代碼:tensorflow/examples/tutorials/mnist/
本教程的目的:展示如何使用TensorFlow來訓練和評估簡單的feed-forward神經網絡,這個網絡使用(經典)MNIST數據集的做手寫數字分類。本教程的目標用戶是有興趣使用TensorFlow並且有經驗的機器學習用戶。
這個教程不適用於一般的機器學習概念教學。
請確保您已按照說明安裝了TensorFlow。
教程文件
本教程引用了以下文件:
| 文件 | 目的 |
|---|---|
mnist.py |
構建全連接MNIST模型的代碼。 |
fully_connected_feed.py |
主要代碼使用Feed字典訓練建立模型,使用下載的MNIST數據集。 |
簡單地運行fully_connected_feed.py文件即可直接開始訓練:
python fully_connected_feed.py
準備數據
MNIST是機器學習中的經典問題,即查看手寫數字的28×28像素灰度圖像,並確定圖像代表哪個數字:從0到9的所有數字。

有關更多信息,請參閱Yann LeCun的MNIST頁麵或者克裏斯·奧拉的MNIST的可視化。
下載
在run_training()方法之上,input_data.read_data_sets()函數將確保正確的數據已被下載到您的本地訓練文件夾,然後解壓縮該數據返回一個字典DataSet實例。
data_sets = input_data.read_data_sets(FLAGS.train_dir, FLAGS.fake_data)
注意:fake_data標誌用於unit-testing目的,讀者可以安全地忽略它。
| 數據集 | 目的 |
|---|---|
data_sets.train |
55000圖像和標簽,用於初級訓練。 |
data_sets.validation |
5000個圖像和標簽,用於迭代驗證訓練精度。 |
data_sets.test |
10000個圖像和標簽,用於最終測試的訓練準確性評估。 |
輸入和占位符
placeholder_inputs()函數創建兩個tf.placeholderops,用於定義輸入的形狀,包括batch_size。
images_placeholder = tf.placeholder(tf.float32, shape=(batch_size,
mnist.IMAGE_PIXELS))
labels_placeholder = tf.placeholder(tf.int32, shape=(batch_size))
再往下,在訓練循環的每一步中,完整的圖像和標簽數據集被切割以適應batch_size,與這些占位符操作相匹配,然後使用feed_dict參數傳入sess.run()函數。
構建圖(計算圖)
在為數據創建占位符之後,從mnist.py文件可以看到,計算圖的構建按照3階段模式:inference(),loss(),和training()。
inference()– 根據需要構建圖,以便向前運行網絡進行預測。loss()– 向推理圖添加生成損失所需的操作。training()– 向損失圖添加計算和應用梯度所需的操作。
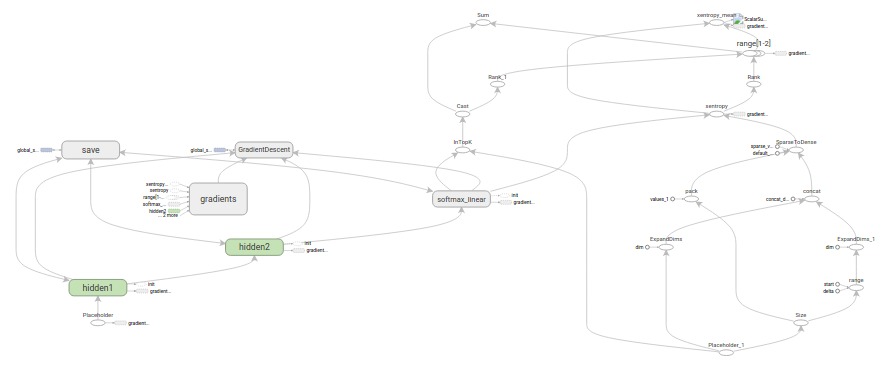
推斷(inference)
該inference()函數根據需要構建圖形,以返回包含輸出預測的張量。
它將圖像占位符作為輸入,並在其上建立一對完全連接的圖層(使用RELU激活),之後是一個指定輸出logits的十節點線性層。
每個圖層都在唯一的tf.name_scope下方創建,作為在該範圍內創建的項目的前綴。
with tf.name_scope('hidden1'):
在定義的範圍內,每個層所使用的權重和偏置被生成tf.Variable實例:
weights = tf.Variable(
tf.truncated_normal([IMAGE_PIXELS, hidden1_units],
stddev=1.0 / math.sqrt(float(IMAGE_PIXELS))),
name='weights')
biases = tf.Variable(tf.zeros([hidden1_units]),
name='biases')
例如,在hidden1範圍,賦予權重變量的唯一名稱將是“hidden1/weights”。
權重用tf.truncated_normal初始化並給出它們的二維張量的形狀,其中第一個dim表示權重連接層輸入單元的數量,第二個dim表示權重連接層輸出單元的數量。對於第一層,命名為hidden1,尺寸是[IMAGE_PIXELS, hidden1_units],因為權重將圖像輸入連接到hidden1圖層。tf.truncated_normal初始值生成器生成一個給定均值和標準差的隨機分布。
然後,這個偏差被初始化tf.zeros以確保它們以零值開始,它們的形狀隻是它們所連接的圖層中的單元數。
該圖有三個主要操作 – 其中兩個tf.nn.reluops分別為隱藏層封裝了tf.matmul,以及為logits封裝了tf.matmul。
hidden1 = tf.nn.relu(tf.matmul(images, weights) + biases)
hidden2 = tf.nn.relu(tf.matmul(hidden1, weights) + biases)
logits = tf.matmul(hidden2, weights) + biases
