问题陈述
目标是通过使用线性回归技术进行统计推断预测,使用来自论文“(1977) Narula and Wellington, Prediction, Linear Regression and the Minimum Sum of Relative Errors, Technometrics””的数据。这个数据集为每个待预测变量(有11个不同的待预测变量)和响应变量给出了28个数据。数据见表1:
为简单起见分析中将不包括预测变量x2,x9,x10和x11。在此数据中,变量对应于:
x1= Taxes (税收) x6= # of rooms (房间数)
x3= Lot size (房屋面积) x7= # of bedrooms (卧室数量)
x4= Living space (居住面积) x8= Age of the home (房龄)
x5= # of garages (车库数) y = Sale price of the home (房价)
数据结构
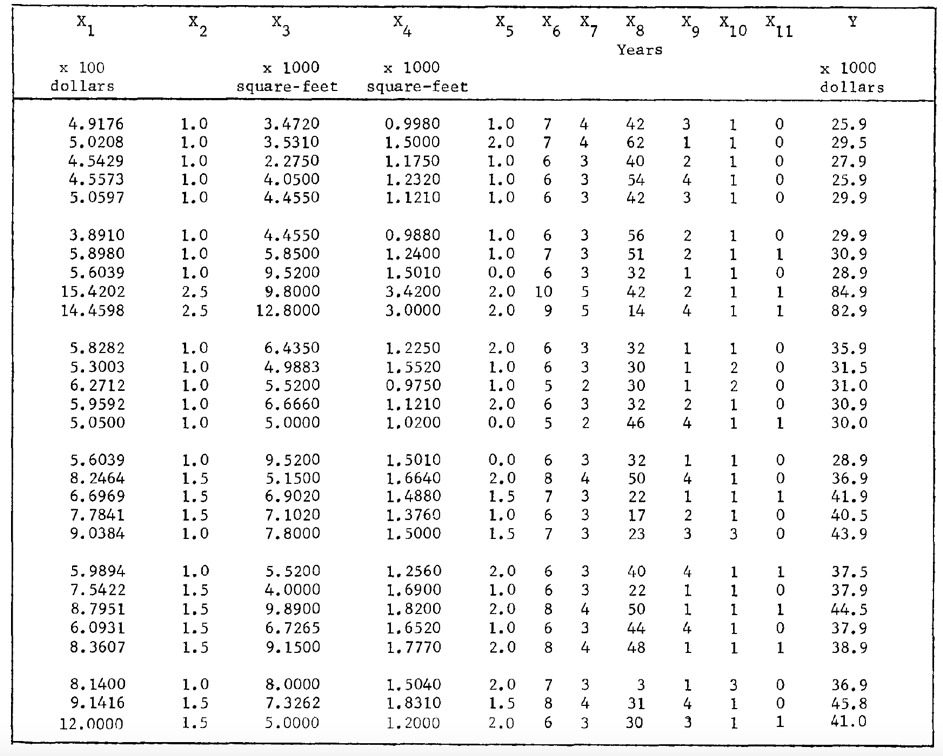
首先,要分析数据并查看自变量彼此之间的相关性以及与因变量的相关性,可以使用g-plot矩阵。
COMMENT ON MATLAB
data = table(observations(:, 1), observations(:, 2), observations(:, 3),...
observations(:, 4),observations(:, 5),observations(:, 6),...
observations(:, 7),observations(:, 8),'VariableNames', ...
{'x1', 'x3', 'x4', 'x5', 'x6', 'x7','x8','y'});
gplotmatrix([data.x1 data.x3 data.x4 data.x5 data.x6 data.x7 data.x8 data.y]);
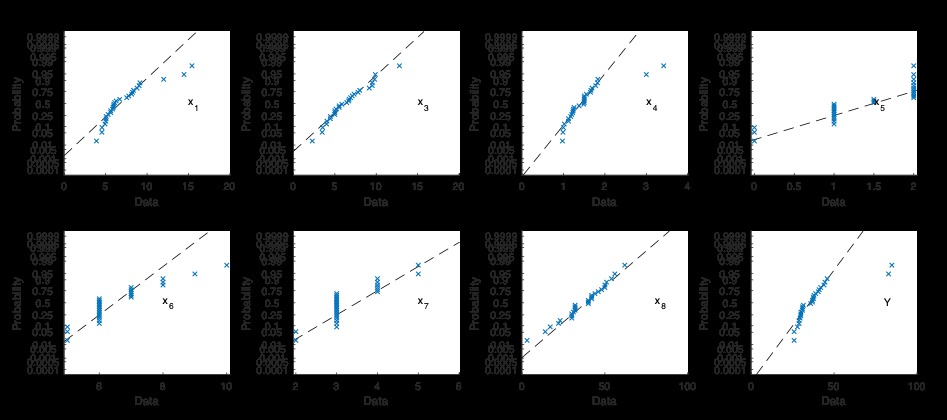
待预测变量和响应变量的分布及其关系可以在图1中看到。图中的每个单独的轴都包括以y轴标记的变量与以x轴标记的变量的散点图。对角线子图显示各个变量的直方图,而反对角线子图显示其相对关系。即左上子组显示x1预测变量的直方图,而左上方的第二个显示x1预测变量对x3的散点图。从图来看,所有预测变量均是偏斜的且与正常情况相差甚远。在预测变量x1,x3,x4,x6和响应变量的概率分布中遇到right tail(请自行搜索分布的“右尾”)。预测变量x5采用确定的离散变量。可以说,这些预测变量和响应变量显示的是chi-square(卡方)分布行为,而不是高斯分布行为。另一方面,预测变量x8具有左偏分布。上述这些解释可以通过查看其正常概率图行为得到支持(图2)。
