Spark作為一種通用且高性能的計算框架,不僅在性能上相對於hadoop mapreduce有了很大的提升;在易用性上也運超hadoop, 不隻提供了map/reduce計算接口,還提供了大量其他實用的接口,使得編寫分布式程序更加迅速高效。
Spark目前提供了Standalone/Yarn/Mesos幾種安裝模式,其中Standalone模式最為方便快捷。在這種模式下,Spark使用自由資源管理框架而不是借助Yarn或者Mesos。
下麵我們來看看如果快速安裝Spark Standalone.
1. 假設我們有4台機器,都是centos係統,上麵已經安裝了jdk和hadoop, 其中一台用做Master, 另外三台用作Worker。相關係統版本如下:
- Centos版本: 6.4, 假設安裝在/opt/java
- dk版本:jdk1.7.0_45
- hadoop版本: CDH 5(hadoop 2.3)
2. 下載對應的spark prebuild版本到Master機器,假設我們放在/home/spark目錄下。(文件有200M+,下載比較慢)。
wget http://d3kbcqa49mib13.cloudfront.net/spark-1.3.0-bin-hadoop2.3.tgz注意, 下載鏈接選擇的Direct Download,在Mirror模式直接wget貌似有點問題。
3. 在/home/spark/目錄下解壓spark-1.3.0-bin-hadoop2.3.tgz文件
tar xzvf spark-1.3.0-bin-hadoop2.3.tgz4. 修改配置,到spark-1.3.0-bin-hadoop2.3/conf目錄下,使用template創建配置文件(這裏隻考慮了最簡配置)
cp spark-env.sh.template spark-env.sh
cp slaves.template slaves- 在spark-env.sh中設置JAVA環境變量(不設置這個在啟動spark集群的時候可能會報錯 JAVA_HOME is not set):export JAVA_HOME=/opt/java
- 在slaves中設置三台worker機器的IP:
# A Spark Worker will be started on each of the machines listed below.
10.71.48.113
10.71.48.114
10.71.48.1155. 將修改好配置的目錄spark-1.3.0-bin-hadoop2.3打包成spark-1.3.0-bin-hadoop2.3.tgz
tar czvf spark-1.3.0-bin-hadoop2.3.tgz spark-1.3.0-bin-hadoop2.36. 將壓縮包從master拷貝到三台worker機器的/home/spark目錄並解壓,可以使用下麵的腳本批量操作:
#!/bin/bash
if [ $# -ne 0 ]
then
echo "Usage: $0"
exit 1
fi
username=root
dist_dir=/home/spark/
filename=spark-1.3.0-bin-hadoop2.3
ips=(10.71.48.113 10.71.48.114 10.71.48.115)
for ip in ${ips[@]}
do
echo "process ${ip} at ${dist_dir}"
ssh ${username}@${ip} "mkdir -p ${dist_dir}" 0</dev/null
scp ../${filename}.tgz ${username}@${ip}:${dist_dir}
ssh ${username}@${ip} "cd ${dist_dir} && tar xzvf ${filename}.tgz" 0</dev/null
done
exit 07. 到master機器的/home/spark/spark-1.3.0-bin-hadoop2.3
- 執行
./sbin/start-all.sh啟動集群。 - 執行
./sbin/stop-all.sh關閉集群
8. 安裝好之後,可以通過http://master-ip:8080/網頁可視化查看集群狀態。
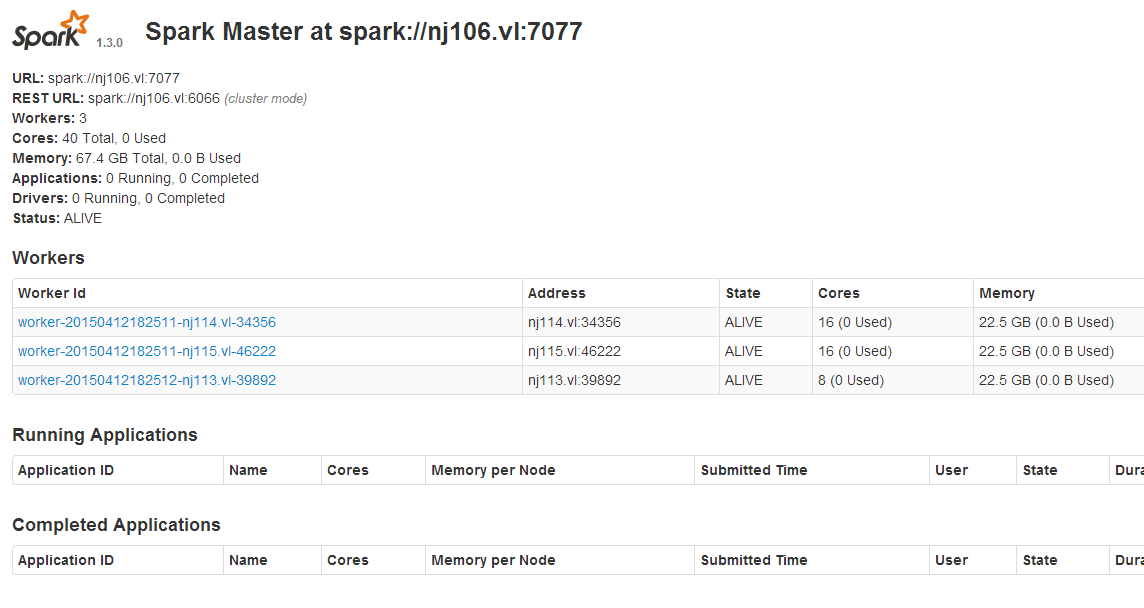
9. 測試spark程序,有兩種模式,以python語言為例(spark另外支持java/scala):
- shell交互模式, 執行
./bin/pyspark進入交互執行模式 ./bin/spark-submit --master spark://nj106.vl:7077 test.py可以提交test.py程序到集群執行。[不設置master,默認是local[*]模式]
#!/usr/bin/python
#coding=utf8
import sys;
from pyspark import SparkContext;
if __name__ == "__main__":
sc = SparkContext(appName="my-spark-test"); #創建SparkContext
file = sc.textFile("hdfs://10.71.48.106/data/fuqingchuan/dat.10W.txt"); #讀取hadoop文件
result = file.flatMap(lambda line : line.split("\t")).map(lambda word : (word, 1)).reduceByKey(lambda a, b: (a + b)); #word count
first_line = result.first(); #去RDD中的第一行
total_num = result.count(); #統計行數
print first_line;
print total_num;
result.saveAsTextFile("hdfs://10.71.48.106/data/fuqingchuan/spark-test/"); #保存結果數據到集群
sys.exit(0);【參考】http://spark.apache.org/docs/latest/spark-standalone.html