排列测试涉及在执行测试之前对数据集中的一个或多个变量进行排列,以便打破任何现有关系并模拟原假设。然后可以将真实统计量与生成的空统计量分布进行比较。
参数
- data
-
一个 DataFrame
- n
-
要生成的排列数。
- ...
-
要排列的列。这支持裸列名称或 dplyr dplyr::select_helpers
- .id
-
为每个模型提供唯一整数 ID 的变量名称。
- columns
-
在
permute_中,要排列的列名称向量。
例子
library(purrr)
perms <- permute(mtcars, 100, mpg)
models <- map(perms$perm, ~ lm(mpg ~ wt, data = .))
glanced <- map_df(models, broom::glance, .id = "id")
# distribution of null permutation statistics
hist(glanced$statistic)
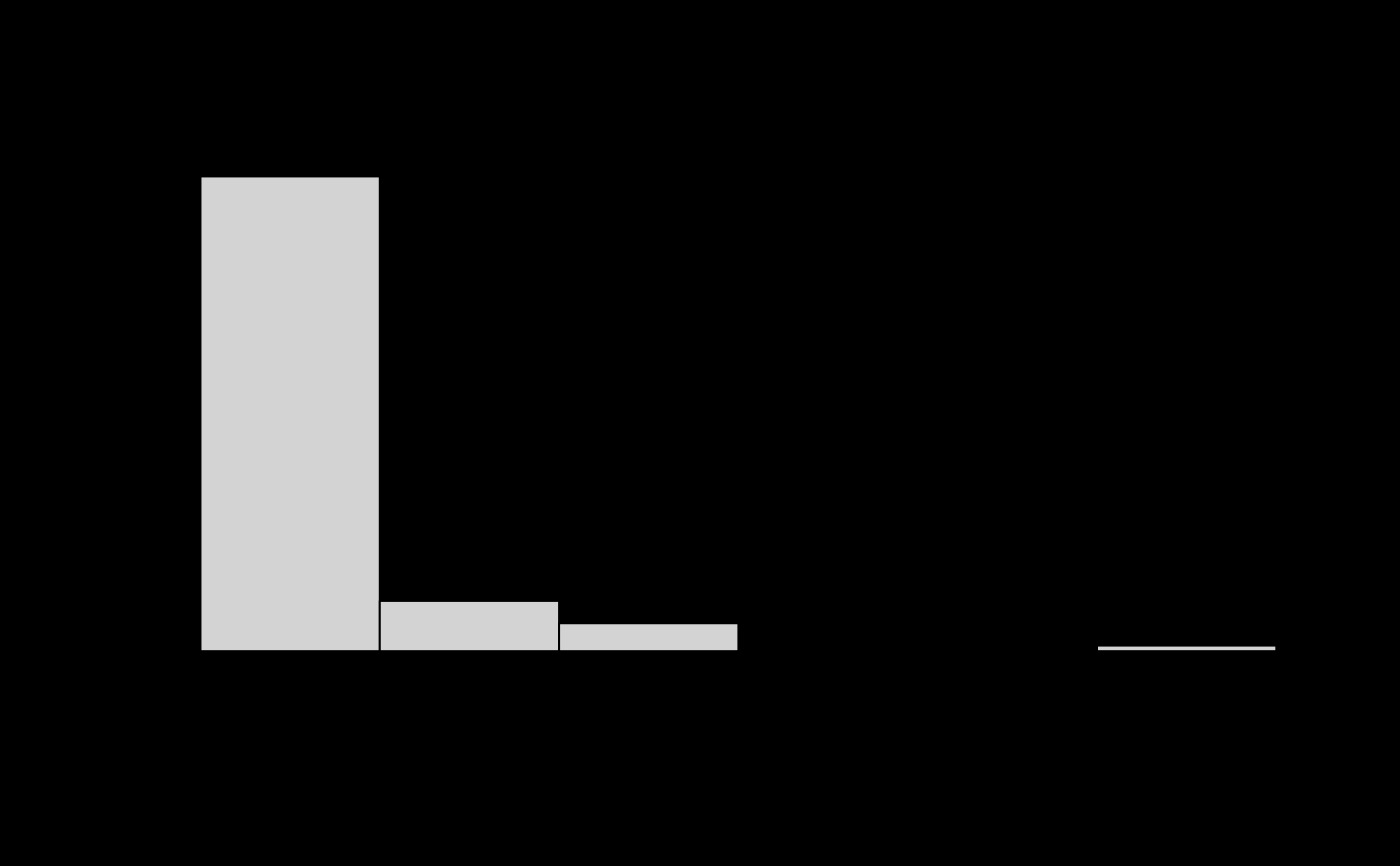 # confirm these are roughly uniform p-values
hist(glanced$p.value)
# confirm these are roughly uniform p-values
hist(glanced$p.value)
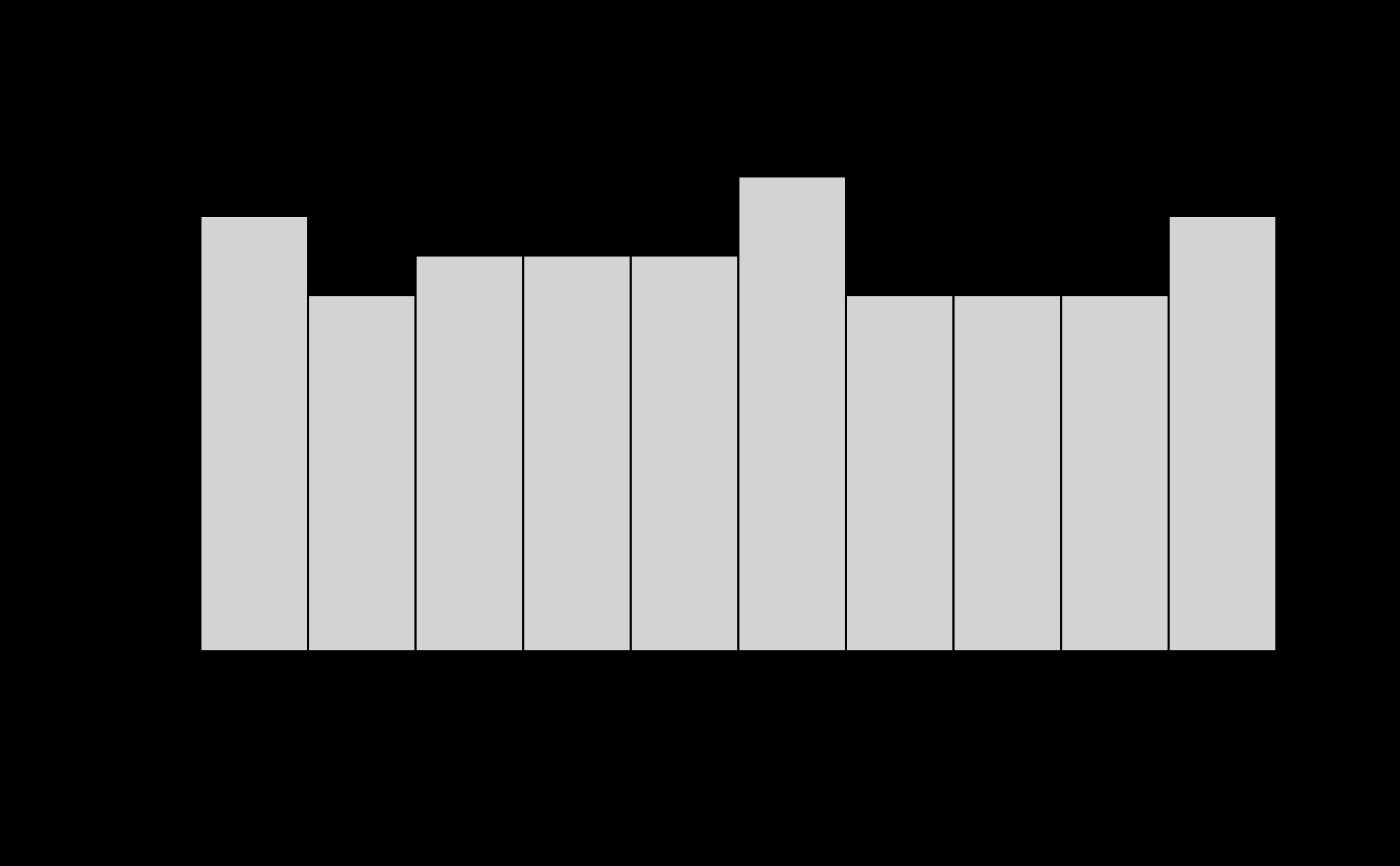 # test against the unpermuted model to get a permutation p-value
mod <- lm(mpg ~ wt, mtcars)
mean(glanced$statistic > broom::glance(mod)$statistic)
#> [1] 0
# test against the unpermuted model to get a permutation p-value
mod <- lm(mpg ~ wt, mtcars)
mean(glanced$statistic > broom::glance(mod)$statistic)
