Python是進行數據分析的一種出色語言,主要是因為以數據為中心的python軟件包具有奇妙的生態係統。 Pandas是其中的一種,使導入和分析數據更加容易。
Pandas set_index()是一種將列表,係列或 DataFrame 設置為 DataFrame 索引的方法。也可以在製作 DataFrame 時設置索引列。但是有時一個數據幀是由兩個或多個數據幀組成的,因此可以使用此方法更改以後的索引。
用法:
DataFrame.set_index(keys, drop=True, append=False, inplace=False, verify_integrity=False)
參數:
-
keys:列名或列名列表。
drop:布爾值,如果為True,則刪除用於索引的列。
append:如果為True,則將該列追加到現有索引列。
inplace:如果為True,則在 DataFrame 中進行更改。
verify_integrity:如果為True,則檢查新索引列是否重複。
要下載使用的CSV文件,請單擊此處。
代碼1:更改索引欄
在此示例中,“名字”列已成為“數據幀”的索引列。
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("employees.csv")
# setting first name as index column
data.set_index("First Name", inplace = True)
# display
data.head()輸出:
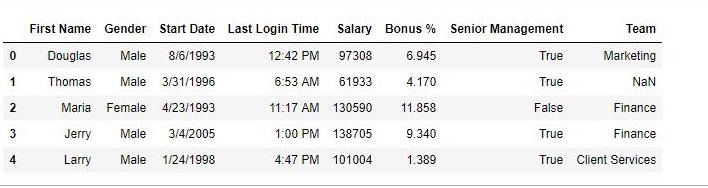
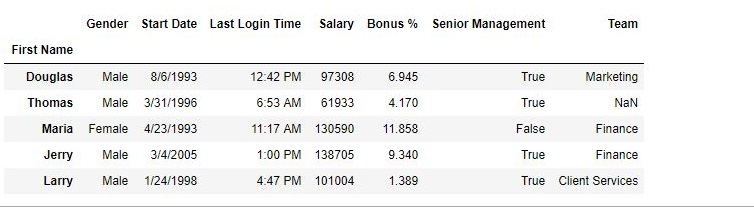
如輸出圖像中所示,索引列之前是一係列數字,但後來已被名字替換。
手術前-
手術後-
代碼2:多索引列
在此示例中,將創建兩列作為索引列。 Drop參數用於刪除列,而append參數用於將傳遞的列追加到已經存在的索引列。
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("employees.csv")
# setting first name as index column
data.set_index(["First Name", "Gender"], inplace = True,
append = True, drop = False)
# display
data.head()輸出:
如輸出Image所示,數據具有3個索引列。
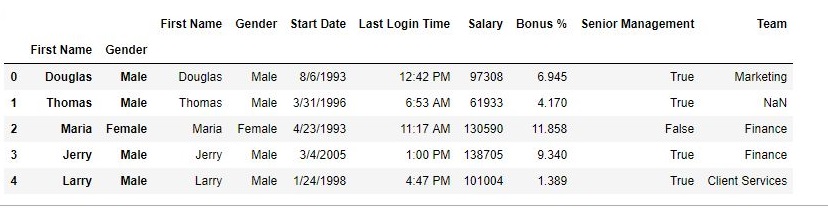
相關用法
- Python pandas.map()用法及代碼示例
- Python Pandas Series.str.len()用法及代碼示例
- Python Pandas.factorize()用法及代碼示例
- Python Pandas TimedeltaIndex.name用法及代碼示例
- Python Pandas dataframe.ne()用法及代碼示例
- Python Pandas Series.between()用法及代碼示例
- Python Pandas DataFrame.where()用法及代碼示例
- Python Pandas Series.add()用法及代碼示例
- Python Pandas.pivot_table()用法及代碼示例
- Python Pandas Series.mod()用法及代碼示例
- Python Pandas Dataframe.at[ ]用法及代碼示例
- Python Pandas Dataframe.iat[ ]用法及代碼示例
- Python Pandas.pivot()用法及代碼示例
- Python Pandas dataframe.mul()用法及代碼示例
- Python Pandas.melt()用法及代碼示例
注:本文由純淨天空篩選整理自Kartikaybhutani大神的英文原創作品 Python | Pandas DataFrame.set_index()。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。