Python是進行數據分析的一種出色語言,主要是因為以數據為中心的python軟件包具有奇妙的生態係統。 Pandas是其中的一種,使導入和分析數據更加容易。
Pandas rename()方法用於重命名任何索引,列或行。列的重命名也可以通過dataframe.columns = [#list]。但在上述情況下,自由度不高。即使必須更改一列,也必須傳遞完整的列列表。另外,上述方法不適用於索引標簽。
用法: DataFrame.rename(mapper=None, index=None, columns=None, axis=None, copy=True, inplace=False, level=None)
參數:
映射器,索引和列:字典值,鍵表示舊名稱,值表示新名稱。這些參數隻能一次使用。
axis:int或字符串值,“ 0”表示行,“ 1”表示列。
copy:如果為True,則複製基礎數據。
inplace:如果為True,則在原始 DataFrame 中進行更改。
level:用於在數據幀具有多個級別索引的情況下指定級別。
返回類型:具有新名稱的 DataFrame
要下載代碼中使用的CSV,請點擊此處。
範例1:更改索引標簽
在此示例中,名稱列設置為索引列,稍後使用rename()方法更改其名稱。
# importing pandas module
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv", index_col ="Name" )
# changing index cols with rename()
data.rename(index = {"Avery Bradley":"NEW NAME",
"Jae Crowder":"NEW NAME 2"},
inplace = True)
# display
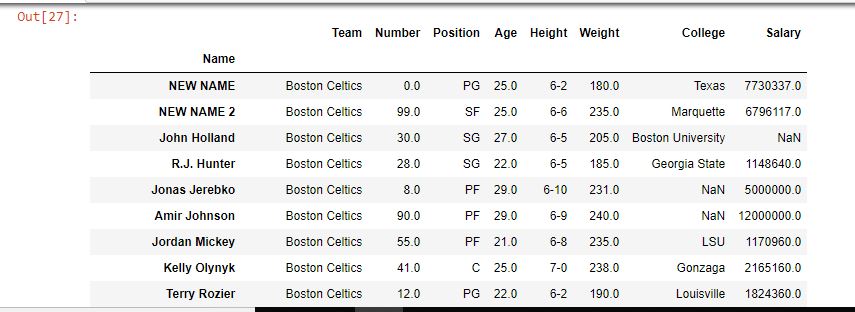
data輸出:
如輸出圖像中所示,第一和第二位置的索引標簽的名稱已更改為NEW NAME&NEW NAME 2。
範例2:更改多個列名
在此示例中,通過傳遞字典來更改多個列名。之後,將結果與使用.columns方法返回的數據幀進行比較。由於NaN == NaN將返回false,因此在比較之前將空值刪除。
# importing pandas module
import pandas as pd
# making data frame from csv file
data = pd.read_csv("nba.csv", index_col ="Name" )
# changing cols with rename()
new_data = data.rename(columns = {"Team":"Team Name",
"College":"Education",
"Salary":"Income"})
# changing columns using .columns()
data.columns = ['Team Name', 'Number', 'Position', 'Age',
'Height', 'Weight', 'Education', 'Income']
# dropna used to ignore na values
print(new_data.dropna()== data.dropna())輸出:
如輸出圖像所示,由於所有值均為True,因此使用這兩種方法的結果相同。

相關用法
- Python pandas.map()用法及代碼示例
- Python Pandas Series.str.len()用法及代碼示例
- Python Pandas.factorize()用法及代碼示例
- Python Pandas TimedeltaIndex.name用法及代碼示例
- Python Pandas dataframe.ne()用法及代碼示例
- Python Pandas Series.between()用法及代碼示例
- Python Pandas DataFrame.where()用法及代碼示例
- Python Pandas Series.add()用法及代碼示例
- Python Pandas.pivot_table()用法及代碼示例
- Python Pandas Series.mod()用法及代碼示例
- Python Pandas Dataframe.at[ ]用法及代碼示例
- Python Pandas Dataframe.iat[ ]用法及代碼示例
- Python Pandas.pivot()用法及代碼示例
- Python Pandas dataframe.mul()用法及代碼示例
- Python Pandas.melt()用法及代碼示例
注:本文由純淨天空篩選整理自Kartikaybhutani大神的英文原創作品 Python | Pandas Dataframe.rename()。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。