COMMENT ON MATLAB
subplot(2,4,1);probplot('normal',data.x1);text(15,0.05,'x_1')
subplot(2,4,2);probplot('normal',data.x3);text(15,0.05,'x_3')
subplot(2,4,3);probplot('normal',data.x4);text(3,0.05,'x_4')
subplot(2,4,4);probplot('normal',data.x5);text(1.5,0.05,'x_5')
subplot(2,4,5);probplot('normal',data.x6);text(8,0.05,'x_6')
subplot(2,4,6);probplot('normal',data.x7);text(5,0.05,'x_7')
subplot(2,4,7);probplot('normal',data.x8);text(80,0.05,'x_8')
subplot(2,4,8);probplot('normal',data.y);text(80,0.05,'Y')
关于它们之间的关系,g-plot矩阵显示变量的二维图,因此从这些图中无法理解交互作用。这就是为什么推断可能具有欺骗性的原因。但是,乍一看,预测变量之间的关系可以解释如下:
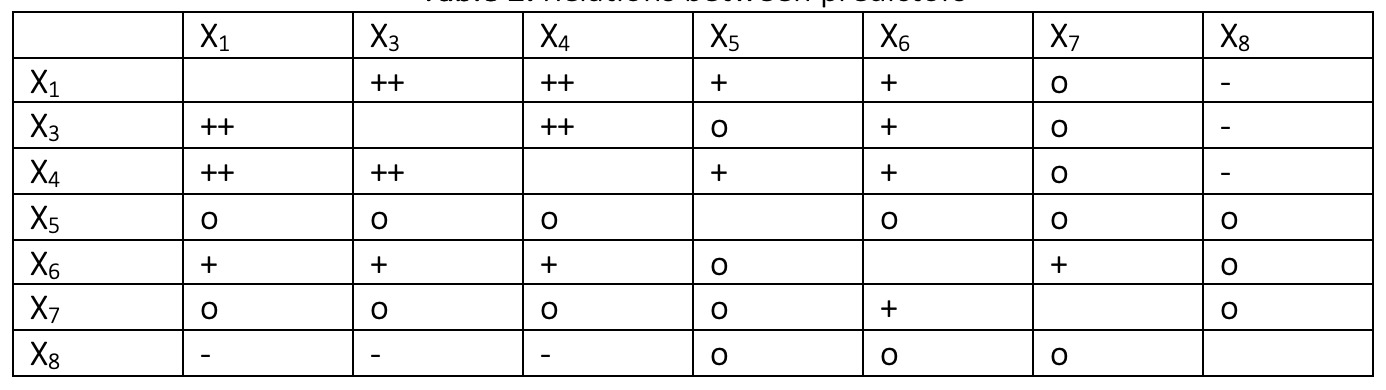
“ Double +”表示预测变量之间可能存在很强的相关性,而“ +”表示可能存在弱相关性,因为数据是如此分散。例如,x1和x3,x1和x4,x3和x4之间可能存在很强的正相关性;而x1和x5,x1和x6,x3和x6,x4和x5,x4和x6之间可能存在弱正相关性。 “—”表示x8与x1,x3,x4之间可能存在弱的负相关性。 “ o”的符号表示相关的2D图是如此分散,很有可能是预测变量不相关。
如果我们看一下响应变量“ Y”与预测变量之间的关系,
- 响应变量与x1,x3和x4的预测变量之间存在很强的正相关性。
- 响应变量与x5,x6和x7的预测变量之间可能存在弱的正相关性。
- 响应变量和x8的预测变量之间可能存在弱的负相关性。
