在本教程中,我們看一下Mikolov等人的word2vec模型,該模型用於學習單詞的向量表示,稱為”word embeddings”。
畫重點
- 我們首先給出了為什麽我們想要將單詞表示為向量的動機。
- 我們觀察模型背後的直覺以及如何訓練(用數學方法來衡量)。
- 我們還在TensorFlow中展示了一個簡單的模型實現。
- 最後,我們看看如何讓初級版本更好地擴展。
在本教程中我們稍後介紹代碼,但是如果您希望直接進入,請隨時查看簡單的實現tensorflow/examples/tutorials/word2vec/word2vec_basic.py 這個基本的例子包含了下載一些數據所需的代碼,對它進行一些訓練並將結果可視化。一旦你閱讀和運行了基本版本,你可以畢業了models/tutorials/embedding/word2vec.py這是一個更嚴格的實現,展示了一些更高級的TensorFlow原理,如何有效地使用線程將數據移動到文本模型中,如何在訓練過程中設置檢查點等。
但首先,我們來看看為什麽我們想要學習單詞嵌入(word embedding)。如果你是一個Embedding專家,你可以跳過這個部分。
動機:為什麽學習Word嵌入?
圖像和音頻處理係統在大量且高維的數據集一起工作,該高維數據集被編碼為用於圖像數據的各個原始像素向量,或者例如音頻數據的功率譜密度係數。對於像圖像物體或語音識別這樣的任務,我們知道成功執行任務所需的所有信息都被編碼在數據中(因為人類可以從原始數據執行這些任務)。然而,自然語言處理係統傳統上把單詞當作離散的原子符號,因此’cat’可以表示為Id537,而’dog’為Id143。這些編碼是任意的,並且不提供關於各個符號之間可能存在的關係。這意味著模型在處理有關’dogs'(例如動物,four-legged,寵物等)的數據時不能充分利用’cats’的相關知識。將單詞表示為唯一的離散標識還會導致數據稀疏,通常意味著我們可能需要更多數據才能成功地訓練統計模型。使用矢量表示可以部分克服這些障礙。

向量空間模型(VSM)將單詞表示為(嵌入)到連續向量空間,其中語義上相似的單詞被映射到附近的點(‘彼此嵌入在一起’)。 VSM在NLP中有著悠久而豐富的曆史,但是所有的方法都依賴於某種方式分布假設,其中指出,出現在相同語境中的詞語具有相同語義意義。利用這一原則的不同方法可以分為兩類:count-based方法(例如。潛在的語義分析)和預測方法(例如。神經概率語言模型)。
