸是MultiIndex(分層),則沿特定級別計數,並折疊成標量。
ddof:Delta自由度。
numeric_only:僅包括float,int,boolean列。
返回:標量或係列(如果指定級別)
範例1:采用Series.sem()函數來查找給定Series對象中基礎數據的平均值的標準誤差。
# importing pandas as pd
import pandas as pd
# Creating the Series
sr = pd.Series([100, 25, 32, 118, 24, 65])
# Print the series
print(sr)輸出:

現在我們將使用Series.sem()函數查找基礎數據均值的標準誤。
# find standard error of the mean
sr.sem()輸出:
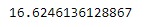
從輸出中可以看到,Series.sem()函數已成功計算標準誤差,即給定Series對象中基礎數據的平均值。
範例2:采用Series.sem()函數來查找給定Series對象中基礎數據的平均值的標準誤差。給定的Series對象還包含一些缺少的值。
# importing pandas as pd
import pandas as pd
# Creating the Series
sr = pd.Series([19.5, 16.8, None, 22.78, None, 20.124, None, 18.1002, None])
# Print the series
print(sr)輸出:

現在我們將使用Series.sem()函數查找基礎數據均值的標準誤。
# find standard error of the mean
# Skip all the missing values
sr.sem(skipna = True)輸出:
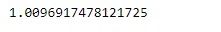
從輸出中可以看到,Series.sem()函數已成功計算標準誤差,即給定Series對象中基礎數據的平均值。
相關用法
- Python pandas.map()用法及代碼示例
- Python Pandas Series.str.len()用法及代碼示例
- Python Pandas.factorize()用法及代碼示例
- Python Pandas TimedeltaIndex.name用法及代碼示例
- Python Pandas dataframe.ne()用法及代碼示例
- Python Pandas Series.between()用法及代碼示例
- Python Pandas DataFrame.where()用法及代碼示例
- Python Pandas Series.add()用法及代碼示例
- Python Pandas.pivot_table()用法及代碼示例
- Python Pandas Series.mod()用法及代碼示例
- Python Pandas Dataframe.at[ ]用法及代碼示例
- Python Pandas Dataframe.iat[ ]用法及代碼示例
- Python Pandas.pivot()用法及代碼示例
- Python Pandas dataframe.mul()用法及代碼示例
- Python Pandas.melt()用法及代碼示例
注:本文由純淨天空篩選整理自Shubham__Ranjan大神的英文原創作品 Python | Pandas Series.sem()。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。