特别是,预测变量“x1”,“x3”和“x4”与响应变量密切相关。这是有道理的,因为它们分别表示“taxes”,“lot size”和“living space”。由于车库的数量(x5),房间的数量(x6)和卧室的数量(x7)也影响房屋的销售价格,因此这些预测变量与响应变量之间存在弱的正相关性。但是,主要影响似乎来自税收,土地面积和居住空间,这些因素比房屋的结构特性更为重要。房屋的年龄(x8)与售价之间的负相关性关系也合乎逻辑:相比旧房屋,人们更喜欢新房屋。
经验离群值检测
在单个预测变量空间以及由几个预测变量定义的多元空间中是否有任何离群点?可以如下分析:
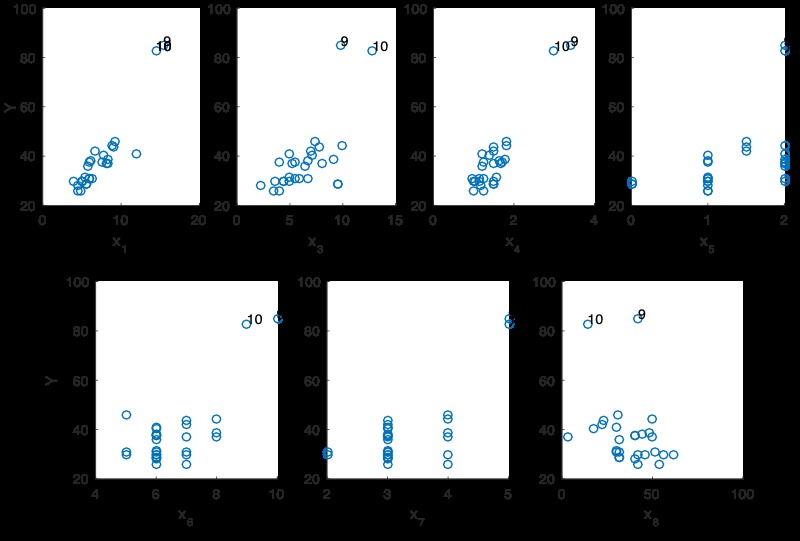
COMMENT ON MATLAB
subplot(2,4,1);scatter(data.x1, data.y);xlabel('x_1');ylabel('Y')
subplot(2,4,2);scatter(data.x3, data.y);xlabel('x_3');ylabel('Y')
subplot(2,4,3);scatter(data.x4, data.y);xlabel('x_4');ylabel('Y')
subplot(2,4,4);scatter(data.x5, data.y);xlabel('x_5');ylabel('Y')
subplot(2,4,5);scatter(data.x6, data.y);xlabel('x_6');ylabel('Y')
subplot(2,4,6);scatter(data.x7, data.y);xlabel('x_7');ylabel('Y')
subplot(2,4,7);scatter(data.x8, data.y);xlabel('x_8');ylabel('Y')我们可以使用3D散点图更好地查看这些关系。
COMMENT ON MATLAB
subplot(2,2,1)
scatter3(data.x1, data.x3, data.y, 50, 'ok', 'filled'), grid on
xlabel('x_1'), ylabel('x_3'), zlabel('Y');
subplot(2,2,2)
scatter3(data.x1, data.x4, data.y, 50, 'ok', 'filled'), grid on
xlabel('x_1'), ylabel('x_4'), zlabel('Y');
subplot(2,2,3)
scatter3(data.x3, data.x4, data.y, 50, 'ok', 'filled'), grid on
