to_excel()方法用于将DataFrame导出到excel文件。要将单个对象写入excel文件,我们必须指定目标文件名。如果要写入多个工作表,则需要创建一个具有目标文件名的ExcelWriter对象,还需要在必须写入的文件中指定工作表。也可以通过指定唯一的sheet_name来写多张纸。必须保存所有写入文件的数据的更改。
用法:
data.to_excel( excel_writer, sheet_name='Sheet1', \*\*kwargs )
参数:
| 参数 | 类型 | 描述 |
|---|---|---|
| excel_writer | str或ExcelWriter对象 | 文件路径或现有的ExcelWriter |
| sheet_name | str,默认为“ Sheet1” | 包含DataFrame的工作表名称 |
| columns | str的序列或列表,可选 | 撰写专栏 |
| index | 布尔值,默认为True | 写行名(索引) |
| index_label | str或sequence,可选 | 索引列的列标签(如果需要)。如果未指定,并且`header`和`index`为True,则使用索引名。如果DataFrame使用MultiIndex,则应给出一个序列。 |
- 可以提供excel文件名或Excelwrite对象。
- 默认情况下,工作表编号为1,可以通过输入参数“sheet_name”的值进行更改。
- 可以通过输入参数“columns”的值来提供存储数据的列的名称。
- 默认情况下,索引标记为数字0,1,2…,依此类推,可以通过传递参数“index”的值的列表序列来更改索引。
下面是上述方法的实现:
Python3
# importing packages
import pandas as pd
# dictionary of data
dct = {'ID':{0:23, 1:43, 2:12,
3:13, 4:67, 5:89,
6:90, 7:56, 8:34},
'Name':{0:'Ram', 1:'Deep',
2:'Yash', 3:'Aman',
4:'Arjun', 5:'Aditya',
6:'Divya', 7:'Chalsea',
8:'Akash' },
'Marks':{0:89, 1:97, 2:45, 3:78,
4:56, 5:76, 6:100, 7:87,
8:81},
'Grade':{0:'B', 1:'A', 2:'F', 3:'C',
4:'E', 5:'C', 6:'A', 7:'B',
8:'B'}
}
# forming dataframe
data = pd.DataFrame(dct)
# storing into the excel file
data.to_excel("output.xlsx")输出:
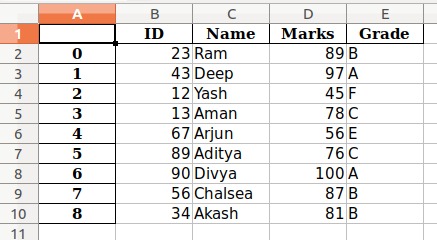
在以上示例中,
- 默认情况下,索引标记为0,1,…。等等。
- 由于我们的DataFrame具有列名,因此对列进行了标记。
- 默认情况下,它保存在“Sheet1”中。
相关用法
- Python Pandas.cut()用法及代码示例
- Python DataFrame.read_pickle()用法及代码示例
- Python pandas.date_range()用法及代码示例
- Python pandas.period_range()用法及代码示例
- Python pandas.to_numeric用法及代码示例
- Python Pandas Series.plot()用法及代码示例
- Python Pandas DataFrame.to_html()用法及代码示例
- Python Pandas Series.str.isspace()用法及代码示例
- Python Pandas Dataframe.describe()用法及代码示例
- Python Pandas DataFrame.to_latex()用法及代码示例
- Python pandas.to_markdown()用法及代码示例
注:本文由纯净天空筛选整理自deepanshu_rustagi大神的英文原创作品 DataFrame.to_excel() method in Pandas。非经特殊声明,原始代码版权归原作者所有,本译文未经允许或授权,请勿转载或复制。