Apache Spark和Apache Store的區別是什麽?他們各自適用於什麽樣的應用場景?這是stackoverflow上的一個問題,這裏整理簡要版回答如下:
Apache Spark是基於內存的分布式數據分析平台,旨在解決快速批處理分析任務、迭代機器學習任務、交互查詢以及圖處理任務。其最主要的特點在於,Spark使用了RDD或者說彈性分布式數據集。 RDD非常適合用於計算的流水線式並行操作。RDD的不變性(immutable)保證,使其具有很好的容錯能力。如果您感興趣的是更快地執行Hadoop MapReduce作業,Spark是一個很好的選項(雖然必須考慮內存要求)。Spark相對於hadoop MR來說,除了性能優勢之外,還有大量豐富的API,這使得分布式編程更高效。
Spark架構圖如下,總體結構非常簡潔,沒什麽需要多說的,這裏對spark的幾個細節補充解讀如下:
- 每個spark應用程序有自己的執行進程,進程以多線程的方式執行同一個應用的不同任務(tasks)。
- 因為不同的spark應用是不同進程,所以無論是在driver端還是executor端,不同用程序都是互相隔離的,在沒有集群外存儲的情況下,應用之間不能共享數據。
- Spark對底層集群管理器是不可知的。通常能做集群進程管理的容器,都可以管理spark程序。例如Mesos / YARN這樣的集群管理也可以用於spark。當前在各大互諒網公司比較常用的就是基於yarn的spark。
- driver端必須在整個應用的生命周期內存在,並且是可尋址(固定在某個機器或者說IP上),因為executor都要跟driver建立連接並通訊。
- 由於是driver端來負責任務的調度(指應用具體操作的輸入輸出控製,區別於yarn的集群管理),所以driver端最好跟executor端最好在同一個局域網(比如同一個機房),從而避免遠距離通信。實時上driver端即使不做大的返回集合collect的話,如果任務分片(partitions)很多,也會有大量通信開銷。

Apache Storm專注於流處理或者一些調用複雜的事件處理。 Storm實現了一種容錯方法,用於在事件流入係統時執行計算或流水線化多個計算。人們可以使用Storm在非結構化數據流入係統到期望的格式時對其進行轉換。
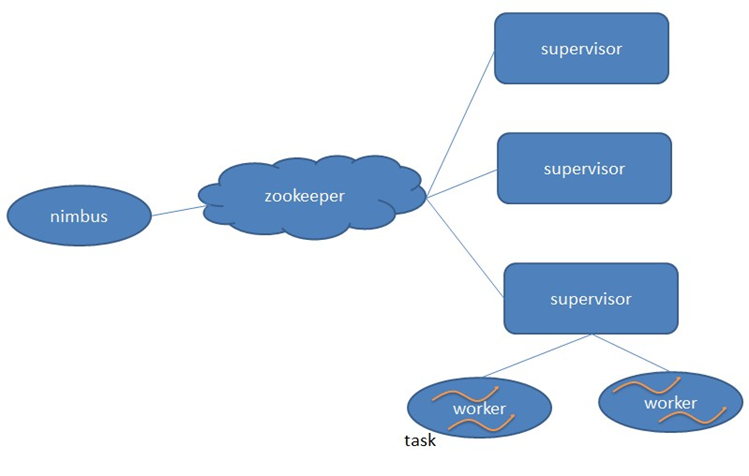
Storm的架構見下圖,簡單說明如下:
- Storm也采用Master/Slave體係結構。
-
分布式計算由Nimbus和Supervisor兩類服務進程實現。
-
Nimbus進程運行在集群的主節點,負責任務的指派和分發。
-
Supervisor運行在集群的從節點,負責執行任務的具體部分。
Storm和Spark專注於相當不同的應用場景。對比Storm Trident和Spark Streaming,應該是更加公平(apples to apples)的比較。由於Spark的RDD本質上是不可變的,Spark Streaming實現了一種方法,用於在用戶定義的時間間隔中“批處理”傳入的更新,並將其轉換為自己的RDD。 然後Spark通用的並行運算符就可以對這些RDD執行計算。這與Storm處理每個事件不同,Storm是真正的流式處理。
總而言之,這兩種技術之間的一個主要區別是Spark執行數據並行計算,而Storm執行任務並行計算。這兩種設計都是各自領域內的權衡,想了解更多可以參考下麵的鏈接:
參考文獻:
[1] http://stackoverflow.com/questions/24119897/apache-spark-vs-apache-storm
[2] spark官網:http://spark.apache.org/docs/latest/cluster-overview.html
[3] http://www.cnblogs.com/swanspouse/p/5135679.html