Pandas 索引是一個不變的ndarray,它實現了有序的,可切片的集合。它是存儲所有 Pandas 對象的軸標簽的基本對象。
Pandas Index.where函數返回與self形狀相同的Index,其對應項來自cond為True的self,否則為other。
用法: Index.where(cond, other=None)
參數:
cond:布爾array-like,其長度與self相同
other:標量或array-like
返回:指數
範例1:采用Index.where函數返回一個索引,如果該索引的值不小於100,則從另一個索引中選擇該值。
# importing pandas as pd
import pandas as pd
# Creating the first index
idx1 = pd.Index([900, 45, 21, 145, 38, 422])
# Creating the second index
idx2 = pd.Index([1100, 1200, 1300, 1400, 1500, 1600])
# Print the first index
print(idx1)
# Print the second index
print(idx2)輸出:
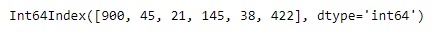
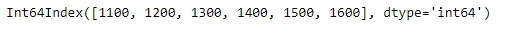
現在我們將使用Index.where函數返回一個索引,如果該索引的值不小於100,則從另一個索引中選擇該值。
# return the new index based on the condition
result = idx1.where(idx1 < 100, idx2)
# Print the result
print(result)輸出:
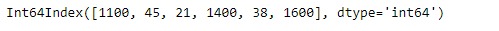
正如我們在輸出中看到的,Index.where函數已成功返回滿足傳遞條件的Index對象。
範例2:采用Index.where函數返回滿足傳遞條件的索引。
# importing pandas as pd
import pandas as pd
# Creating the first index
idx1 = pd.Index([900, 45, 21, 145, 38, 422])
# Creating the second index
idx2 = pd.Index([1100, 1200, 1300, 1400, 1500, 1600])
# Print the first index
print(idx1)
# Print the second index
print(idx2)輸出:
現在我們將使用Index.where函數返回一個索引,如果其他索引的值減去1200不小於idx1,我們從另一個索引中選擇值。
# return the new index based on the condition
result = idx1.where((idx2 - 1200) < idx1, idx2)
# Print the result
print(result)輸出:

正如我們在輸出中看到的,Index.where函數已成功返回滿足傳遞條件的Index對象。
相關用法
- Python pandas.map()用法及代碼示例
- Python Pandas Panel.pow()用法及代碼示例
- Python Pandas Panel.div()用法及代碼示例
- Python Pandas Series.mul()用法及代碼示例
- Python Pandas DataFrame.ix[ ]用法及代碼示例
- Python Pandas Series.sub()用法及代碼示例
- Python Pandas Series.add()用法及代碼示例
- Python Pandas TimedeltaIndex.contains用法及代碼示例
- Python Pandas dataframe.mean()用法及代碼示例
- Python Pandas.melt()用法及代碼示例
- Python Pandas Timestamp.dst用法及代碼示例
- Python Pandas.pivot()用法及代碼示例
- Python Pandas.pivot_table()用法及代碼示例
- Python Pandas Series.mod()用法及代碼示例
- Python Pandas Series.str.len()用法及代碼示例
注:本文由純淨天空篩選整理自Shubham__Ranjan大神的英文原創作品 Python | Pandas Index.where。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。