這個區別更詳細的闡述參考Baroni等人,但簡而言之:Count-based方法計算一個詞與其相鄰詞在一個大文本語料庫中共現頻率的統計,然後將每個詞的這些count-statistics映射到小而密集向量。預測模型直接從鄰居單詞預測當前詞,從而嘗試學習小而密嵌入向量(考慮模型的參數)。
Word2vec是一個特別的可高效計算的預測模型,用於從原始文本中學習單詞嵌入。它有兩種方式,連續Bag-of-Words模型(CBOW)和Skip-Gram模型(第3.1和3.2節Mikolov等人)。在算法上,這些模型是類似的,除了CBOW從源上下文詞(‘cat坐在’)預測目標詞(例如’mat’),而skip-gram做相反的並且從目標詞預測上下文單詞。這種倒置可能看起來像是一種任意的選擇,但從統計上來看,CBOW具有平滑許多分布信息的效果(通過將整個上下文視為一個觀察)。大部分情況下,這對於較小的數據集是一個有用的東西。但是,skip-gram將每個上下文目標對視為一個新的觀測值,而當我們有更大的數據集時,這往往會更好。我們將在本教程的其餘部分重點介紹skip-gram模型。
擴大Noise-Contrastive訓練
神經概率語言模型傳統上使用的訓練依據是最大似然(ML)的原則,以最大化給出前麵的單詞h(對於”history”)時下一個單詞wt的概率(對於”target”),采用的方式是SOFTMAX函數,
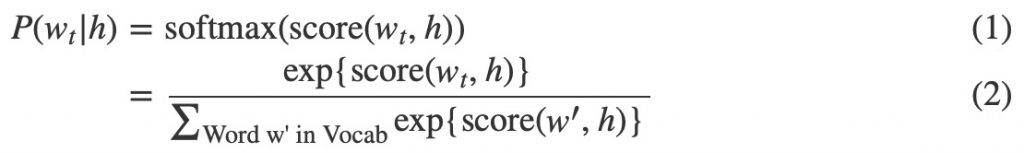
其中score(wt, h)計算word wt與上下文h的兼容性(通常使用點積)。我們通過最大化log-likelihood來訓練這個模型。在訓練集上,即通過最大化
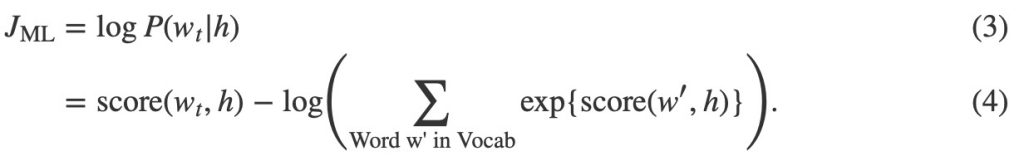
這產生了一個適當的規範化的語言建模概率模型。然而,這是非常昂貴的,因為在每一個訓練階段, 我們需要使用當前上下文h中的所有其他V個詞w’的分數來計算和歸一化每個概率。
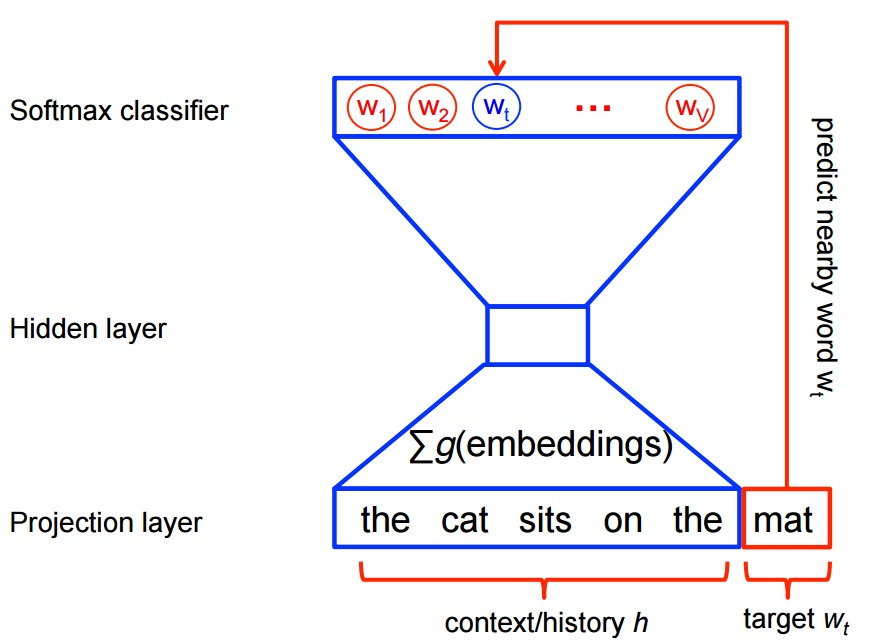
另一方麵,對於word2vec中的特征學習,我們不需要完全的概率模型。 CBOW和skip-gram模型是使用二元分類目標(邏輯回歸),在相同的上下文中區分來自k虛數(噪聲)單詞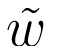 和實際目標單詞wt。我們在下麵對CBOW模型進行說明。對於skip-gram,方向是簡單的倒轉。
