使用Scikit學習的主題建模
潛在狄利克雷分配(LDA)是一種算法,用於發現語料庫中存在的主題。有一些開源庫存在,但是如果你使用Python,那麽主要的競爭者是Gensim。 Gensim是一個非常棒的 Library ,對於大型文本語料庫非常好。然而,Gensim不包括Non-negative矩陣分解(NMF),它也可用於在文本中查找主題。支持NMF的數學基礎與LDA完全不同。我發現比較兩種算法的結果很有意思,並且發現NMF有時會為較小的數據集產生更有意義的主題。 NMF已被納入Scikit學習相當長一段時間,但LDA最近才被納入(2015年末)。關於使用Scikit Learn的好處是它帶來了API一致性,這使得使用LDA和NMF執行主題建模幾乎是微不足道的。 Scikit Learn還包括NMF的播種選項,它極大地有助於算法收斂並提供LDA的聯機和批處理變體。
LDA和NMF如何工作?
我不會涉及任何冗長的數學細節 – 有許多博客文章和學術期刊文章。雖然LDA和NMF具有不同的數學基礎,但這兩種算法都能夠返回屬於語料庫中的主題的文檔和屬於主題的單詞。 LDA基於概率圖形建模,而NMF依賴於線性代數。兩種算法都將一個詞組矩陣作為輸入(即,每個文檔表示為一行,每列包含語料庫中單詞的計數)。然後每個算法的目的是產生2個更小的矩陣;一個到話題矩陣的文檔和一個到話題矩陣的單詞,當它們相乘時再現出具有最低誤差的單詞矩陣。
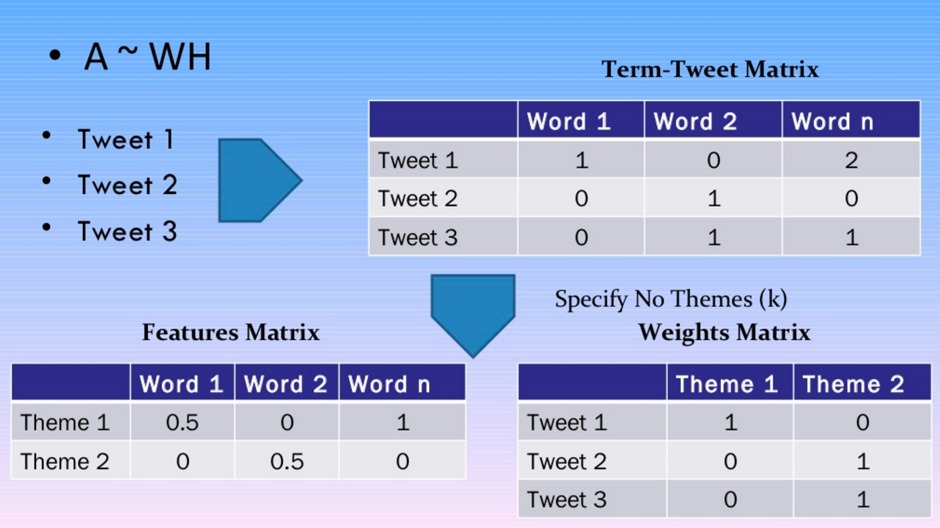
這裏沒有魔法 – 你需要指定主題的數量!
多少個話題?那麽這就是問題! NMF和LDA都不能自動確定主題的數量,必須指定。
數據集預處理
我搜索了一個令人興奮的數據集,並最終選擇了20 Newsgoups數據集。我隻是諷刺 – 我選擇了一個易於理解和加載Scikit Learn的數據集。該數據集很容易解釋,因為這20個新聞組是已知的,並且可以將生成的主題與正在討論的已知主題進行比較。數據集中排除了頁眉,頁腳和引號。
from sklearn.datasets import fetch_20newsgroups
dataset = fetch_20newsgroups(shuffle=True, random_state=1, remove=('headers', 'footers', 'quotes'))
documents = dataset.data
在Scikit Learn中創建詞組矩陣非常簡單 – 所有這些繁重的工作都是通過為文本數據集提供的特征提取功能完成的。將tf-idf變壓器應用於NMF必須使用TfidfVectorizer處理的單詞矩陣包。另一方麵,作為概率圖形模型(即處理概率)的LDA僅需要原始計數,因此使用CountVectorizer。停止單詞被刪除,包含在單詞矩陣中的術語數量限製在前1000位。
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
no_features = 1000
# NMF is able to use tf-idf
tfidf_vectorizer = TfidfVectorizer(max_df=0.95, min_df=2, max_features=no_features, stop_words='english')
tfidf = tfidf_vectorizer.fit_transform(documents)
tfidf_feature_names = tfidf_vectorizer.get_feature_names()
# LDA can only use raw term counts for LDA because it is a probabilistic graphical model
tf_vectorizer = CountVectorizer(max_df=0.95, min_df=2, max_features=no_features, stop_words='english')
tf = tf_vectorizer.fit_transform(documents)
tf_feature_names = tf_vectorizer.get_feature_names()
NMF和LDA與Scikit學習
如前所述,算法無法自動確定主題數量,並且在運行算法時必須設置此值。有關可用參數的全麵文檔可用於兩者NMF和LDA。用’nndsvd’初始化NMF中的W和H矩陣,而不是隨機初始化可以縮短NMF收斂的時間。 LDA也可以設置為以批處理或在線模式運行。
from sklearn.decomposition import NMF, LatentDirichletAllocation
no_topics = 20
# Run NMF
nmf = NMF(n_components=no_topics, random_state=1, alpha=.1, l1_ratio=.5, init='nndsvd').fit(tfidf)
# Run LDA
lda = LatentDirichletAllocation(n_topics=no_topics, max_iter=5, learning_method='online', learning_offset=50.,random_state=0).fit(tf)
顯示和評估主題
由NMF和LDA返回的結果矩陣的結構是相同的,用於訪問返回矩陣的Scikit Learn接口也是相同的。這很好,並且允許使用能夠顯示主題中的熱門詞匯的通用Python方法。主題未被算法標記 – 分配了數字索引。
def display_topics(model, feature_names, no_top_words):
for topic_idx, topic in enumerate(model.components_):
