Python是進行數據分析的一種出色語言,主要是因為以數據為中心的Python軟件包具有奇妙的生態係統。 Pandas是其中的一種,使導入和分析數據更加容易。
Dataframe.add()方法用於添加數據幀和其他逐元素(二進製運算符add)。等效於 DataFrame +其他,但支持用fill_value代替輸入之一中的丟失數據。
用法: DataFrame.add(other, axis=’columns’, level=None, fill_value=None)
參數:
other:係列,DataFrame或常量
axis:{0,1,'索引','列'}對於“係列”輸入,軸與“
fill_value:[無值或浮點值,默認為無]用此值填充缺失的(NaN)值。如果兩個DataFrame位置都丟失,則結果將丟失。
level:[int或name]在一個級別上廣播,在傳遞的MultiIndex級別上匹配Index值
返回值:結果DataFrame
# Importing Pandas as pd
import pandas as pd
# Importing numpy as np
import numpy as np
# Creating a dataframe
# Setting the seed value to re-generate the result.
np.random.seed(25)
df = pd.DataFrame(np.random.rand(10, 3), columns =['A', 'B', 'C'])
# np.random.rand(10, 3) has generated a
# random 2-Dimensional array of shape 10 * 3
# which is then converted to a dataframe
df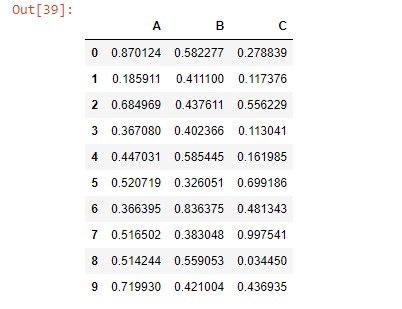
注意: add() 函數類似於“ +”操作,但add()為輸入之一中的缺失值提供了額外的支持。
# We want NaN values in dataframe.
# so let's fill the last row with NaN value
df.iloc[-1] = np.nan
df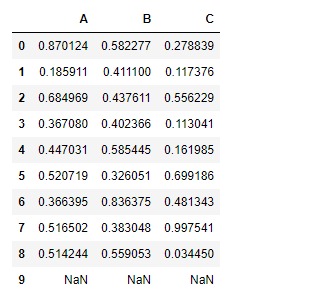
使用以下方法向 DataFrame 添加常量值add()函數:
# add 1 to all the elements
# of the data frame
df.add(1)
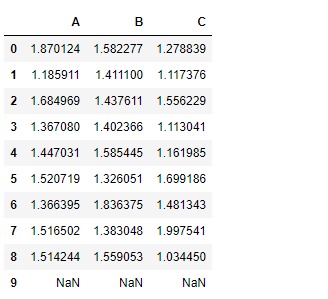
注意上麵的輸出,df中的nan單元未進行任何加法運算dataframe.add() 函數具有屬性fill_value。這將用分配的值填充缺失值(Nan)。如果兩個 DataFrame 值都丟失,那麽結果將丟失。
讓我們來看看如何做。
# We have given a default value
# of '10' for all the nan cells
df.add(1, fill_value = 10)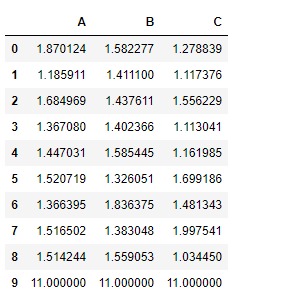
所有的nan單元格先填充10個,然後再添加1個。將係列添加到 DataFrame :
對於係列輸入,索引的維必須與 DataFrame 和係列都匹配。
# Create a Series of 10 values
tk = pd.Series(np.ones(10))
# tk is a Series of 10 elements
# all filled with 1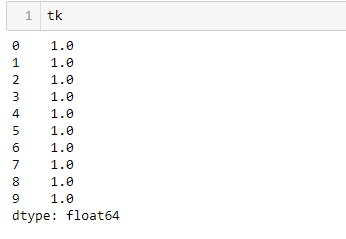
# Add tk(series) to the df(dataframe)
# along the index axis
df.add(tk, axis ='index')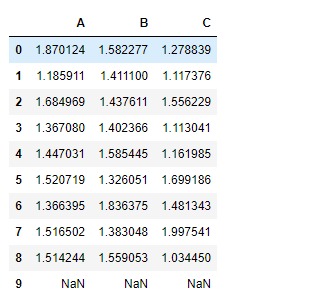
將一個數據幀與其他數據幀相加
# Create a second dataframe
# First set the seed to regenerate the result
np.random.seed(10)
# Create a 5 * 5 dataframe
df2 = pd.DataFrame(np.random.rand(5, 5), columns =['A', 'B', 'C', 'D', 'E'])
df2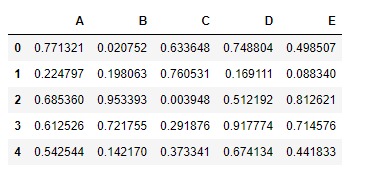
讓我們對這兩個數據幀進行逐元素加法
df.add(df2)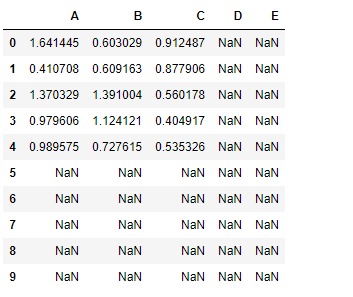
請注意,所得 DataFrame 的尺寸為10 * 5,並且在所有 DataFrame 中任一 DataFrame 具有nan值的單元格中都具有nan值。
修複它-
# Set a default value of 10 for nan cells
# nan value won't be filled for those cells
# in which both data frames has nan value
df.add(df2, fill_value = 10)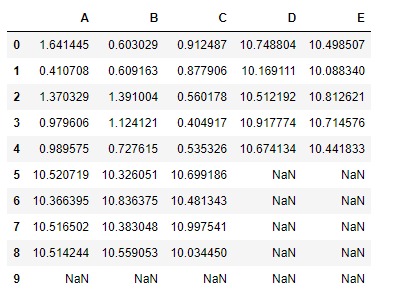
相關用法
- Python pandas.map()用法及代碼示例
- Python Pandas Series.str.len()用法及代碼示例
- Python Pandas.factorize()用法及代碼示例
- Python Pandas TimedeltaIndex.name用法及代碼示例
- Python Pandas dataframe.ne()用法及代碼示例
- Python Pandas Series.between()用法及代碼示例
- Python Pandas DataFrame.where()用法及代碼示例
- Python Pandas Series.add()用法及代碼示例
- Python Pandas.pivot_table()用法及代碼示例
- Python Pandas Series.mod()用法及代碼示例
- Python Pandas Dataframe.at[ ]用法及代碼示例
- Python Pandas Dataframe.iat[ ]用法及代碼示例
- Python Pandas.pivot()用法及代碼示例
- Python Pandas dataframe.mul()用法及代碼示例
- Python Pandas.melt()用法及代碼示例
注:本文由純淨天空篩選整理自Shubham__Ranjan大神的英文原創作品 Python | Pandas dataframe.add()。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。