xlabel('x_3'), ylabel('x_4'), zlabel('Y');
subplot(2,2,4)
scatter3(data.x3, data.x8, data.y, 50, 'ok', 'filled'), grid on
xlabel('x_3'), ylabel('x_8'), zlabel('Y');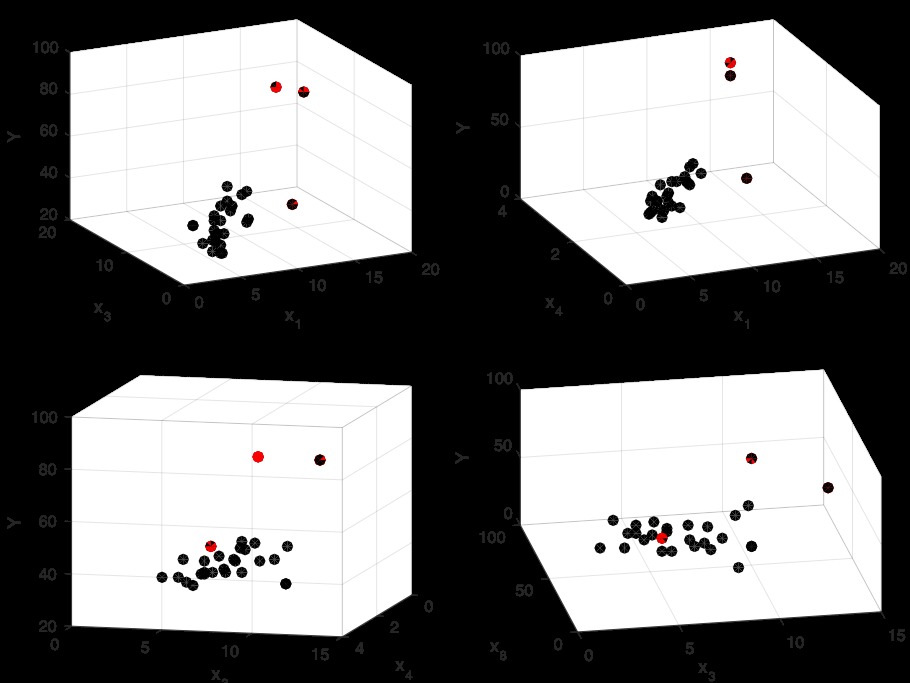
税收和房屋面积与响应变量之间呈正相关性。除此之外,看起来第9个点和第28个点是离群值,从二维散点图来看,也许第10点也可能被认为太离谱。
线性回归
在多元线性回归中,矩阵代数是常用的方法之一。对于模型;
线性回归的第一步
先构建了一个包含所有变量的线性回归模型。
COMMENT ON MATLAB
format bank
mdl1 = fitlm(data, 'y ~ x1 + x3 + x4 + x5 + x6 + x7 + x8')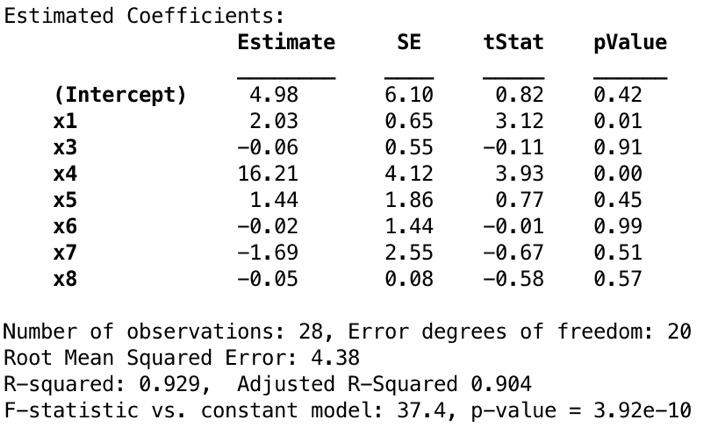
包括所有变量可以解释响应变量的方差,即R2和调整后的R2值相当高。从数据集中给出的所有预测变量中拟合线性模型(预测变量x2、x9、x10和x11除外)。根据上面先前定义的关系,可以预期估计的符号。作为线性模型的结果,如果假设拟合模型为真,则预测变量x1、x4、x5与响应变量Y之间将存在正相关性,而预测变量x3、x6、x7和x8之间将存在负相关性。回想一下g-plot矩阵的最后一行,该矩阵定义了预测变量与响应变量之间的关系。

尽管预计它与预测变量x3呈强正相关性关系,但估计符号显示出相对较弱的负相关关系。另外,响应变量与预测变量x6和x7之间的负相关性也令人惊讶。可以通过同时查看x3和x1、x4之间的强相关性来解释第一个意外结果。此外,如果消除了杠杆点,则预测变量x6可能与响应变量显示负相关性。 x6和x7之间的相关性可能导致正相关观测值的多重共线性。
预测变量的p值越小,说明响应变量的行为就越重要。如果我们看线性模型拟合结果,x4(居住面积)似乎更重要,那么它后面就是x1(税)。但是,其他预测变量的p值在0.40–1的范围内也很有意义,该值很高以至于无法确定重要的关系。这并不意味着其他预测变量(x1和x4除外)都不会对房屋的销售价格产生影响。首先,尽管每个预测变量具有不同的单位和尺度,但我们并未对数据集进行标准化。同样,单个p值在最后一刻添加模型时显示了预测变量的重要性,并且预测变量之间的相关性很容易影响p值。可以应用部分测试来更清楚地了解预测变量的重要性。因此,确定预测变量是否重要还为时过早!