print "Topic %d:" % (topic_idx)
print " ".join([feature_names[i]
for i in topic.argsort()[:-no_top_words - 1:-1]])
no_top_words = 10
display_topics(nmf, tfidf_feature_names, no_top_words)
display_topics(lda, tf_feature_names, no_top_words)
從NMF和LDA派生的主題顯示如下。從NMF派生的主題看,主題0和主題8似乎並不是特別的東西,但其他主題可以根據頂部的單詞來解釋。用於20個新聞組數據集的LDA產生2個具有噪聲數據的主題(即主題4和7)以及一些難以解釋的主題(即主題3和主題9)。我想說NMF能夠在20個新聞組數據集中找到更有意義的主題。
NMF主題:
主題0:人們不會認為像知道時間正確的善意所說的
主題1:windows文件使用dos文件窗口使用程序問題卡
主題2:神耶穌聖經基督信仰相信基督徒基督徒教會罪
主題3:驅動器scsi驅動器硬盤ide控製器軟盤cd mac
主題4:遊戲隊年賽季球員打曲棍球贏球員
主題5:核心芯片加密解碼器密鑰政府代管公共使用算法
主題6:感謝您知道郵件提前嗨任何人信息尋找幫助
主題7:汽車新款00銷售價格10報價條件出貨20
主題8:就像沒有想到會得到哦告訴平均罰款
主題9:edu很快cs大學com電子郵件互聯網文章ftp發送
LDA主題:
主題0:政府人員法律槍國家總統州公開使用
主題1:驅動器卡磁盤位scsi使用mac內存感謝電腦
主題2:說人民亞美尼亞人土耳其確實看到去了女人
主題3:一年好的時候像汽車隊的年輕人一樣想
主題4:10 00 15 25 12 11 20 14 17 16
主題5:windows窗口程序版本文件dos使用文件可用顯示
主題6:edu文件空間com信息郵件數據發送可用程序
主題7:ax max b8f g9v a86 pl 145 1d9 0t 34u
主題8:上帝的人耶穌相信確實認為以色列的基督徒是真的
主題9:不要知道,隻要認為自己想用就好
在我的下一篇博客文章中,我將討論主題解釋並展示主題中的頂級文檔如何顯示。
完整代碼清單
隻有36行Python代碼和一些Scikit Learn魔法,可以實現多少功能。完整的代碼清單如下所示:
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
from sklearn.datasets import fetch_20newsgroups
from sklearn.decomposition import NMF, LatentDirichletAllocation
def display_topics(model, feature_names, no_top_words):
for topic_idx, topic in enumerate(model.components_):
print "Topic %d:" % (topic_idx)
print " ".join([feature_names[i]
for i in topic.argsort()[:-no_top_words - 1:-1]])
dataset = fetch_20newsgroups(shuffle=True, random_state=1, remove=('headers', 'footers', 'quotes'))
documents = dataset.data
no_features = 1000
# NMF is able to use tf-idf
tfidf_vectorizer = TfidfVectorizer(max_df=0.95, min_df=2, max_features=no_features, stop_words='english')
tfidf = tfidf_vectorizer.fit_transform(documents)
tfidf_feature_names = tfidf_vectorizer.get_feature_names()
# LDA can only use raw term counts for LDA because it is a probabilistic graphical model
tf_vectorizer = CountVectorizer(max_df=0.95, min_df=2, max_features=no_features, stop_words='english')
tf = tf_vectorizer.fit_transform(documents)
tf_feature_names = tf_vectorizer.get_feature_names()
no_topics = 20
# Run NMF
nmf = NMF(n_components=no_topics, random_state=1, alpha=.1, l1_ratio=.5, init='nndsvd').fit(tfidf)
# Run LDA
lda = LatentDirichletAllocation(n_topics=no_topics, max_iter=5, learning_method='online', learning_offset=50.,random_state=0).fit(tf)
no_top_words = 10
display_topics(nmf, tfidf_feature_names, no_top_words)
display_topics(lda, tf_feature_names, no_top_words)