fct_reorder() 對於將因子映射到位置的 1d 顯示很有用; fct_reorder2() 用於 2d 顯示器,其中該因子映射到非位置美學。 last2() 和 first2() 是 fct_reorder2() 的助手; last2() 查找按 x 排序後 y 的最後一個值; first2() 找到第一個值。
用法
fct_reorder(
.f,
.x,
.fun = median,
...,
.na_rm = NULL,
.default = Inf,
.desc = FALSE
)
fct_reorder2(
.f,
.x,
.y,
.fun = last2,
...,
.na_rm = NULL,
.default = -Inf,
.desc = TRUE
)
last2(.x, .y)
first2(.x, .y)參數
- .f
-
因子(或字符向量)。
- .x, .y
-
f的級別重新排序,以便.fun(.x)(對於fct_reorder())和fun(.x, .y)(對於fct_reorder2())的值按升序排列。 - .fun
-
n 匯總函數。它應該采用一個向量表示
fct_reorder,采用兩個向量表示fct_reorder2,並返回一個值。 - ...
-
其他參數傳遞給
.fun。 - .na_rm
-
fct_reorder()應該刪除缺失值嗎?如果NULL(默認值)將刪除缺失值並發出警告。設置為FALSE以保留NA(如果您.fun已處理它們)並設置為TRUE以靜默刪除。 - .default
-
對於空級別,我們應該為
.fun使用什麽默認值?使用它來控製輸出中出現空級別的位置。 - .desc
-
按降序排列?請注意,
fct_reorder和fct_reorder2之間的默認值不同,以便匹配圖例中因子的默認順序。
例子
# fct_reorder() -------------------------------------------------------------
# Useful when a categorical variable is mapped to position
boxplot(Sepal.Width ~ Species, data = iris)
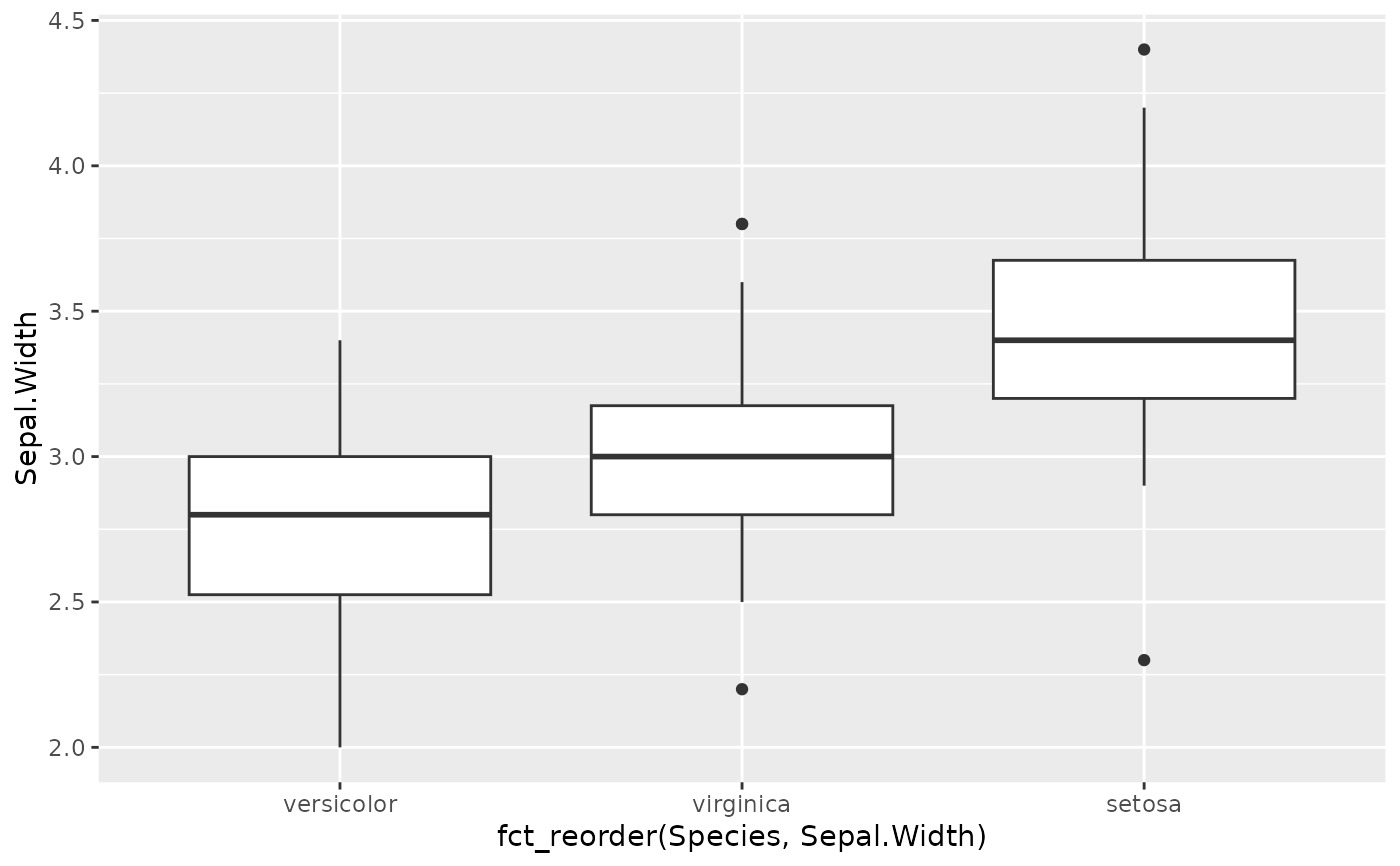
 boxplot(Sepal.Width ~ fct_reorder(Species, Sepal.Width), data = iris)
boxplot(Sepal.Width ~ fct_reorder(Species, Sepal.Width), data = iris)
 # or with
library(ggplot2)
