本文介绍两点:
1. 如何用Spark读取本文文件内容。
2. 如何用Spark将数据写到本地,特别是将大文件写到本地。
Spark读取本地文件内容
通常情况下,如果用下面的代码读取本地文件:
val data = sc.textFile("somefile.txt")直接这样写,系统有可能会报错,正确的读取方式:
var data = sc.textFile("file:///path to the file/")
原因:SparkContext.textFile内部调用了org.apache.hadoop.mapred.FileInputFormat.getSplits函数;当我们不设置textFile的文件模式的时候,getSplits函数又会调用org.apache.hadoop.fs.getDefaultUri;getDefaultUri这个函数从Hadoop配置中读取”fs.defaultFS”参数,这个参数通常会在HADOOP_CONF_DIR环境变量中设置为”hdfs://”, 而不是”file://”。”hdfs://”或者”file://”就是前面说的文件模式,如果textFile中不指定,则默认为”hdfs://”。
当然,将文件先拷贝到hdfs,再textFile也是个不错的选择,使用hdfs fs -put命令:
${HADOOP_COMMON_HOME}/bin/hadoop fs -put /localpath/to/data.txt /hdfspath/to/data.txt
或者,使用hdfs fs -copyFromLocal命令:
${HADOOP_COMMON_HOME}/bin/hadoop fs -copyFromLocal /localpath/to/data.txt /hdfspath/to/data.txt
Spark写/保存文件到本地
使用spark将hdfs上的文件保存到本地,如果文件较小,直接collect或者println都可以。如果文件较大,比如有好几个GB,就需要细致处理了,因为直接collect很可能会打爆spark driver内存。
spark写大文件到本地的正确方式应该是
1. 直接使用SparkAPI toLocalIterator(需要的本地最大内存等于最大分片占用内存):
val it = rdd.toLocalIterator
while(it.hasNext){
println(it.next)
}
2.或者遍历每个partitions,分别collect写到本地,自己写逻辑(原理同上,可以自己控制做过滤之类的操作)
val parts = rdd.partitions
for (p <- parts) {
val idx = p.index
val partRdd = rdd.mapPartitionsWithIndex(a => if (a._1 == idx) a._2 else Iterator(), true)
//The second argument is true to avoid rdd reshuffling
val data = partRdd.collect //data contains all values from a single partition
//in the form of array
//Now you can do with the data whatever you want: iterate, save to a file, etc.
}
跟读一样,写也可以先saveAsTextFile,然后使用hdfs命令存到本地, 使用hdfs fs -get命令:
${HADOOP_COMMON_HOME}/bin/hadoop fs -get /hdfspath/to/data.txt /localpath/to/data.txt
或者,使用hdfs fs -copyToLocal命令:
${HADOOP_COMMON_HOME}/bin/hadoop fs -copyToLocal /hdfspath/to/data.txt /localpath/to/data.txt
————————————————————————————————————————————————————————————————————————
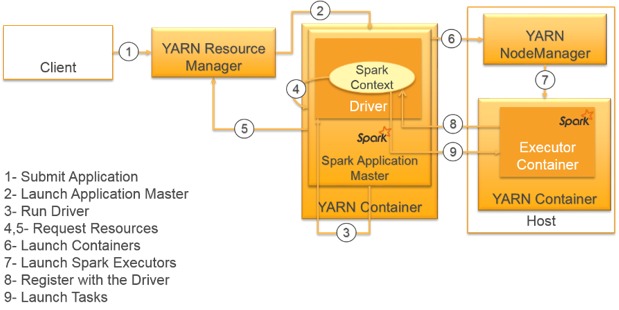
延伸阅读,附图:spark client模式,读写本地文件一般需要client模式。