和實際目標單詞wt。我們在下麵對CBOW模型進行說明。對於skip-gram,方向是簡單的倒轉。
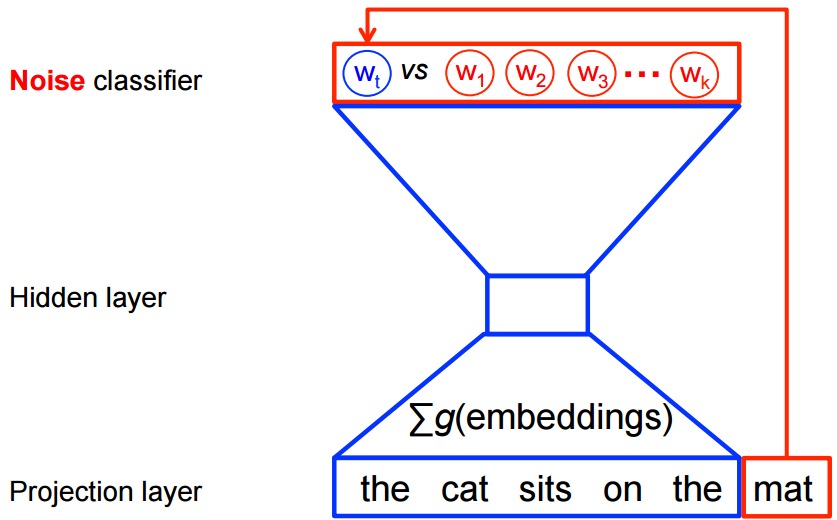
在數學上,目標(對於每個示例)是最大化的
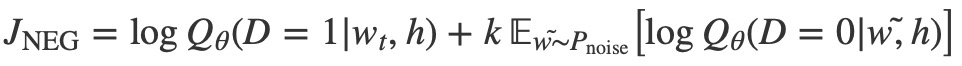
其中Qθ(D = 1 | w, h)是數據集D中上下文h,根據學習的嵌入向量θ計算。在實踐中,我們通過從噪聲分布中取出k對比詞來近似期望(即,我們計算a蒙特卡洛平均)。
當模型將高概率分配給真實的詞時,這個目標是最大化的,對噪聲詞的概率低。從技術上講,這被稱為負采樣,並且使用這個損失函數有很好的數學動機:它提出的更新近似於極限情況下softmax函數的更新。並且從計算角度來看,這是非常有吸引力的,因為計算損失函數現在隻能隨著噪音詞數量的變化而變化,即我們選擇的(k),而不是詞匯(V)表中的所有單詞。這使得訓練要快得多。實際上我們會利用非常相似的noise-contrastive估計(NCE)損失,為此TensorFlow有一個方便的幫手功能tf.nn.nce_loss()。
讓我們直觀地感受一下,在實踐中這將如何工作!
Skip-gram模型
作為一個例子,我們來考慮一下數據集
the quick brown fox jumped over the lazy dog
我們首先構造一個數據集,它包括單詞及其出現的上下文。我們可以用任何有意義的方式定義上下文’context’,事實上人們已經研究過句法上下文(即當前目標單詞的句法依賴,參見例如Levy等人),目標左邊的單詞,目標右邊的單詞,等等。讓我們鎖定在普通定義上,界定’context’為目標單詞上的一個窗口,它包含左邊和右邊的單詞。使用1的窗口大小,我們有數據集
([the, brown], quick), ([quick, fox], brown), ([brown, jumped], fox), ...
的(context, target)對。回想一下,skip-gram顛倒上下文和目標,並試圖從目標字中預測每個上下文字,所以任務變為預測來自’quick’的’the’和’brown’,來自’brown’的’quick’和’fox’等。因此,我們的數據集變成
(quick, the), (quick, brown), (brown, quick), (brown, fox), ...