每个预测变量的系数受其他变量的存在影响,即我们计算的p-values都是有条件的。当模型中已经存在其余变量时,预测变量的p-value表示通过添加该预测变量可以解释多少响应变量。因此,预测变量对响应变量的真实效应很容易被其他变量的效应以及预测变量之间的相关性所掩盖。我们可以通过查看方差膨胀因子(VIF)来检查多重共线性。 VIF表示由于共线性,估计系数增加了多少。相关矩阵逆矩阵的对角线为我们提供了每个预测变量的VIF。
COMMENT ON MATLAB
diag(inv(corr(x)))对于x1,x3,x4,x5,x6,x7和x8,结果分别为7.18、2.50、12.71、2.13、4.00、4.73、1.84和14.08。根据经验,VIF>10意味着具有多重共线性; x3和x8似乎与其他预测变量高度相关。我们可以得出结论,多重共线性是系数估计的结果符号令人惊讶的原因之一。
通过仅在1stmodel中添加重要变量x1和x4来创建模型。
COMMENT ON MATLABmdl2 = fitlm(data, 'y ~ x1 + x4')
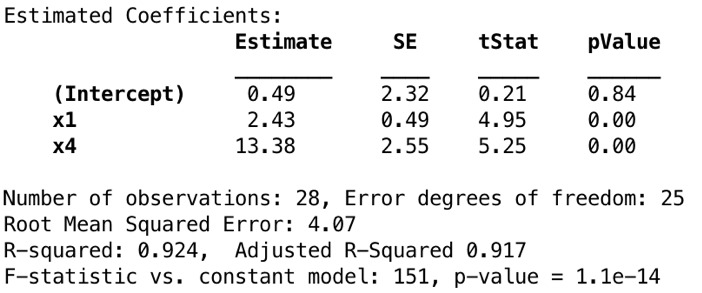
调整后的R2(0.904-> 0.917)和F-statistic(37.4-> 151)有所增加,而R2值几乎保持恒定。我们可以得出结论,税收x1和居住面积x4已经可以解释响应变量中的很多方差,而其他预测变量(例如x3和x8)似乎是不必要的。但是,我们永远无法真正确定p-values高的预测变量,最好不要做出任何判断。大于0.05的p-value不一定意味着应该从模型中删除该系数,因为可能会掩盖真实的效果。
为了了解其他预测变量的意义,我们可以应用F-test。现在的问题是:预测变量x3(房屋面积),x5(车库数),x6(房间数),x7(卧室数)和x8(房屋年龄)是否对房价变化做出了贡献(多个变量一起,而不是一一考虑) !)
F统计进行部分测试;
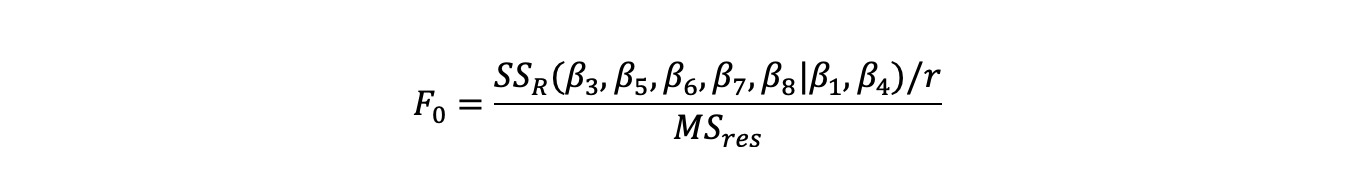
对1stand 2ndmodel进行比较,MATLAB代码如下:
COMMENT ON MATLAB
SSR1 = mdl1.SSR
SSR2 = mdl2.SSR
MSres1 = sum(mdl1.Residuals.Raw.^2)/(mdl.NumObservations-8)
Fpartial = (SSR1-SSR2)/5/MSres1
COMMENT ON MATLABmdl3 = fitlm(data, 'y ~ x1 + x4 + x1^2 + x4^2 + x1:x4')