#> [1] 0
相关用法
- R modelr typical 求典型值
- R modelr resample “惰性”重采样。
- R modelr crossv_mc 生成测试训练对以进行交叉验证
- R modelr model_matrix 构建设计矩阵
- R modelr model-quality 计算给定数据集的模型质量
- R modelr fit_with 拟合公式列表
- R modelr add_residuals 将残差添加到 DataFrame
- R modelr data_grid 生成数据网格。
- R modelr formulas 创建公式列表
- R modelr add_predictions 将预测添加到 DataFrame
- R modelr seq_range 生成向量范围内的序列
- R modelr resample_partition 生成数据帧的独占分区
- R modelr add_predictors 将预测变量添加到公式中
- R modelr na.warn 处理缺失值并发出警告
- R modelr bootstrap 生成 n 个引导程序重复。
- R modelr resample_bootstrap 生成 boostrap 复制
- R vcov.gam 从 GAM 拟合中提取参数(估计器)协方差矩阵
- R gam.check 拟合 gam 模型的一些诊断
- R matrix转list用法及代码示例
- R as 强制对象属于某个类
- R null.space.dimension TPRS 未惩罚函数空间的基础
- R language-class 表示未评估语言对象的类
- R gam.reparam 寻找平方根惩罚的稳定正交重新参数化。
- R className 类名包含对应的包
- R extract.lme.cov 从 lme 对象中提取数据协方差矩阵
注:本文由纯净天空筛选整理自Hadley Wickham等大神的英文原创作品 Generate n permutation replicates.。非经特殊声明,原始代码版权归原作者所有,本译文未经允许或授权,请勿转载或复制。