Python是進行數據分析的一種出色語言,主要是因為以數據為中心的python軟件包具有奇妙的生態係統。 Pandas是其中的一種,使導入和分析數據更加容易。
數據分析的重要部分是分析重複值並將其刪除。 Pandas duplicated()方法僅有助於分析重複值。它返回一個布爾序列,僅對唯一元素而言為True。
用法:
DataFrame.duplicated(subset=None, keep='first')
參數:
-
subset:取得一列或列標簽列表。默認值為無。傳遞列後,它將僅將它們視為重複項。
keep:控製如何考慮重複值。它隻有三個不同的值,默認值為“第一”。
->如果為“第一個”,則它將第一個值視為唯一值,並將其餘相同的值視為重複值。
->如果為“ last”,則它將last值視為唯一值,並將其餘相同的值視為重複值。
->如果為False,則將所有相同的值視為重複項。
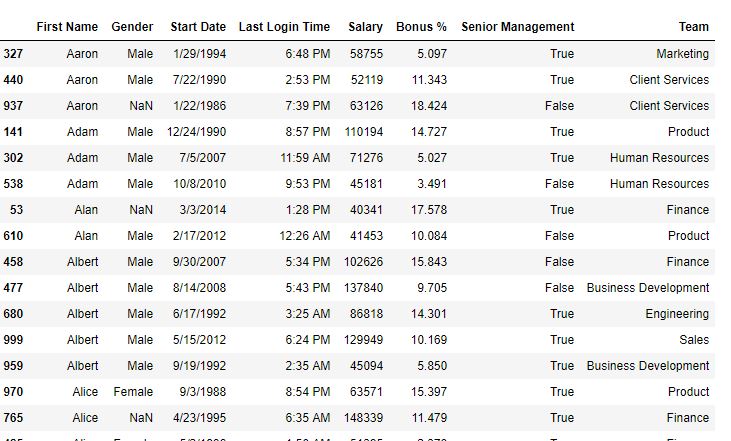
要下載使用的CSV文件,請單擊此處。例1:返回布爾序列
在下麵的示例中,根據“名字”列中的重複值返回布爾係列。
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("employees.csv")
# sorting by first name
data.sort_values("First Name", inplace = True)
# making a bool series
bool_series = data["First Name"].duplicated()
# displaying data
data.head()
# display data
data[bool_series]輸出:
如輸出圖像中所示,由於keep參數的默認值為“ first”,因此,無論何時出現名稱,第一個都將被視為“唯一”,並且會被視為“重複”。
範例2:刪除重複項
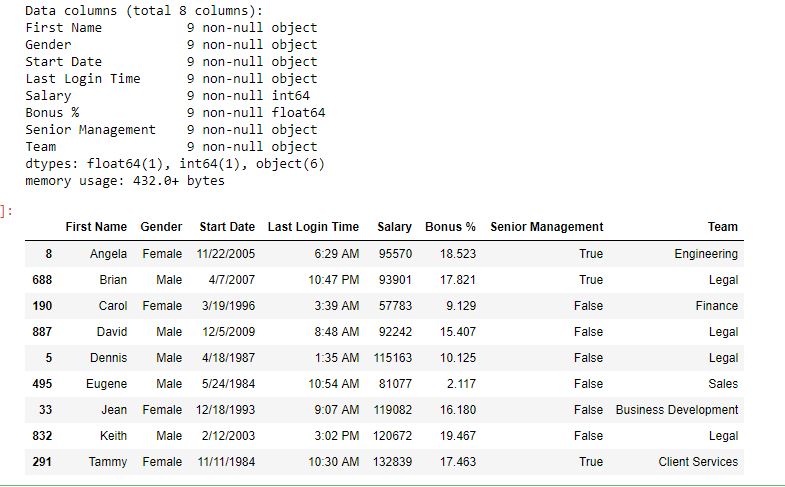
在此示例中,keep參數設置為False,以便僅采用唯一值,並從數據中刪除重複值。
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("employees.csv")
# sorting by first name
data.sort_values("First Name", inplace = True)
# making a bool series
bool_series = data["First Name"].duplicated(keep = False)
# bool series
bool_series
# passing NOT of bool series to see unique values only
data = data[~bool_series]
# displaying data
data.info()
data輸出:
由於duplicated()方法對於重複項返回False,因此采用該係列的NOT來查看數據幀中的唯一值。
相關用法
- Python pandas.map()用法及代碼示例
- Python Pandas Series.str.len()用法及代碼示例
- Python Pandas.factorize()用法及代碼示例
- Python Pandas TimedeltaIndex.name用法及代碼示例
- Python Pandas dataframe.ne()用法及代碼示例
- Python Pandas Series.between()用法及代碼示例
- Python Pandas DataFrame.where()用法及代碼示例
- Python Pandas Series.add()用法及代碼示例
- Python Pandas.pivot_table()用法及代碼示例
- Python Pandas Series.mod()用法及代碼示例
- Python Pandas Dataframe.at[ ]用法及代碼示例
- Python Pandas Dataframe.iat[ ]用法及代碼示例
- Python Pandas.pivot()用法及代碼示例
- Python Pandas dataframe.mul()用法及代碼示例
- Python Pandas.melt()用法及代碼示例
注:本文由純淨天空篩選整理自Kartikaybhutani大神的英文原創作品 Python | Pandas Dataframe.duplicated()。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。