的(input, output)對。目標函數是在整個數據集上定義的,但是我們通常使用隨機梯度下降(SGD)對這個函數進行優化,一次使用一個示例(或’minibatch’,batch_size例子,典型的16 <= batch_size <= 512)。所以讓我們來看看這個過程的一個步驟。
讓我們想象在訓練步驟t我們觀察上麵的第一個訓練案例,目標是從quick預測the。我們選擇通過從一些噪聲分布(通常是單字符分布)中提取噪聲(對比)樣本,數量為num_noise。(P(w))。為了簡單,讓我們設置num_noise=1我們選擇sheep作為一個噪聲樣本。接下來,我們計算這對觀察到的和有噪聲的例子的損失,即在時間步驟t處的目標變成
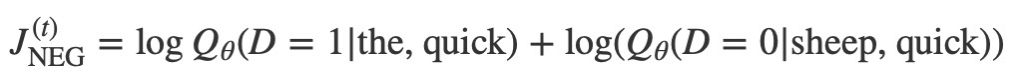
目標是對嵌入參數θ進行更新以改進(在這種情況下,最大化)這個目標函數。我們通過推導相對於嵌入參數的損失梯度來實現,即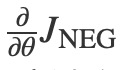 (Tensorflow有簡單的輔助功能來做到這一點!)。然後,我們通過向梯度方向邁出一小步來更新嵌入。當這個過程在整個訓練集上重複時,這將對每個單詞產生移動(‘moving’)嵌入向量的效果,直到模型成功識別真實單詞與噪聲單詞為止。
(Tensorflow有簡單的輔助功能來做到這一點!)。然後,我們通過向梯度方向邁出一小步來更新嵌入。當這個過程在整個訓練集上重複時,這將對每個單詞產生移動(‘moving’)嵌入向量的效果,直到模型成功識別真實單詞與噪聲單詞為止。
我們可以通過使用例如t-SNE降維技術類似的東西,將它們投影到2維來可視化所學習的向量。當我們檢查這些可視化時,顯然這些向量捕捉到了一些一般的,實際上相當有用的,關於單詞的語義信息及相互之間的關係。非常有趣的是,向量空間中的某些方向專注於特定的語義關係。例如,男性-女性,動詞時態,乃至國家-首都,如下圖所示(另見例如Mikolov等,2013)。
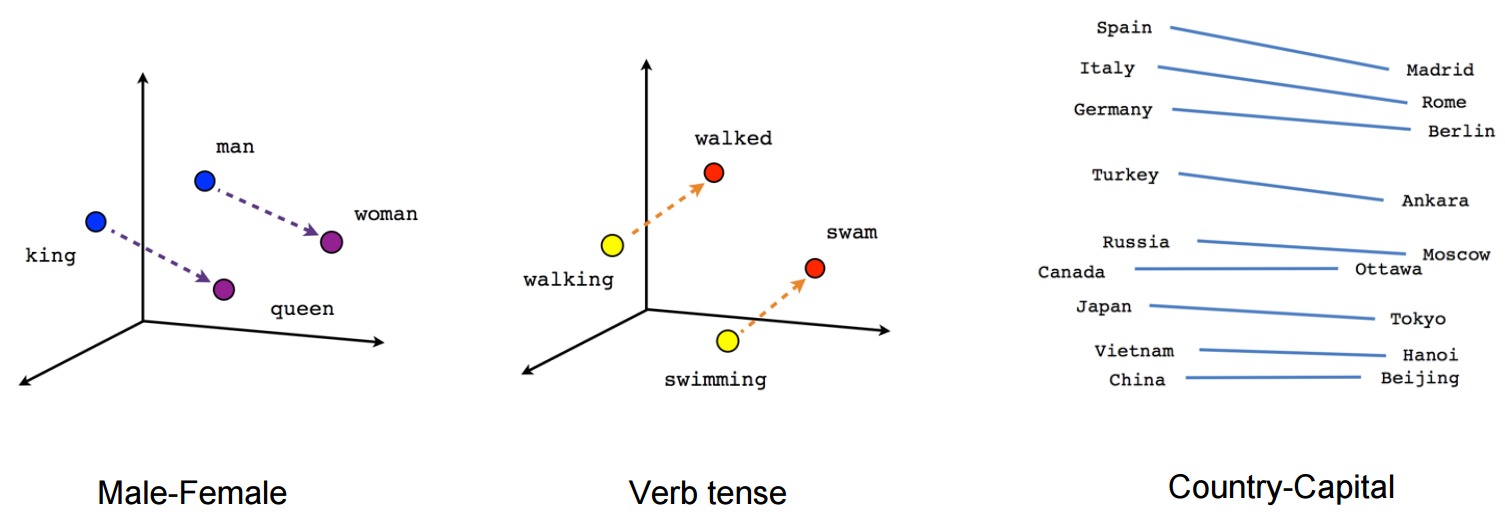
這解釋了為什麽這些矢量也可以用作許多典型NLP預測任務的特征,例如詞類標記或命名實體識別(例如,參見Collobert等人,2011(PDF格式),或follow-up工作Turian等人,2010)。
但現在,讓我們用它們來繪製美麗的圖畫!
