Python是進行數據分析的一種出色語言,主要是因為以數據為中心的python軟件包具有奇妙的生態係統。 Pandas是其中的一種,使導入和分析數據更加容易。
Pandas dataframe.eval()函數用於在調用 DataFrame 實例的上下文中評估表達式。該表達式在 DataFrame 的列上求值。
用法: DataFrame.eval(expr, inplace=False, **kwargs)
參數:
expr:要計算的表達式字符串。
inplace:如果表達式包含一個賦值,則是否就地執行操作並更改現有的DataFrame。否則,新
返回DataFrame。
kwargs:有關query()接受的關鍵字參數的完整詳細信息,請參見eval()的文檔。
返回:ret:ndarray,標量或pandas對象
範例1:采用eval()函數用於評估 DataFrame 中所有列元素的總和,並將結果列插入 DataFrame 中。
# importing pandas as pd
import pandas as pd
# Creating the dataframe
df=pd.DataFrame({"A":[1,5,7,8],
"B":[5,8,4,3],
"C":[10,4,9,3]})
# Print the first dataframe
df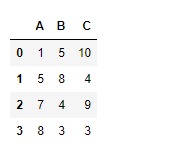
讓我們評估所有列的總和並將結果列添加到 DataFrame
# To evaluate the sum over all the columns
df.eval('D = A + B+C', inplace = True)
# Print the modified dataframe
df輸出:
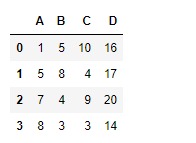
範例2:采用eval()函數用於評估 DataFrame 中任何兩個列元素的總和,並將結果列插入 DataFrame 中。 DataFrame 具有NaN值。
注意:任何表達式都不能超過NaN值。因此對應的單元格將是NaN太。
# importing pandas as pd
import pandas as pd
# Creating the dataframe
df=pd.DataFrame({"A":[1,2,3],
"B":[4,5,None],
"C":[7,8,9]})
# Print the dataframe
df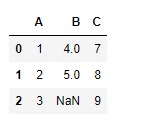
我們來評估列“B”和“C”的總和。
# To evaluate the sum of two columns in the dataframe
df.eval('D = B + C', inplace = True)
# Print the modified dataframe
df輸出:
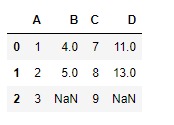
請注意,結果列“ D”具有NaN最後一行的值,因為評估中使用的相應單元格是NaN細胞。
相關用法
- Python pandas.map()用法及代碼示例
- Python Pandas Series.str.len()用法及代碼示例
- Python Pandas.factorize()用法及代碼示例
- Python Pandas TimedeltaIndex.name用法及代碼示例
- Python Pandas dataframe.ne()用法及代碼示例
- Python Pandas Series.between()用法及代碼示例
- Python Pandas DataFrame.where()用法及代碼示例
- Python Pandas Series.add()用法及代碼示例
- Python Pandas.pivot_table()用法及代碼示例
- Python Pandas Series.mod()用法及代碼示例
- Python Pandas Dataframe.at[ ]用法及代碼示例
- Python Pandas Dataframe.iat[ ]用法及代碼示例
- Python Pandas.pivot()用法及代碼示例
- Python Pandas dataframe.mul()用法及代碼示例
- Python Pandas.melt()用法及代碼示例
注:本文由純淨天空篩選整理自Shubham__Ranjan大神的英文原創作品 Python | Pandas dataframe.eval()。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。