Apache Spark和Apache Store的区别是什么?他们各自适用于什么样的应用场景?这是stackoverflow上的一个问题,这里整理简要版回答如下:
Apache Spark是基于内存的分布式数据分析平台,旨在解决快速批处理分析任务、迭代机器学习任务、交互查询以及图处理任务。其最主要的特点在于,Spark使用了RDD或者说弹性分布式数据集。 RDD非常适合用于计算的流水线式并行操作。RDD的不变性(immutable)保证,使其具有很好的容错能力。如果您感兴趣的是更快地执行Hadoop MapReduce作业,Spark是一个很好的选项(虽然必须考虑内存要求)。Spark相对于hadoop MR来说,除了性能优势之外,还有大量丰富的API,这使得分布式编程更高效。
Spark架构图如下,总体结构非常简洁,没什么需要多说的,这里对spark的几个细节补充解读如下:
- 每个spark应用程序有自己的执行进程,进程以多线程的方式执行同一个应用的不同任务(tasks)。
- 因为不同的spark应用是不同进程,所以无论是在driver端还是executor端,不同用程序都是互相隔离的,在没有集群外存储的情况下,应用之间不能共享数据。
- Spark对底层集群管理器是不可知的。通常能做集群进程管理的容器,都可以管理spark程序。例如Mesos / YARN这样的集群管理也可以用于spark。当前在各大互谅网公司比较常用的就是基于yarn的spark。
- driver端必须在整个应用的生命周期内存在,并且是可寻址(固定在某个机器或者说IP上),因为executor都要跟driver建立连接并通讯。
- 由于是driver端来负责任务的调度(指应用具体操作的输入输出控制,区别于yarn的集群管理),所以driver端最好跟executor端最好在同一个局域网(比如同一个机房),从而避免远距离通信。实时上driver端即使不做大的返回集合collect的话,如果任务分片(partitions)很多,也会有大量通信开销。

Apache Storm专注于流处理或者一些调用复杂的事件处理。 Storm实现了一种容错方法,用于在事件流入系统时执行计算或流水线化多个计算。人们可以使用Storm在非结构化数据流入系统到期望的格式时对其进行转换。
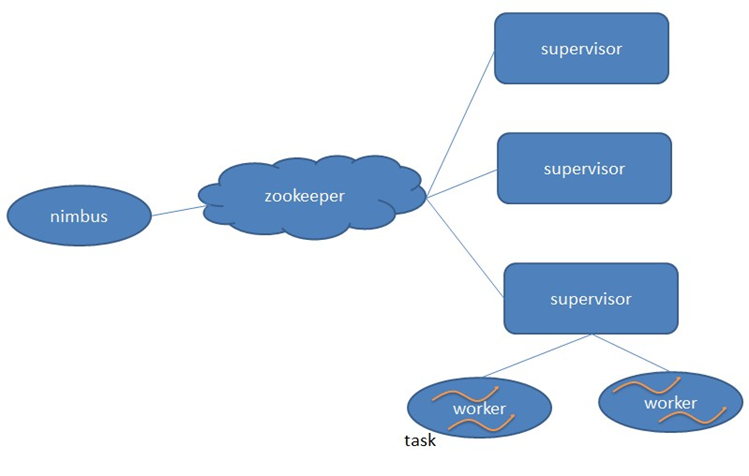
Storm的架构见下图,简单说明如下:
- Storm也采用Master/Slave体系结构。
-
分布式计算由Nimbus和Supervisor两类服务进程实现。
-
Nimbus进程运行在集群的主节点,负责任务的指派和分发。
-
Supervisor运行在集群的从节点,负责执行任务的具体部分。
Storm和Spark专注于相当不同的应用场景。对比Storm Trident和Spark Streaming,应该是更加公平(apples to apples)的比较。由于Spark的RDD本质上是不可变的,Spark Streaming实现了一种方法,用于在用户定义的时间间隔中“批处理”传入的更新,并将其转换为自己的RDD。 然后Spark通用的并行运算符就可以对这些RDD执行计算。这与Storm处理每个事件不同,Storm是真正的流式处理。
总而言之,这两种技术之间的一个主要区别是Spark执行数据并行计算,而Storm执行任务并行计算。这两种设计都是各自领域内的权衡,想了解更多可以参考下面的链接:
参考文献:
[1] http://stackoverflow.com/questions/24119897/apache-spark-vs-apache-storm
[2] spark官网:http://spark.apache.org/docs/latest/cluster-overview.html
[3] http://www.cnblogs.com/swanspouse/p/5135679.html