建立圖表
首先,來定義我們的embedding矩陣。作為開始,這隻是一個很大的隨機矩陣,我們將使用均勻分布初始化單位立方體中的值。
embeddings = tf.Variable(
tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0))
noise-contrastive評估損失是根據邏輯回歸模型定義的。為此,我們需要為詞匯中的每個單詞定義權重和偏差
nce_weights = tf.Variable(
tf.truncated_normal([vocabulary_size, embedding_size],
stddev=1.0 / math.sqrt(embedding_size)))
nce_biases = tf.Variable(tf.zeros([vocabulary_size]))
現在我們已經有了參數,我們可以定義我們的skip-gram模型圖。為了簡單起見,假設我們已經將文本語料庫與詞匯表進行了整合,以便將每個詞表示為一個整數(參見tensorflow/examples/tutorials/word2vec/word2vec_basic.py的細節)。 skip-gram模型需要兩個輸入。一個是一批代表源語境詞匯的整數,另一個是針對目標詞匯的整數。讓我們為這些輸入創建占位符節點,以便稍後輸入數據。
# Placeholders for inputs
train_inputs = tf.placeholder(tf.int32, shape=[batch_size])
train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1])
現在我們需要做的是查找batch中每個源詞的向量。 TensorFlow有方便的幫手,使這個實現起來很簡單。
embed = tf.nn.embedding_lookup(embeddings, train_inputs)
好的,現在我們已經為每個單詞Embedding了,我們想用noise-contrastive訓練目標來預測目標單詞。
# Compute the NCE loss, using a sample of the negative labels each time.
loss = tf.reduce_mean(
tf.nn.nce_loss(weights=nce_weights,
biases=nce_biases,
labels=train_labels,
inputs=embed,
num_sampled=num_sampled,
num_classes=vocabulary_size))
現在我們有一個損失節點,我們需要添加計算梯度所需的節點並更新參數等等。為此,我們將使用隨機梯度下降,並且TensorFlow也有方便的幫助器來使這一點變得容易。
# We use the SGD optimizer.
optimizer = tf.train.GradientDescentOptimizer(learning_rate=1.0).minimize(loss)
訓練模型
訓練模型就是簡單地使用feed_dict將數據推送到占位符和調用tf.Session.run。
for inputs, labels in generate_batch(...):