ggplot(iris, aes(fct_reorder(Species, Sepal.Width), Sepal.Width)) +
geom_boxplot()
# or with
library(ggplot2)
ggplot(iris, aes(fct_reorder(Species, Sepal.Width), Sepal.Width)) +
geom_boxplot()
 # fct_reorder2() -------------------------------------------------------------
# Useful when a categorical variable is mapped to color, size, shape etc
chks <- subset(ChickWeight, as.integer(Chick) < 10)
chks <- transform(chks, Chick = fct_shuffle(Chick))
# Without reordering it's hard to match line to legend
ggplot(chks, aes(Time, weight, colour = Chick)) +
geom_point() +
geom_line()
# fct_reorder2() -------------------------------------------------------------
# Useful when a categorical variable is mapped to color, size, shape etc
chks <- subset(ChickWeight, as.integer(Chick) < 10)
chks <- transform(chks, Chick = fct_shuffle(Chick))
# Without reordering it's hard to match line to legend
ggplot(chks, aes(Time, weight, colour = Chick)) +
geom_point() +
geom_line()
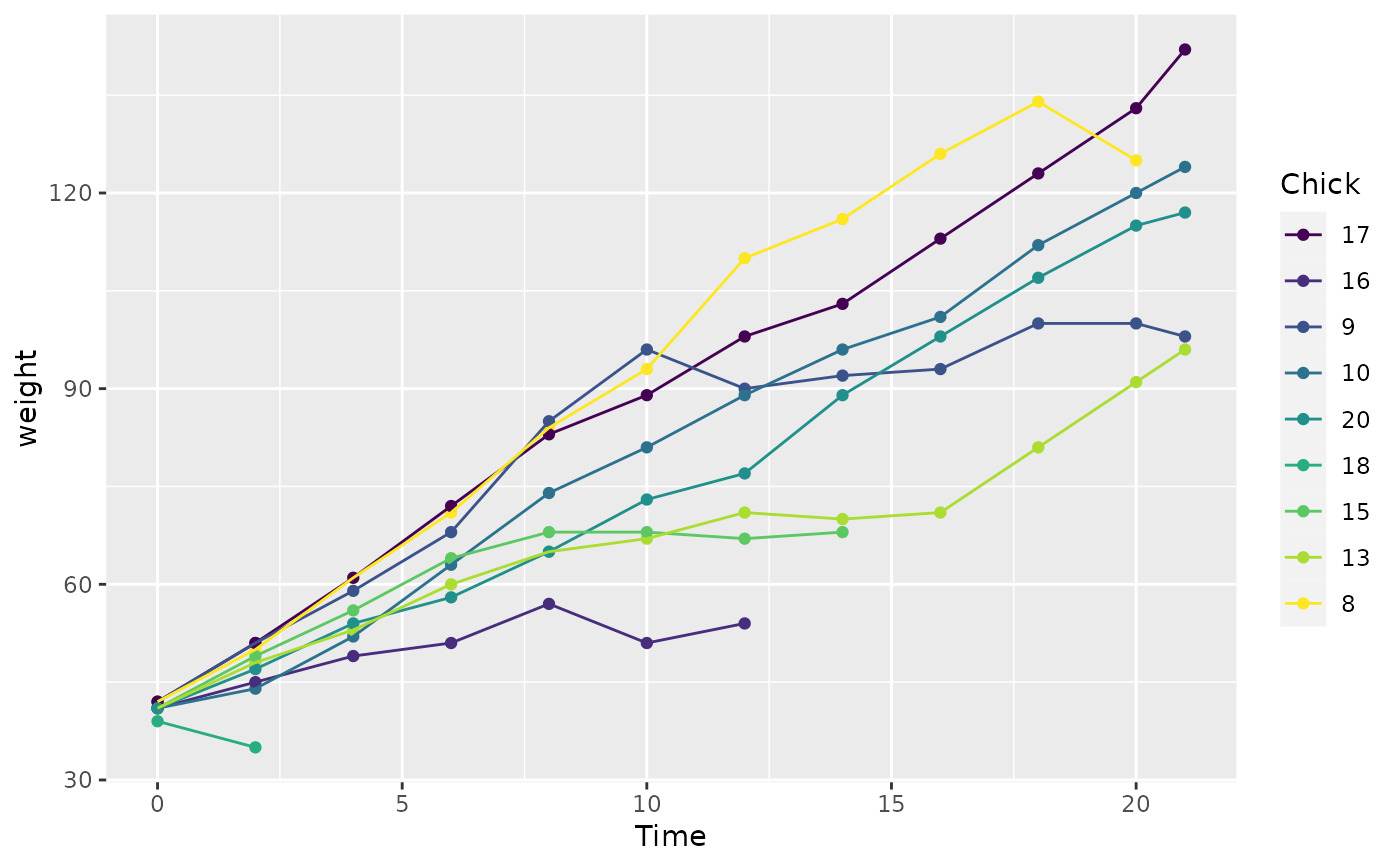 # With reordering it's much easier
ggplot(chks, aes(Time, weight, colour = fct_reorder2(Chick, Time, weight))) +
geom_point() +
geom_line() +
labs(colour = "Chick")