尽管二次预测变量看起来很重要,但它们掩盖了预测变量本身的重要性。为了简单起见,仅将这两个变量的相互作用添加到以下模型中。
COMMENT ON MATLABmdl5 = fitlm(data, 'y ~ x1 + x4 + x1:x4')
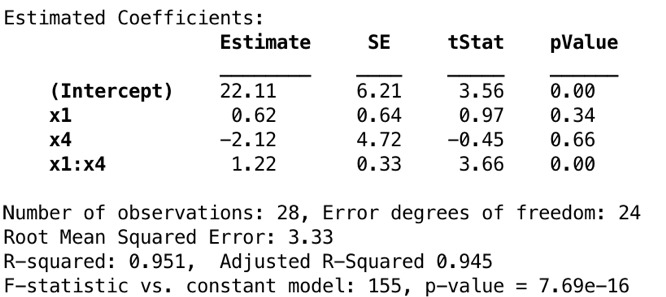
从图8可以看出,尽管模型诊断越来越好,但是包括x1和x4的交互项掩盖了x1和x4的显著影响。因此,现在我们考虑仅包含x1和x4预测变量的第二个模型。
控制杠杆点和影响点
首先,有人提到第9、10和28点可能是异常值。首先,他们的杠杆作用是;
COMMENT ON MATLABplotDiagnostics(mdl2,'leverage','MarkerSize',8,'Marker,'o','MarkerFaceColor','k')
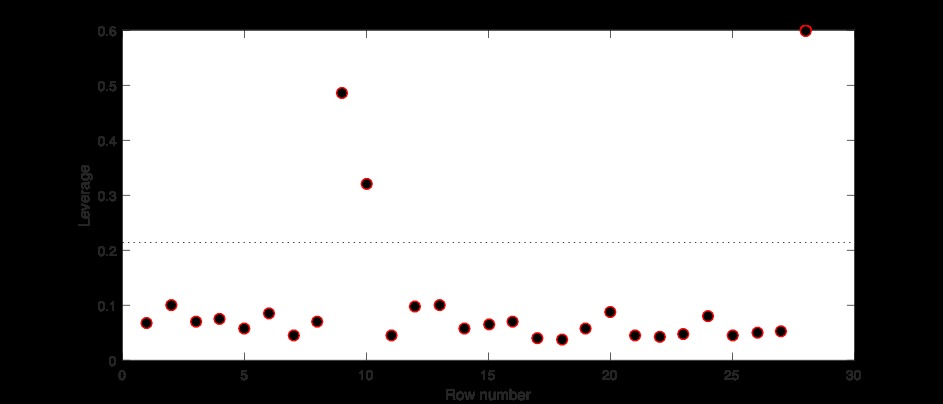
之前,当我们在预测变量的子空间x1,x2和x3中寻找杠杆点时,我们将第9、10和28个点确定为离群点。这些点的杠杆值是所有28个样本中最高的。无论他们是否有影响力,都将分析他们的库克距离( Cook’s distances )。
COMMENT ON MATLABplotDiagnostics(mdl2,'CookD','MarkerSize',8,'Marker,'o','MarkerFaceColor','r')

由于第10点和第28点可以同时视为杠杆和影响点,因此将它们从数据集中排除,然后重新考虑回归。
重新考虑线性回归
有影响的观察值是那些对回归模型的预测产生较大影响的观察结果。杠杆点是在独立变量的极值或偏值处进行的那些观察值(如果有的话),以致缺少相邻观察值意味着拟合的回归模型将通过该特定观察值。由于第10点和第28点是有影响力的点,因此将从数据集中丢弃它们,并再次考虑回归。
COMMENT ON MATLAB
obs = observations;
obs([10 28],:) = [];
data = table(obs(:, 1), obs(:, 2), obs (:, 3),obs (:, 4),obs (:, 5),...
obs (:, 6),obs (:, 7),obs (:, 8),'VariableNames',{'x1', 'x3', 'x4', 'x5',...'x6', 'x7','x8','y'});
corr ([data.x1 data.x3 data.x4 data.x5 data.x6 data.x7 data.x8 data.y]);相关矩阵如下:
