计算观察类和预测类的 cross-tabulation。
用法
conf_mat(data, ...)
# S3 method for data.frame
conf_mat(
data,
truth,
estimate,
dnn = c("Prediction", "Truth"),
case_weights = NULL,
...
)
# S3 method for conf_mat
tidy(x, ...)参数
- data
-
数据帧或
base::table()。 - ...
-
不曾用过。
- truth
-
真实类结果的列标识符(即
factor)。这应该是一个不带引号的列名,尽管此参数是通过表达式传递的并且支持quasiquotation(您可以不带引号的列名)。对于_vec()函数,一个factor向量。 - estimate
-
预测类结果的列标识符(也是
factor)。与truth一样,可以通过不同的方式指定,但主要方法是使用不带引号的变量名称。对于_vec()函数,一个factor向量。 - dnn
-
表的暗名称的字符向量。
- case_weights
-
案例权重的可选列标识符。这应该是一个不带引号的列名称,其计算结果为
data中的数字列。对于_vec()函数,一个数值向量。 - x
-
conf_mat对象。
值
conf_mat() 生成一个具有类 conf_mat 的对象。它包含表和其他对象。 tidy.conf_mat() 生成一个包含列 name(单元格标识符)和 value(单元格计数)的 tibble。
当用于分组 DataFrame 时, conf_mat() 返回一个包含组列的 tibble 以及 conf_mat ,这是一个列表列,其中每个元素都是 conf_mat 对象。
细节
对于 conf_mat() 对象,创建了 broom tidy() 方法,该方法将单元格计数折叠到 DataFrame 中,以便于操作。
还有一个 summary() 方法可以同时计算各种分类指标。请参阅summary.conf_mat()
有一个ggplot2::autoplot() 方法可以快速可视化矩阵。热图和马赛克类型均已实现。
该函数要求因子具有完全相同的水平。
也可以看看
summary.conf_mat() 用于从一个混淆矩阵计算大量指标。
例子
library(dplyr)
data("hpc_cv")
# The confusion matrix from a single assessment set (i.e. fold)
cm <- hpc_cv %>%
filter(Resample == "Fold01") %>%
conf_mat(obs, pred)
cm
#> Truth
#> Prediction VF F M L
#> VF 166 33 8 1
#> F 11 71 24 7
#> M 0 3 5 3
#> L 0 1 4 10
# Now compute the average confusion matrix across all folds in
# terms of the proportion of the data contained in each cell.
# First get the raw cell counts per fold using the `tidy` method
library(tidyr)
cells_per_resample <- hpc_cv %>%
group_by(Resample) %>%
conf_mat(obs, pred) %>%
mutate(tidied = lapply(conf_mat, tidy)) %>%
unnest(tidied)
# Get the totals per resample
counts_per_resample <- hpc_cv %>%
group_by(Resample) %>%
summarize(total = n()) %>%
left_join(cells_per_resample, by = "Resample") %>%
# Compute the proportions
mutate(prop = value / total) %>%
group_by(name) %>%
# Average
summarize(prop = mean(prop))