# With reordering it's much easier
ggplot(chks, aes(Time, weight, colour = fct_reorder2(Chick, Time, weight))) +
geom_point() +
geom_line() +
labs(colour = "Chick")
相關用法
- R forcats fct_relevel 手動重新排序因子級別
- R forcats fct_rev 因子水平的倒序
- R forcats fct_relabel 使用函數重新標記因子水平,並根據需要折疊
- R forcats fct_recode 手動更改因子水平
- R forcats fct_anon 匿名因子水平
- R forcats fct_inorder 按首次出現、頻率或數字順序對因子水平重新排序
- R forcats fct_match 測試因子中是否存在水平
- R forcats fct_drop 刪除未使用的級別
- R forcats fct_c 連接因子,組合級別
- R forcats fct_collapse 將因子級別折疊為手動定義的組
- R forcats fct_shuffle 隨機排列因子水平
- R forcats fct_cross 組合兩個或多個因子的水平以創建新因子
- R forcats fct_other 手動將級別替換為“其他”
- R forcats fct_na_value_to_level NA 值和 NA 水平之間的轉換
- R forcats fct_lump 將不常見因子集中到“其他”級別
- R forcats fct_unique 一個因子的唯一值,作為一個因子
- R forcats fct_shift 將因子水平向左或向右移動,在末尾環繞
- R forcats fct_unify 統一因子列表中的水平
- R forcats fct_count 計算因子中的條目數
- R forcats fct_expand 向因子添加附加級別
- R forcats fct 創建一個因子
- R forcats as_factor 將輸入轉換為因子
- R forcats lvls_union 查找因子列表中的所有級別
- R forcats lvls 用於操縱級別的低級函數
- R forcats gss_cat 一般社會調查中的分類變量樣本
注:本文由純淨天空篩選整理自Hadley Wickham等大神的英文原創作品 Reorder factor levels by sorting along another variable。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。