Python是进行数据分析的一种出色语言,主要是因为以数据为中心的python软件包具有奇妙的生态系统。 Pandas是其中的一种,使导入和分析数据更加容易。
Pandas reset_index()是一种重置数据帧索引的方法。 reset_index()方法将范围从0到数据长度的整数列表设置为索引。
用法:
DataFrame.reset_index(level=None, drop=False, inplace=False, col_level=0, col_fill=”)
参数:
level:int,字符串或列表以选择并从索引中删除传递的列。
drop:布尔值,如果为False,则将替换的索引列添加到数据中。
inplace:布尔值,如果为True,则对原始 DataFrame 本身进行更改。
col_level:选择在哪个列级别插入标签。
col_fill:对象,以确定如何命名其他级别。
返回类型: DataFrame
要下载使用的CSV文件,请单击此处。示例1:重置索引在此示例中,要重置索引,首先将“名字”列设置为索引列,然后使用重置索引生成新索引。
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("employees.csv")
# setting first name as index column
data.set_index(["First Name"], inplace = True,
append = True, drop = True)
# resetting index
data.reset_index(inplace = True)
# display
data.head()输出:
如输出图像中所示,已生成名为level_0的新索引标签。
重置之前-
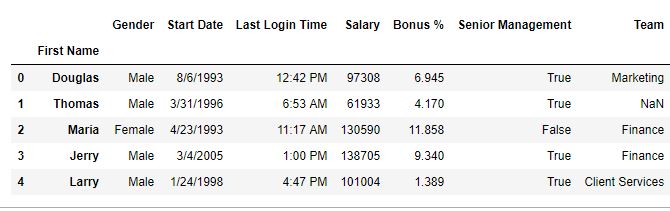
重置后-

范例2:多级索引操作
在本示例中,将2列(名字和性别)添加到索引列,然后使用reset_index()方法删除一个级别。
# importing pandas package
import pandas as pd
# making data frame from csv file
data = pd.read_csv("employees.csv")
# setting first name as index column
data.set_index(["First Name", "Gender"], inplace = True,
append = True, drop = True)
# resetting index
data.reset_index(level = 2, inplace = True, col_level = 1)
# display
data.head()输出:
如输出图像中所示,索引列中的“性别”列已被替换,因为其级别为2。
重置之前-
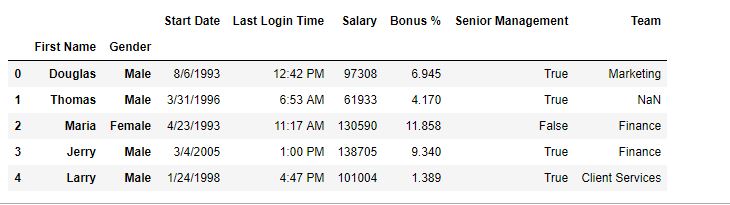
重置后-
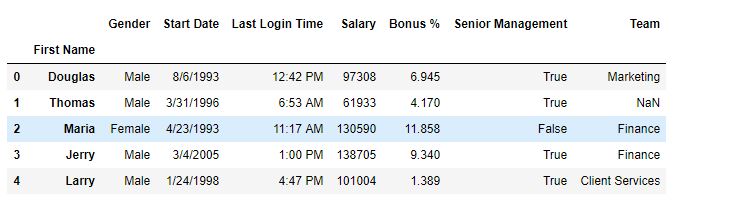
相关用法
- Python pandas.map()用法及代码示例
- Python Pandas Timestamp.tz用法及代码示例
- Python Pandas Series.str.contains()用法及代码示例
- Python Pandas dataframe.std()用法及代码示例
- Python Pandas Timestamp.dst用法及代码示例
- Python Pandas dataframe.sem()用法及代码示例
- Python Pandas DataFrame.ix[ ]用法及代码示例
- Python Pandas.Categorical()用法及代码示例
- Python Pandas.apply()用法及代码示例
- Python Pandas TimedeltaIndex.contains用法及代码示例
- Python Pandas Timestamp.now用法及代码示例
- Python Pandas Series.str.pad()用法及代码示例
- Python Pandas Series.take()用法及代码示例
- Python Pandas dataframe.all()用法及代码示例
- Python Pandas series.str.get()用法及代码示例
注:本文由纯净天空筛选整理自Kartikaybhutani大神的英文原创作品 Python | Pandas DataFrame.reset_index()。非经特殊声明,原始代码版权归原作者所有,本译文未经允许或授权,请勿转载或复制。