feed_dict = {train_inputs: inputs, train_labels: labels}
_, cur_loss = session.run([optimizer, loss], feed_dict=feed_dict)
請參閱完整的示例代碼tensorflow /示例/教程/word2vec /word2vec_basic.py。
Embedding的可視化
訓練完成後,我們可以使用t-SNE可視化已學習的Embedding。
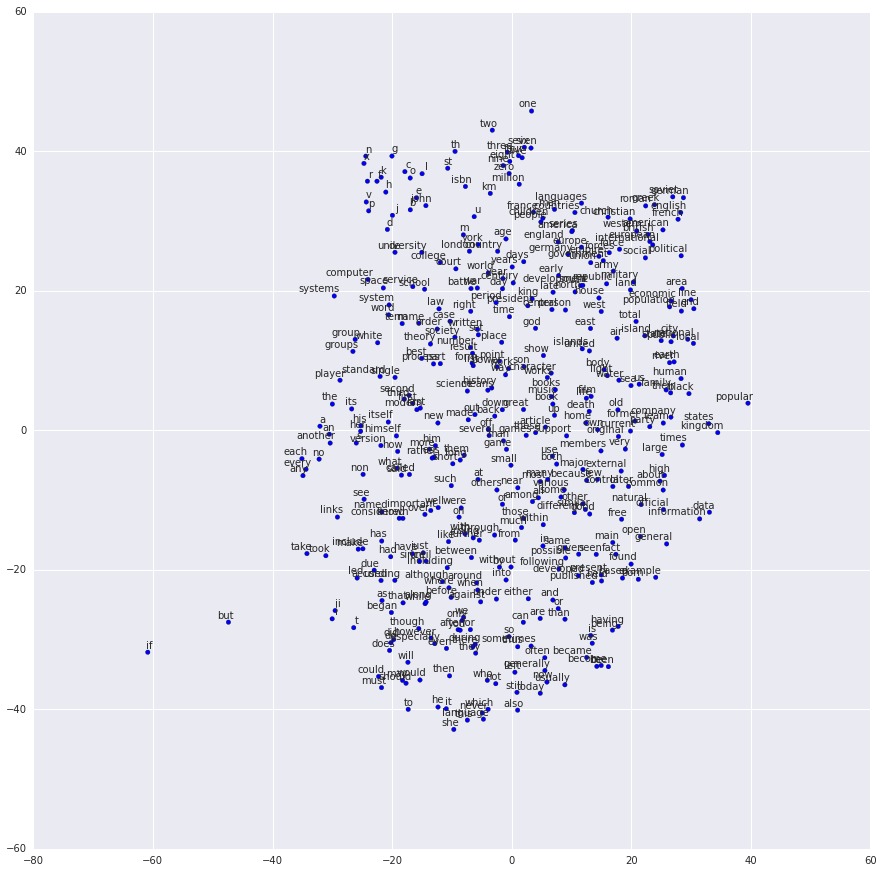
瞧!如預期的那樣,相似的單詞最終彼此聚集在一起。對於展示更多TensorFlow高級功能的更重量級的word2vec實現,請參閱models/tutorials/embedding/word2vec.py。
評估Embedding:類比推理(Analogical Reasoning)
Embedding對於NLP中的各種預測任務是有用的。在訓練full-blown詞類模型或命名實體模型之後,評估Embedding的一種簡單方法是直接使用它們來預測句法和語義關係king is to queen as father is to ?。這就是所謂的類比推理,此任務是由Mikolov和同事引入的。可從下載該任務的數據集。
要知道如何做這個評估,看看build_eval_graph()和eval()函數,它們在models/tutorials/embedding/word2vec.py.。
超參數的選擇可以強烈影響此任務的準確性。為了在這個任務上實現state-of-the-art性能,需要對一個非常大的數據集進行訓練,仔細調整超參數並利用諸如子采樣數據這樣的技巧,這超出了本教程的範圍。
優化實現
我們的普通實施展示了TensorFlow的靈活性。例如,改變訓練目標就像把調用tf.nn.nce_loss()換成現成的tf.nn.sampled_softmax_loss()一樣簡單。如果您對損失函數有新的想法,則可以在TensorFlow中手動為新目標編寫一個表達式,然後讓優化器計算其導數。這種靈活性在機器學習模型開發的探索階段是非常有價值的,在這個階段我們正在嘗試幾個不同的想法並且快速迭代。
一旦你有一個滿意的模型結構,就可以考慮優化你的實現從而更有效地運行(在更短的時間內覆蓋更多的數據)。例如,我們在本教程中使用的樸素代碼將會有不利影響,因為我們使用Python來讀取和提供數據項 – 而這在TensorFlow後端上隻需要很少的工作。如果您發現您的模型對輸入數據有嚴重的瓶頸,您可能需要為您的問題實現自定義數據讀取器,如新的數據格式。對於Skip-Gram建模的例子,我們實際上已經為你做了這個例子 models/tutorials/embedding/word2vec.py。
如果您的模型不再受I/O限製,但您仍希望獲得更高的性能,則可以通過編寫自己的TensorFlow Ops來進一步處理,如添加一個新的操作。我們再次為Skip-Gram案例提供了一個例子models/tutorials/embedding/word2vec_optimized.py。可以隨意對這些對方進行基準測試,以衡量每個階段的性能改進。
結論
在本教程中,我們介紹了word2vec模型,這是一個用於學習單詞嵌入的高效計算模型。我們激發了為什麽嵌入是有用的,討論了高效的訓練技術,並展示了如何在TensorFlow中實現所有這些功能。