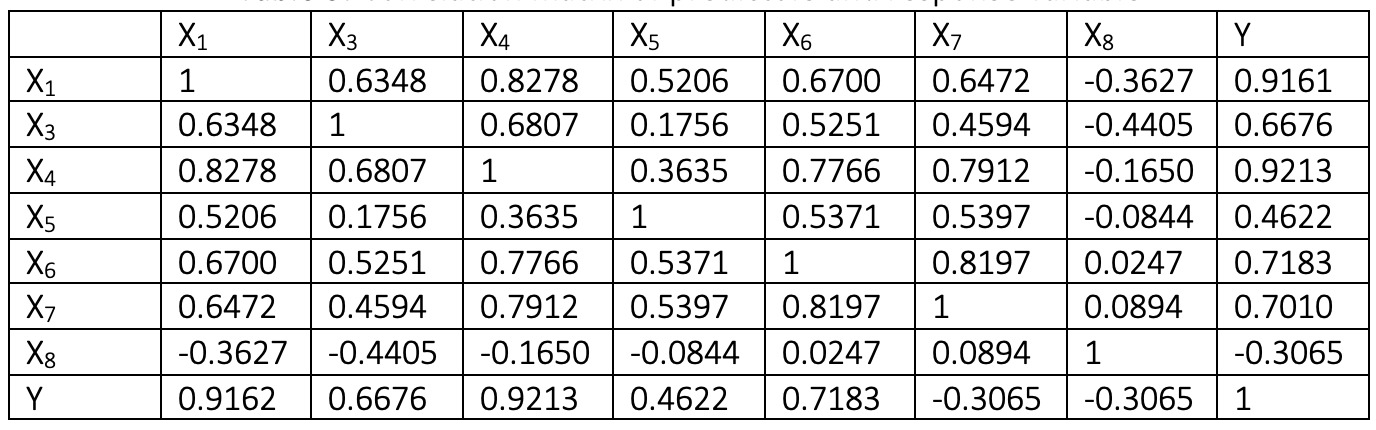
相关矩阵为我们提供了预测变量之间的相关性以及具有响应变量的预测变量的个体相关性。对于线性回归,不希望包括线性相关的预测变量。为此,一些降维技术用于变换预测变量。可以看出,预测变量彼此高度相关,并且它们与响应变量(尤其是x1和x4)显著相关。首先,将所有预测变量添加到回归模型中。
COMMENT ON MATLAB
format bank
mdl6 = fitlm(data, 'y ~ x1 + x3 + x4 + x5 + x6 + x7 + x8')
尽管该模型具有较高的R2值,但当涉及其p-values时,有许多无关紧要的预测变量。可能有两个原因:预测变量之间可能存在多重共线性,和/或某些预测变量可能需要转换。我们确信多重共线性,但对变换一无所知。为了进行检查,为每个预测变量绘制残差。
COMMENT ON MATLAB
subplot(2,4,1);stem(data.x1, mdl6.Residuals.Raw);xlabel('x_1');
subplot(2,4,2);stem(data.x3, mdl6.Residuals.Raw);xlabel('x_3');
subplot(2,4,3);stem(data.x4, mdl6.Residuals.Raw);xlabel('x_4');
subplot(2,4,4);stem(data.x5, mdl6.Residuals.Raw);xlabel('x_5');
subplot(2,4,5);stem(data.x6, mdl6.Residuals.Raw);xlabel('x_6');
subplot(2,4,6);stem(data.x7, mdl6.Residuals.Raw);xlabel('x_7');
subplot(2,4,7);stem(data.x8, mdl6.Residuals.Raw);xlabel('x_8');
subplot(2,4,1);plotAdjustedResponse(mdl6,'x1')
subplot(2,4,2);plotAdjustedResponse(mdl6,'x3')
subplot(2,4,3);plotAdjustedResponse(mdl6,'x4')
subplot(2,4,4);plotAdjustedResponse(mdl6,'x5')
subplot(2,4,5);plotAdjustedResponse(mdl6,'x6')
subplot(2,4,6);plotAdjustedResponse(mdl6,'x7')
