先决条件: pd.to_pickle method()
read_pickle()方法用于将给定的对象腌制(序列化)到文件中。此方法使用以下语法:
用法:
pd.read_pickle(path, compression='infer')
参数:
| 参数 | 类型 | 描述 |
|---|---|---|
| path | str | 加载腌制对象的文件路径。 |
| compression | {‘infer’,‘gzip’,“ bz2”,‘zip’,‘xz’,无},默认值为‘infer’ | 对于on-the-fly,对on-disk数据进行解压缩。如果为‘infer’,则如果路径分别以“ .gz”,“。bz2”,“。xz”或“ .zip”结尾,则使用gzip,bz2,xz或zip,否则不进行解压缩。设置为无不解压。 |
下面是上述方法的实现和一些示例:
范例1:
Python3
# importing packages
import pandas as pd
# dictionary of data
dct = {'ID':{0:23, 1:43, 2:12,
3:13, 4:67, 5:89,
6:90, 7:56, 8:34},
'Name':{0:'Ram', 1:'Deep',
2:'Yash', 3:'Aman',
4:'Arjun', 5:'Aditya',
6:'Divya', 7:'Chalsea',
8:'Akash' },
'Marks':{0:89, 1:97, 2:45, 3:78,
4:56, 5:76, 6:100, 7:87,
8:81},
'Grade':{0:'B', 1:'A', 2:'F', 3:'C',
4:'E', 5:'C', 6:'A', 7:'B',
8:'B'}
}
# forming dataframe
data = pd.DataFrame(dct)
# using to_pickle function to form file
# with name 'pickle_file'
pd.to_pickle(data,'./pickle_file.pkl')
# unpickled the data by using the
# pd.read_pickle method
unpickled_data = pd.read_pickle("./pickle_file.pkl")
print(unpickled_data)输出:
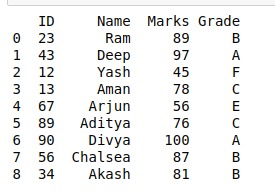
范例2:
Python3
# importing packages
import pandas as pd
# dictionary of data
dct = {"f1":range(6), "b1":range(6, 12)}
# forming dataframe
data = pd.DataFrame(dct)
# using to_pickle function to form file
# with name 'pickle_data'
pd.to_pickle(data,'./pickle_data.pkl')
# unpickled the data by using the
# pd.read_pickle method
unpickled_data = pd.read_pickle("./pickle_data.pkl")
print(unpickled_data)输出:
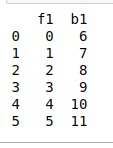
注:本文由纯净天空筛选整理自 DataFrame.read_pickle() method in Pandas。非经特殊声明,原始代码版权归原作者所有,本译文未经允许或授权,请勿转载或复制。