最後,logits將包含返回的輸出張量。
損失(loss)
loss()函數通過添加所需的損失操作來進一步構建圖表。
首先,從labels_placeholder被轉換為64位整數。然後,tf.nn.sparse_softmax_cross_entropy_with_logitsop被添加用來自動生成1-hot標簽labels_placeholder,並與inference()的logits輸出做比較。
labels = tf.to_int64(labels)
cross_entropy = tf.nn.sparse_softmax_cross_entropy_with_logits(
labels=labels, logits=logits, name='xentropy')
接下來使用tf.reduce_mean將批量維度(第一維度)上交叉熵的值平均化為總損失。
loss = tf.reduce_mean(cross_entropy, name='xentropy_mean')
最後將包含損失值的張量返回。
訓練(training)
training()函數添加所需的操作並通過梯度下降最大限度地減少損失。
首先,從loss()函數中獲得損耗張量,並把它交給一個tf.summary.scalar(這個操作用於在與tf.summary.FileWriter一起使用時將生成的摘要值寫入文件(見下文))。在這種情況下,每次寫出摘要時都會生成損失的快照值。
tf.summary.scalar('loss', loss)
接下來,我們實例化一個tf.train.GradientDescentOptimizer負責按要求的學習率應用梯度。
optimizer = tf.train.GradientDescentOptimizer(learning_rate)
然後,我們生成一個單一的變量,以包含全局訓練步驟和計數器tf.train.Optimizer.minimizeop用於更新係統中的可訓練權重並增加全局步長。按照慣例,這個操作就是所謂的train_op而且是TensorFlow會話必須執行的步驟,以便引導一整步訓練(見下文)。
global_step = tf.Variable(0, name='global_step', trainable=False)
train_op = optimizer.minimize(loss, global_step=global_step)
訓練模型
一旦圖被構建,就可以在由用戶代碼控製的循環中迭代地訓練和評估fully_connected_feed.py。
圖(Graph)
在run_training()函數之上是一個pythonwith命令,指示所有內置操作將與默認的全局tf.Graph實例關聯。
with tf.Graph().as_default():
一個tf.Graph是可以作為一個整體一起執行的操作集合。大多數TensorFlow使用隻需要依靠單個默認圖。
更複雜的使用多個圖是可能的,但超出了這個簡單的教程的範圍。
會話(session)
一旦所有的構建準備工作已經完成,並且產生了所有必要的操作,就可以創建tf.Session運行圖了。
sess = tf.Session()
或者,為了限製範圍,可以使用with創建Session:
with tf.Session() as sess:
會話的空參數表示此代碼將附加到(或創建,如果尚未創建)默認本地會話。
創建會話後,立即可以通過調用tf.Session.run將所有的tf.Variable實例進行初始化。
init = tf.global_variables_initializer()
sess.run(init)
tf.Session.run方法將運行作為參數傳遞的op相對應的圖的完整子集。在第一個調用中,initop是一個tf.group,它隻包含變量的初始值。
Training循環
用會話初始化變量後,就可以開始訓練了。
用戶代碼可以控製每一步的訓練,最簡單的訓練循環是:
for step in xrange(FLAGS.max_steps):
sess.run(train_op)
但是,本教程稍微複雜一些,因為必須為每個步驟分割輸入數據以匹配先前生成的占位符。
給圖填充數據
對於每一步,代碼將生成一個feed字典,該feed字典將包含該步驟所訓練的一組示例,由它們所代表的占位符操作。
在fill_feed_dict()函數中,給定的DataSet用於查詢下一個batch_size圖像和標簽,同時與占位符匹配的張量被填充。
images_feed, labels_feed = data_set.next_batch(FLAGS.batch_size,
FLAGS.fake_data)
然後用占位符作為key和相應的feed張量作為value生成一個python字典對象。
feed_dict = {
images_placeholder: images_feed,
labels_placeholder: labels_feed,
}
通過feed_dict參數傳入sess.run()函數來提供這一步訓練所需的輸入樣本。
檢查狀態
下麵的代碼指定了調用run時要用到的兩個值:[train_op, loss]。
for step in xrange(FLAGS.max_steps):
feed_dict = fill_feed_dict(data_sets.train,
images_placeholder,
