Python是进行数据分析的一种出色语言,主要是因为以数据为中心的python软件包具有奇妙的生态系统。 Pandas是其中的一种,使导入和分析数据更加容易。
Pandas TimedeltaIndex.value_counts()函数返回一个包含唯一值计数的对象。结果对象将按降序排列,因此第一个元素是最frequently-occurring元素。默认情况下不包括NA值。
用法: TimedeltaIndex.value_counts(normalize=False, sort=True, ascending=False, bins=None, dropna=True)
参数:
normalize:(布尔值,默认为False)如果为True,则返回的对象将包含唯一值的相对频率。
sort:(布尔值,默认为True)按值排序
ascending:(布尔值,默认为False)按升序排序
bins:(整数,可选)而不是对值进行计数,而是将它们分组为half-open bin,这是pd.cut的一种便利,仅适用于数字数据
dropna:(布尔值,默认为True)不包括NaN计数。
返回:数量:系列
范例1:采用TimedeltaIndex.value_counts()函数计算给定TimedeltaIndex对象中每个唯一值的出现。
# importing pandas as pd
import pandas as pd
# Create the TimedeltaIndex object
tidx = pd.TimedeltaIndex(data =['06:05:01.000030', '+23:59:59.999999',
'22 day 2 min 3us 10ns', '06:05:01.000030',
'+12:19:59.999999'])
# Print the TimedeltaIndex object
print(tidx)输出:

现在我们将使用TimedeltaIndex.value_counts()函数查找tidx对象中每个唯一值的出现次数。
# count occurrences
tidx.value_counts()输出:
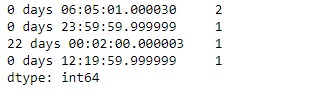
正如我们在输出中看到的,TimedeltaIndex.value_counts()函数已返回给定TimedeltaIndex对象中所有唯一值的计数。
范例2:采用TimedeltaIndex.value_counts()函数计算给定TimedeltaIndex对象中每个唯一值的出现。
# importing pandas as pd
import pandas as pd
# Create the TimedeltaIndex object
tidx = pd.TimedeltaIndex(data =['3 days 06:05:01.000030', '1 days 06:05:01.000030',
'3 days 06:05:01.000030', '1 days 06:05:01.000030',
'21 days 06:15:01.000030'])
# Print the TimedeltaIndex object
print(tidx)输出:

现在我们将使用TimedeltaIndex.value_counts()函数查找tidx对象中每个唯一值的出现次数。
# count occurrences
tidx.value_counts()输出:
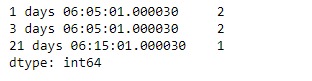
正如我们在输出中看到的,TimedeltaIndex.value_counts()函数已返回给定TimedeltaIndex对象中所有唯一值的计数。
相关用法
- Python pandas.map()用法及代码示例
- Python Pandas Timestamp.tz用法及代码示例
- Python Pandas Series.str.contains()用法及代码示例
- Python Pandas dataframe.std()用法及代码示例
- Python Pandas Timestamp.dst用法及代码示例
- Python Pandas dataframe.sem()用法及代码示例
- Python Pandas DataFrame.ix[ ]用法及代码示例
- Python Pandas.Categorical()用法及代码示例
- Python Pandas.apply()用法及代码示例
- Python Pandas TimedeltaIndex.contains用法及代码示例
- Python Pandas Timestamp.now用法及代码示例
- Python Pandas Series.str.pad()用法及代码示例
- Python Pandas Series.take()用法及代码示例
- Python Pandas dataframe.all()用法及代码示例
- Python Pandas series.str.get()用法及代码示例
注:本文由纯净天空筛选整理自Shubham__Ranjan大神的英文原创作品 Python | Pandas TimedeltaIndex.value_counts()。非经特殊声明,原始代码版权归原作者所有,本译文未经允许或授权,请勿转载或复制。