Python是进行数据分析的一种出色语言,主要是因为以数据为中心的python软件包具有奇妙的生态系统。 Pandas是其中的一种,使导入和分析数据更加容易。
Pandas dataframe.sum()函数返回所请求轴的值之和。如果输入是索引轴,则它将一列中的所有值相加,并对所有列重复相同的值,并返回一个包含每一列中所有值之和的序列。它还支持在计算数据帧中的总和时跳过数据帧中的缺失值。
用法:DataFrame.sum(axis=None, skipna=None, level=None, numeric_only=None, min_count=0, **kwargs)
参数:
axis:{索引(0),列(1)}
skipna:计算结果时排除NA /null值。
level:如果轴是MultiIndex(分层),则沿特定级别计数,并折叠为Series
numeric_only:仅包括float,int,boolean列。如果为None,将尝试使用所有内容,然后仅使用数字数据。未针对系列实施。
min_count:执行操作所需的有效值数量。如果存在少于min_count非NA值,则结果将为NA。
返回:sum:Series或DataFrame(如果指定级别)
要链接到代码中使用的CSV文件,请单击此处
范例1:采用sum()函数查找索引轴上所有值的总和。
# importing pandas as pd
import pandas as pd
# Creating the dataframe
df = pd.read_csv("nba.csv")
# Print the dataframe
df
现在找到沿索引轴的所有值的总和。我们将跳过NaN计算总和中的值。
# finding sum over index axis
# By default the axis is set to 0
df.sum(axis = 0, skipna = True)输出:
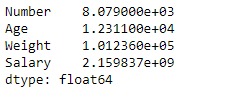
范例2:采用sum()函数查找列轴上所有值的总和。
现在我们将沿着列轴求和。我们将skipna设置为true。如果我们不跳过NaN值,它将导致NaN值。
# importing pandas as pd
import pandas as pd
# Creating the dataframe
df = pd.read_csv("nba.csv")
# sum over the column axis.
df.sum(axis = 1, skipna = True)输出:
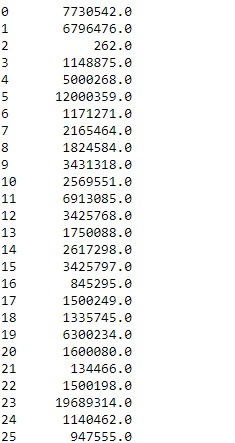
相关用法
- Python pandas.map()用法及代码示例
- Python Pandas Timestamp.tz用法及代码示例
- Python Pandas Series.str.contains()用法及代码示例
- Python Pandas dataframe.std()用法及代码示例
- Python Pandas Timestamp.dst用法及代码示例
- Python Pandas dataframe.sem()用法及代码示例
- Python Pandas DataFrame.ix[ ]用法及代码示例
- Python Pandas.Categorical()用法及代码示例
- Python Pandas.apply()用法及代码示例
- Python Pandas TimedeltaIndex.contains用法及代码示例
- Python Pandas Timestamp.now用法及代码示例
- Python Pandas Series.str.pad()用法及代码示例
- Python Pandas Series.take()用法及代码示例
- Python Pandas dataframe.all()用法及代码示例
- Python Pandas series.str.get()用法及代码示例
注:本文由纯净天空筛选整理自Shubham__Ranjan大神的英文原创作品 Python | Pandas dataframe.sum()。非经特殊声明,原始代码版权归原作者所有,本译文未经允许或授权,请勿转载或复制。