使用機器學習方法解決實際問題時,我們通常要用L1或L2範數做正則化(regularization),從而限製權值大小,減少過擬合風險。特別是在使用梯度下降來做目標函數優化時,很常見的說法是, L1正則化產生稀疏的權值, L2正則化產生平滑的權值。為什麽會這樣?這裏麵的本質原因是什麽呢?下麵我們從兩個角度來解釋這個問題。
角度一:數學公式
這個角度從權值的更新公式來看權值的收斂結果。
首先來看看L1和L2的梯度(導數的反方向):
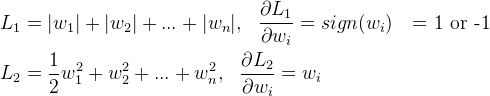
所以(不失一般性,我們假定:wi等於不為0的某個正的浮點數,學習速率η 為0.5):
L1的權值更新公式為wi = wi – η * 1 = wi – 0.5 * 1,也就是說權值每次更新都固定減少一個特定的值(比如0.5),那麽經過若幹次迭代之後,權值就有可能減少到0。
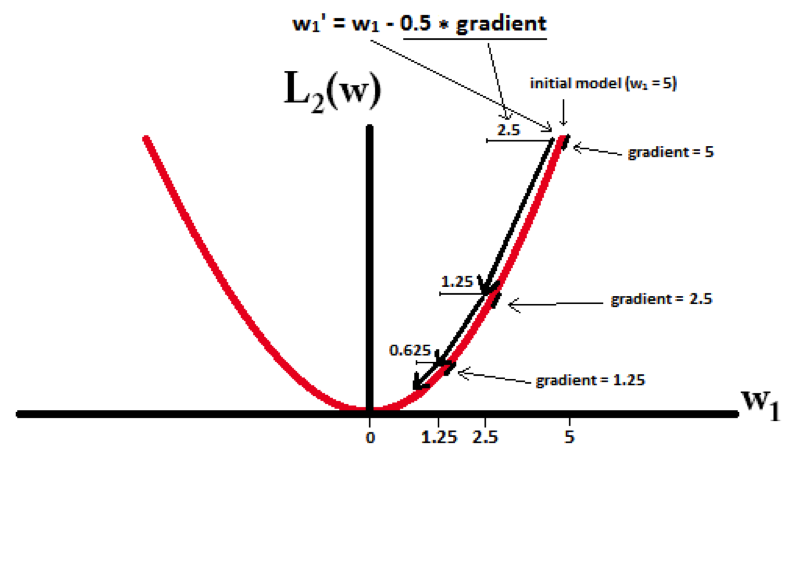
L2的權值更新公式為wi = wi – η * wi = wi – 0.5 * wi,也就是說權值每次都等於上一次的1/2,那麽,雖然權值不斷變小,但是因為每次都等於上一次的一半,所以很快會收斂到較小的值但不為0。
下麵的圖很直觀的說明了這個變化趨勢:
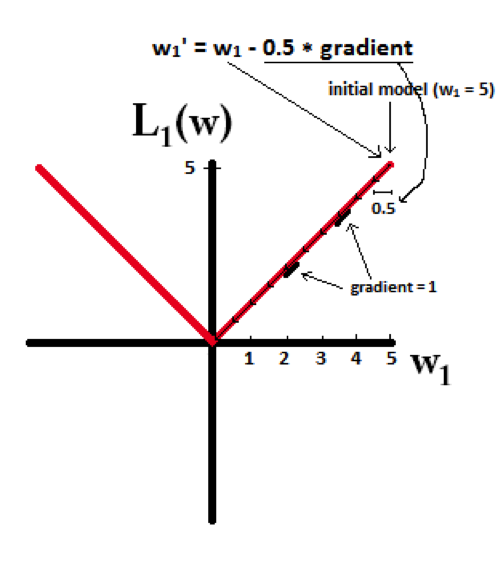
L1能產生等於0的權值,即能夠剔除某些特征在模型中的作用(特征選擇),即產生稀疏的效果。
L2可以得迅速得到比較小的權值,但是難以收斂到0,所以產生的不是稀疏而是平滑的效果。
角度二:幾何空間
這個角度從幾何位置關係來看權值的取值情況。
直接來看下麵這張圖:
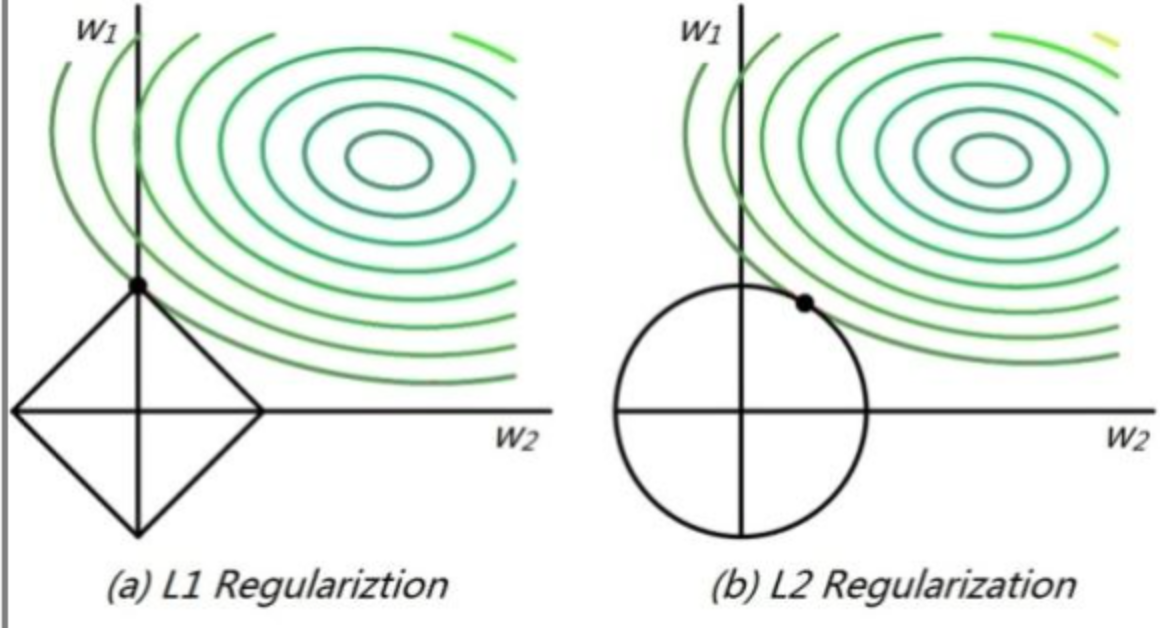
高維我們無法想象,簡化到2維的情形,如上圖所示。其中,左邊是L1圖示,右邊是L2圖示,左邊的方形線上是L1中w1/w2取值區間,右邊得圓形線上是L2中w1/w2的取值區間,綠色的圓圈表示w1/w2取不同值時整個正則化項的值的等高線(凸函數),從等高線和w1/w2取值區間的交點可以看到,L1中兩個權值傾向於一個較大另一個為0,L2中兩個權值傾向於均為非零的較小數。這也就是L1稀疏,L2平滑的效果。
注:本文內容總結自互聯網資料,來源已不可考,如有侵權,請聯係博主~