Python是進行數據分析的一種出色語言,主要是因為以數據為中心的python軟件包具有奇妙的生態係統。 Pandas是其中的一種,使導入和分析數據更加容易。
Pandas dataframe.groupby()函數用於根據某些條件將數據分成幾組。 Pandas 對象可以在任何軸上拆分。分組的抽象定義是提供標簽到分組名稱的映射。
用法: DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, **kwargs)
參數:
by:映射,函數,str或可迭代
axis:整數,默認0
level:如果軸是MultiIndex(分層),則按一個或多個特定級別分組
as_index:對於聚合輸出,返回帶有組標簽的對象作為索引。僅與DataFrame輸入有關。 as_index = False實際上是“SQL-style”分組輸出
sort:排序組鍵。關閉此函數可獲得更好的性能。請注意,這不會影響每個組中觀察的順序。 groupby保留每個組中行的順序。
group_keys:調用apply時,將組鍵添加到索引以識別片段
squeeze:如果可能,請減小返回類型的維數,否則返回一致的類型
返回:GroupBy對象
有關在代碼中使用的CSV文件的鏈接,請單擊此處
範例1:采用groupby()函數根據“Team”對數據進行分組。
# importing pandas as pd
import pandas as pd
# Creating the dataframe
df = pd.read_csv("nba.csv")
# Print the dataframe
df
現在應用groupby()函數。
# applying groupby() function to
# group the data on team value.
gk = df.groupby('Team')
# Let's print the first entries
# in all the groups formed.
gk.first()輸出:
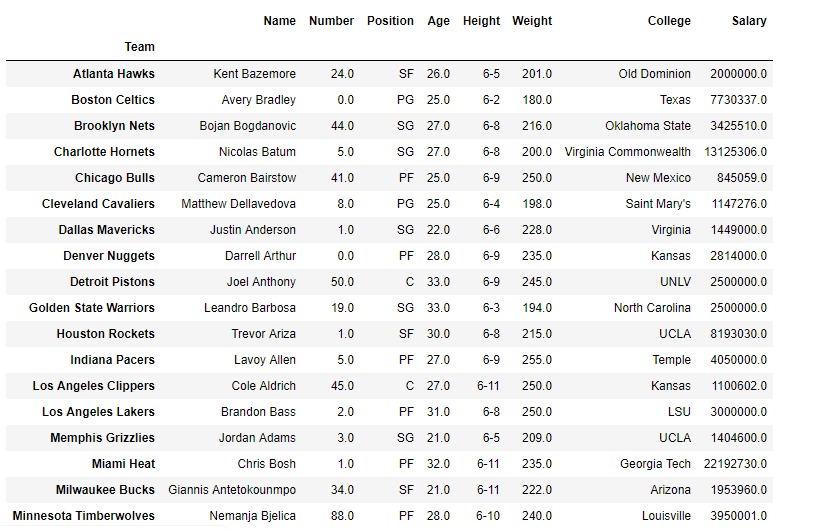
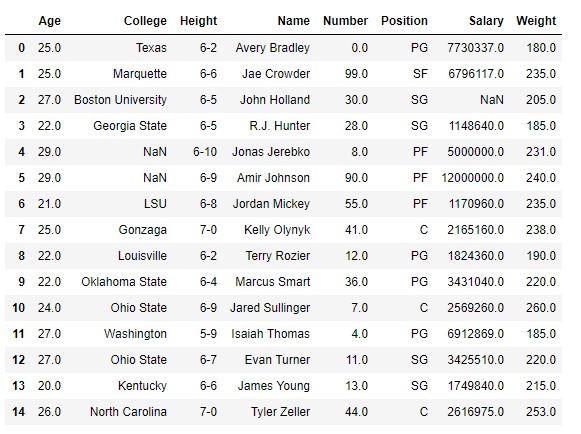
讓我們打印包含組中任何一個的值。為此,請使用團隊的名稱。我們使用函數get_group()查找任何組中包含的條目。
# Finding the values contained in the "Boston Celtics" group
gk.get_group('Boston Celtics')輸出:
範例2:采用groupby()函數可根據一個以上的類別形成組(即使用多個列進行拆分)。
# importing pandas as pd
import pandas as pd
# Creating the dataframe
df = pd.read_csv("nba.csv")
# First grouping based on "Team"
# Within each team we are grouping based on "Position"
gkk = daf.groupby(['Team', 'Position'])
# Print the first value in each group
gkk.first()輸出:
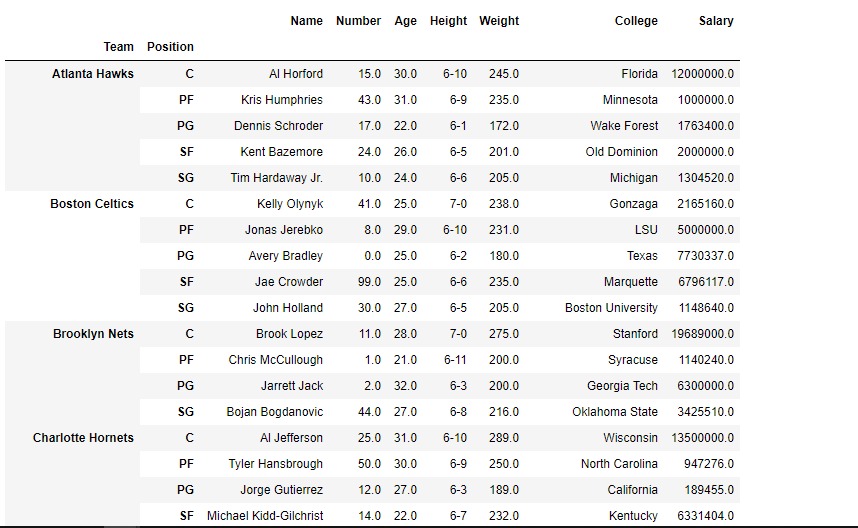
groupby()是一個非常強大的函數,具有多種變體。這使得根據某些標準拆分數據幀的任務真正變得簡單而高效。
相關用法
- Python pandas.map()用法及代碼示例
- Python Pandas Series.str.len()用法及代碼示例
- Python Pandas.factorize()用法及代碼示例
- Python Pandas TimedeltaIndex.name用法及代碼示例
- Python Pandas dataframe.ne()用法及代碼示例
- Python Pandas Series.between()用法及代碼示例
- Python Pandas DataFrame.where()用法及代碼示例
- Python Pandas Series.add()用法及代碼示例
- Python Pandas.pivot_table()用法及代碼示例
- Python Pandas Series.mod()用法及代碼示例
- Python Pandas Dataframe.at[ ]用法及代碼示例
- Python Pandas Dataframe.iat[ ]用法及代碼示例
- Python Pandas.pivot()用法及代碼示例
- Python Pandas dataframe.mul()用法及代碼示例
- Python Pandas.melt()用法及代碼示例
注:本文由純淨天空篩選整理自Shubham__Ranjan大神的英文原創作品 Python | Pandas dataframe.groupby()。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。