subplot(2,4,7);plotAdjustedResponse(mdl6,'x8')
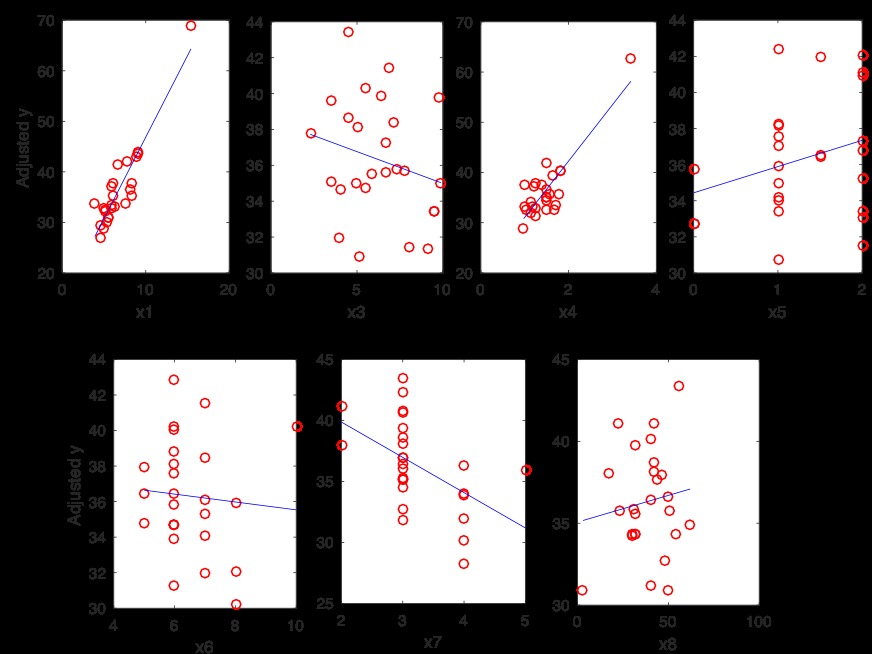
调整后的响应图显示拟合的响应,其他预测变量通过对拟合中使用的数据上的拟合值求平均值得到。通过将残差加到每个观察值的调整拟合值中来计算调整数据点。由于调整后的数据点的方差随着x6的增加而变得越来越小,因此将x6的指数变换(而不是x6本身)添加到模型中,并在MATLAB上应用逐步回归注释。前向回归的步骤如下:
COMMENT ON MATLAB
mdl7 = stepwiselm(data)1.加x1,FStat = 192.099,pValue = 5.99118e-13
2.加x6,FStat = 12.5889,pValue = 0.00171456
3.添加x1:x6,FStat = 5.4006,pValue = 0.029761
结果模型如下:
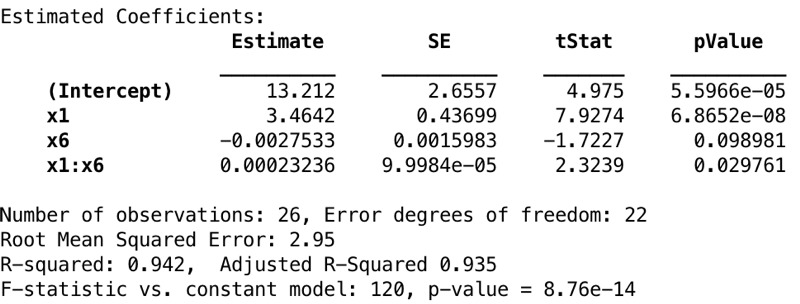
与包含x1和x4的模型进行比较时,R2和调整后的R2值显著增加。因为x4和x6是居住面积和房间数,所以它们是高度相关的。
模型充足性检查
图14显示了beta估计值及其标准误; t统计信息和P-values。低P-values显示了预测变量的重要性。可以看出,模型中给出的所有预测变量都非常重要。 R2和调整后的R2值表明,该模型具有很高的解释方差的能力。当涉及到F统计量为120时,这是很高的,构造的假设检验如下:
零假设:intercept-only模型与您的模型的拟合度相等。
替代假设:与您的模型相比,intercept-only模型的拟合显著降低。
高F统计数据和低p-value显示该模型似乎很重要。
首先要检查模型是否合适,对残差进行分析。残差应呈正态分布,且无趋势。
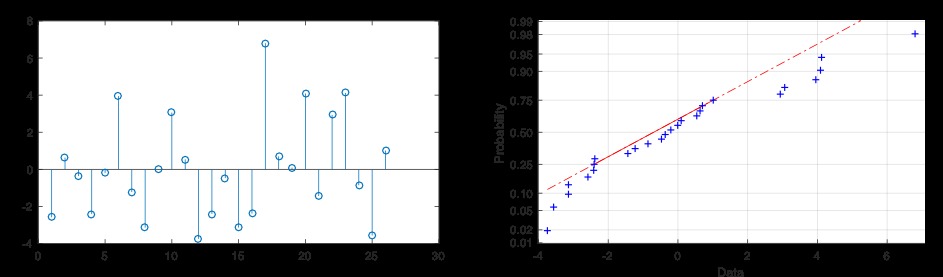
从图15可以看出,残差没有任何趋势,它们呈正态分布。正态概率图中显示的偏差源于数据集中的个体数量。
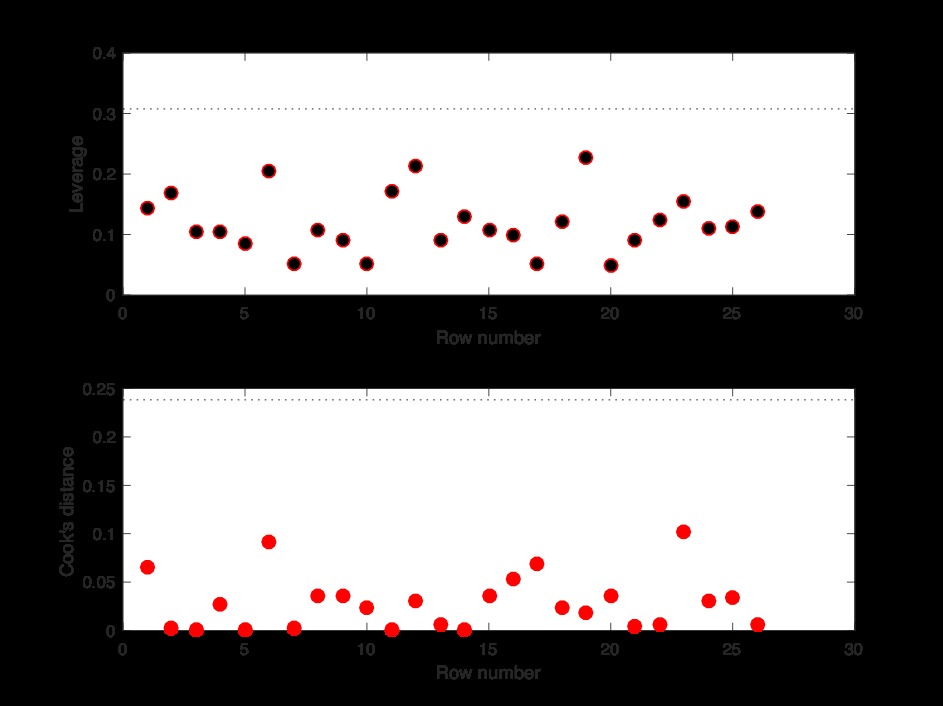
图16显示,数据集中不再有影响力和杠杆作用点。
结果
数据集包含对模型有重大影响的异常数据。清除异常值后,将按如下所示创建重要性模型:
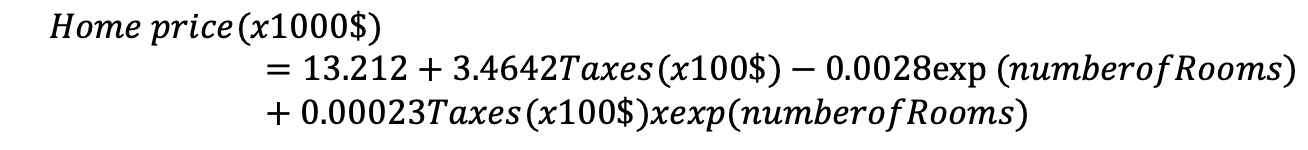
不出所料,税收增加房屋价格上涨。另一方面,房间数具有令人惊讶的负面影响,但是随着税收的增加,由于互动条件的影响,其影响转为正关系。房间数量的影响不是直接影响房价,而是成指数增长。
由于数据不是标准化的,因此无法相对确定影响的程度。