labels_placeholder)
_, loss_value = sess.run([train_op, loss],
feed_dict=feed_dict)
由於有兩個取值,sess.run()返回一個包含兩個元素的元組。每Tensor在要獲取的值的列表中,對應於返回元組中的一個numpy數組,在訓練步驟中會填充該張量的值。因為train_op是一個沒有輸出值的操作,返回的元組中的對應元素是None,因此被忽略。但是,如果訓練期間模型沒有收斂,loss張量的值可能變成NaN,所以我們捕獲這個值用於記錄。
假設訓練運行良好,沒有NaNs,訓練循環還會每100步打印一個簡單的狀態文本,讓用戶知道訓練的狀態。
if step % 100 == 0:
print('Step %d: loss = %.2f (%.3f sec)' % (step, loss_value, duration))
可視化狀態
為了生成TensorBoard使用的時間文件,所有的摘要(在這種情況下,隻有一個)在圖構建階段收集到一個張量中。
summary = tf.summary.merge_all()
然後,會話創建後,一個tf.summary.FileWriter可以被實例化以寫入事件文件,它包含圖本身和摘要的值。
summary_writer = tf.summary.FileWriter(FLAGS.train_dir, sess.graph)
最後,每當摘要值summary重新評估時時間文件即被更新,輸出傳遞給writer的add_summary()函數。
summary_str = sess.run(summary, feed_dict=feed_dict)
summary_writer.add_summary(summary_str, step)
當事件文件被寫入時,TensorBoard可以運行在訓練文件夾中以顯示摘要中的值。

注意:有關如何構建和運行Tensorboard的更多信息,請參閱隨附的教程Tensorboard:可視化學習。
保存一個檢查點
為了生成一個檢查點文件,可以用來稍後恢複一個模型進行進一步的訓練或評估,我們實例化一個tf.train.Saver。
saver = tf.train.Saver()
在訓練循環中,可以周期調用tf.train.Saver.save方法將所有可訓練變量的當前值寫入訓練目錄中的檢查點文件。
saver.save(sess, FLAGS.train_dir, global_step=step)
在將來的某個時候,可以使用tf.train.Saver.restore方法重新加載模型參數。
saver.restore(sess, FLAGS.train_dir)
評估模型
每一千步,代碼將嘗試評估模型在訓練集和測試集上的效果。do_eval()函數被調用三次,分別用於訓練集,驗證集和測試集。
print('Training Data Eval:')
do_eval(sess,
eval_correct,
images_placeholder,
labels_placeholder,
data_sets.train)
print('Validation Data Eval:')
do_eval(sess,
eval_correct,
images_placeholder,
labels_placeholder,
data_sets.validation)
print('Test Data Eval:')
do_eval(sess,
eval_correct,
images_placeholder,
labels_placeholder,
data_sets.test)
請注意,更複雜的用法通常會隔離
data_sets.test,隻有在大量超參數調整後才會檢查。然而,在這個簡單的MNIST問題上,我們評估所有的數據。
構建評估圖
進入訓練循環之前,通過調用evaluation()函數先建立Eval操作。
eval_correct = mnist.evaluation(logits, labels_placeholder)
evaluation()函數隻是生成一個tf.nn.in_top_k操作,如果可以在K個最可能的預測中找到真正的標簽,則可以自動將每個模型輸出評分為正確的。在這種情況下,我們將K的值設置為1,隻考慮真實標簽的預測正確性。
eval_correct = tf.nn.in_top_k(logits, labels, 1)
評估輸出
然後可以創建一個循環來填充一個feed_dict並調用sess.run()以及eval_correct運算來評估給定數據集上的模型。
for step in xrange(steps_per_epoch):
feed_dict = fill_feed_dict(data_set,
images_placeholder,
labels_placeholder)
true_count += sess.run(eval_correct, feed_dict=feed_dict)
該true_count變量隻是累積了所有的預測in_top_kop已經確定是正確的。精確度可以通過簡單除以示例的總數來計算。
precision = true_count / num_examples
print(' Num examples: %d Num correct: %d Precision @ 1: %0.04f' %
(num_examples, true_count, precision))