counts_per_resample
#> # A tibble: 16 × 2
#> name prop
#> <chr> <dbl>
#> 1 cell_1_1 0.467
#> 2 cell_1_2 0.107
#> 3 cell_1_3 0.0185
#> 4 cell_1_4 0.00259
#> 5 cell_2_1 0.0407
#> 6 cell_2_2 0.187
#> 7 cell_2_3 0.0632
#> 8 cell_2_4 0.0173
#> 9 cell_3_1 0.00173
#> 10 cell_3_2 0.00692
#> 11 cell_3_3 0.0228
#> 12 cell_3_4 0.00807
#> 13 cell_4_1 0.000575
#> 14 cell_4_2 0.0104
#> 15 cell_4_3 0.0144
#> 16 cell_4_4 0.0320
# Now reshape these into a matrix
mean_cmat <- matrix(counts_per_resample$prop, byrow = TRUE, ncol = 4)
rownames(mean_cmat) <- levels(hpc_cv$obs)
colnames(mean_cmat) <- levels(hpc_cv$obs)
round(mean_cmat, 3)
#> VF F M L
#> VF 0.467 0.107 0.018 0.003
#> F 0.041 0.187 0.063 0.017
#> M 0.002 0.007 0.023 0.008
#> L 0.001 0.010 0.014 0.032
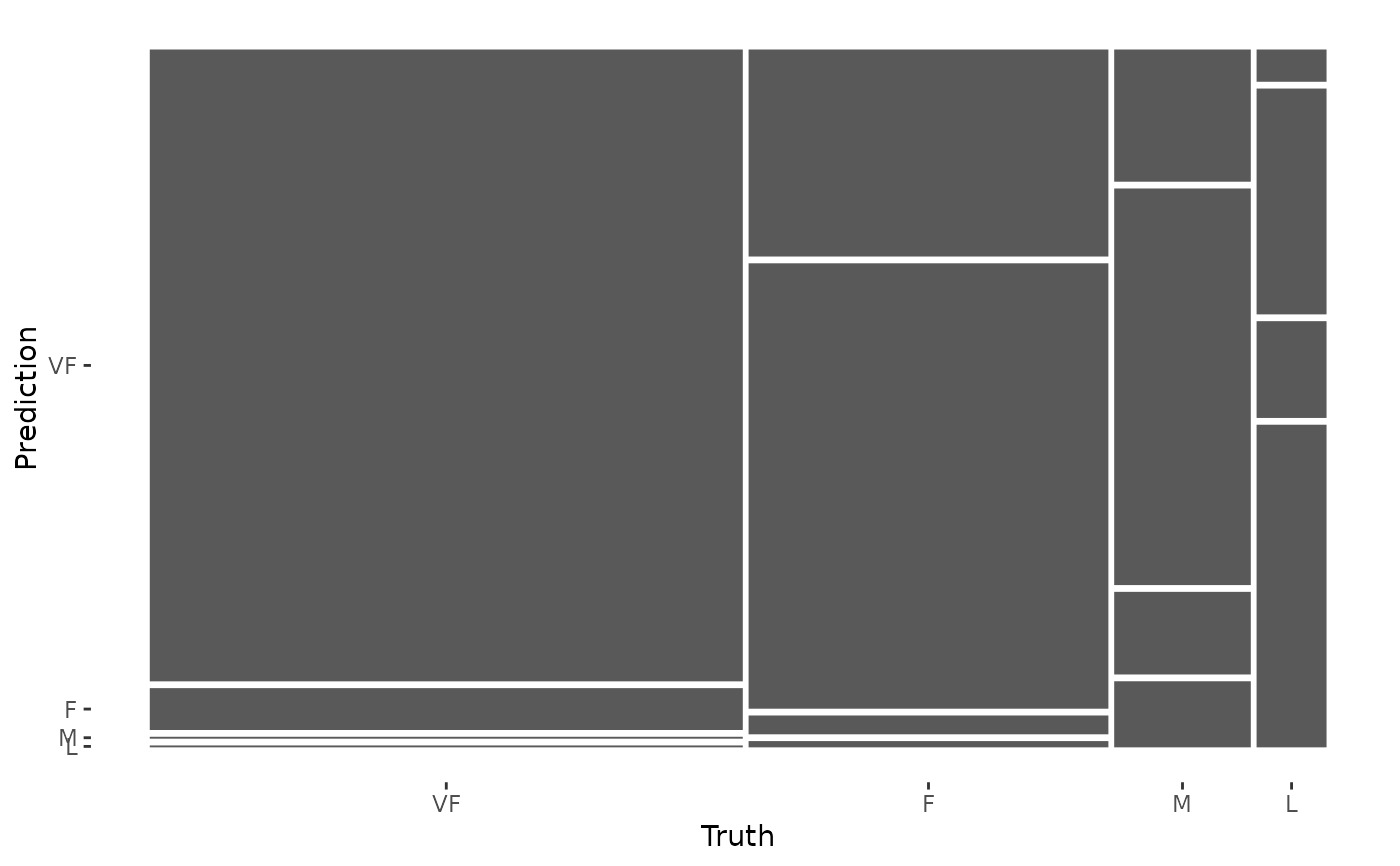
# The confusion matrix can quickly be visualized using autoplot()
library(ggplot2)
autoplot(cm, type = "mosaic")
 autoplot(cm, type = "heatmap")
autoplot(cm, type = "heatmap")

相关用法
- R yardstick ccc 一致性相关系数
- R yardstick classification_cost 不良分类的成本函数
- R yardstick pr_auc 查准率曲线下面积
- R yardstick accuracy 准确性
- R yardstick gain_capture 增益捕获
- R yardstick pr_curve 精确率召回曲线
- R yardstick mn_log_loss 多项数据的平均对数损失
- R yardstick rpd 性能与偏差之比
- R yardstick mae 平均绝对误差
- R yardstick detection_prevalence 检测率
- R yardstick bal_accuracy 平衡的精度
- R yardstick rpiq 绩效与四分位间的比率
- R yardstick roc_aunp 使用先验类别分布,每个类别相对于其他类别的 ROC 曲线下面积
- R yardstick roc_curve 接收者算子曲线
- R yardstick rsq R 平方
- R yardstick msd 平均符号偏差
- R yardstick mpe 平均百分比误差
- R yardstick iic 相关性理想指数
- R yardstick recall 记起
- R yardstick roc_aunu 使用均匀类别分布,每个类别相对于其他类别的 ROC 曲线下面积
- R yardstick npv 阴性预测值
- R yardstick rmse 均方根误差
- R yardstick sens 灵敏度
- R yardstick rsq_trad R 平方 - 传统
- R yardstick poisson_log_loss 泊松数据的平均对数损失
注:本文由纯净天空筛选整理自Max Kuhn等大神的英文原创作品 Confusion Matrix for Categorical Data。非经特殊声明,原始代码版权归原作者所有,本译文未经允许或授权,请勿转载或复制。