Spark-Submit簡介
spark-submit腳本用於在集群上啟動應用程序,它位於Spark的bin目錄中。這種啟動方式可以通過統一的界麵使用所有的Spark支持的集群管理功能,因此您不必為每個應用程序專門配置應用程序。
綁定應用程序的依賴關係
如果您的代碼依賴於其他項目,則需要將它們與應用程序一起打包,才能將代碼分發到Spark群集。為此,請創建一個包含代碼及其依賴關係的程序集jar(或“uber”jar)。 sbt和Maven都有集成插件。創建程序集jar時,列出Spark和Hadoop作為提供的依賴項;這些不需要捆綁,因為它們在運行時由集群管理器提供。一旦你有一個組裝的jar,你可以調用bin/spark-submit腳本,傳遞你的jar。
對於Python,您可以使用spark-submit的--py-files參數來添加.py,.zip或.egg文件以與應用程序一起發布。如果您依賴多個Python文件,我們建議將它們打包成.zip或.egg。
使用spark-submit啟動應用程序
捆綁用戶應用程序後,可以使用bin/spark-submit腳本啟動。此腳本負責使用Spark及其依賴關係設置類路徑,並可支持Spark支持的不同群集管理器和部署模式:
./bin/spark-submit \
--class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... # other options
<application-jar> \
[application-arguments]
一些常用的選項是:
--class:應用程序的入口點,main函數所在的類(例如org.apache.spark.examples.SparkPi)--master:群集的主網址(例如spark://23.195.26.187:7077)--deploy-mode:是否將驅動程序部署在工作節點(cluster)上,或作為外部客戶機(client)本地部署(默認值:client)†--conf:Key = value格式的任意Spark配置屬性。對於包含空格的值,用引號括起“key = value”(參見示例)。application-jar:包含應用程序和所有依賴關係的捆綁jar的路徑。該URL必須在集群內全局可見,例如hdfs://路徑或所有節點上存在的file://路徑。application-arguments:參數傳遞給主類的main方法(如果有的話)
†常見的部署策略是從與您的工作機器物理上位於的網關機器提交應用程序(例如,獨立的EC2集群中的主節點)。在此設置中,client模式是適當的。在client模式下,驅動程序直接在spark-submit過程中啟動,該過程充當集群的客戶端。應用程序的輸入和輸出連接到控製台。因此,該模式特別適用於涉及REPL(例如Spark shell)的應用。
或者,如果您的應用程序從遠離工作機器(例如本地在筆記本電腦上)的機器提交,通常使用cluster模式來最大限度地減少驅動程序和執行程序之間的網絡延遲。目前,獨立模式不支持Python應用程序的集群模式。
對於Python應用程序,隻需將.py文件傳遞到<application-jar>而不是JAR文件中,並使用--py文件將Python .zip,.egg或.py文件添加到搜索路徑。
有幾個可用的選項是特定於正在使用的集群管理器。例如,使用具有集群部署模式的Spark獨立集群,還可以指定--supervise,以確保如果使用非零退出代碼失敗,則自動重新啟動驅動程序。要枚舉所有可用於spark-submit的可用選項,請使用--help運行它。以下是常見選項的幾個示例:
# Run application locally on 8 cores
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[8] \
/path/to/examples.jar \
100
# Run on a Spark standalone cluster in client deploy mode
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://207.184.161.138:7077 \
--executor-memory 20G \
--total-executor-cores 100 \
/path/to/examples.jar \
1000
# Run on a Spark standalone cluster in cluster deploy mode with supervise
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://207.184.161.138:7077 \
--deploy-mode cluster \
--supervise \
--executor-memory 20G \
--total-executor-cores 100 \
/path/to/examples.jar \
1000
# Run on a YARN cluster
export HADOOP_CONF_DIR=XXX
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \ # can be client for client mode
--executor-memory 20G \
--num-executors 50 \
/path/to/examples.jar \
1000
# Run a Python application on a Spark standalone cluster
./bin/spark-submit \
--master spark://207.184.161.138:7077 \
examples/src/main/python/pi.py \
1000
# Run on a Mesos cluster in cluster deploy mode with supervise
./bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master mesos://207.184.161.138:7077 \
--deploy-mode cluster \
--supervise \
--executor-memory 20G \
--total-executor-cores 100 \
http://path/to/examples.jar \
1000
Master URLs
傳遞給Spark的主URL可以是以下格式之一:
| Master URL | 解釋 |
|---|---|
local |
在本地運行Spark一個工作線程(即根本沒有並行性)。 |
local[K] |
使用K個工作線程在本地運行Spark(理想情況下,將其設置為機器上的核心數)。 |
local[*] |
在本地運行Spark,其工作線程與機器上的邏輯內核一樣多。 |
spark://HOST:PORT |
連接到給定的Spark獨立集群主控。端口必須是您的主機配置為使用哪個,默認情況下為7077。 |
mesos://HOST:PORT |
連接到給定的Mesos集群。端口必須是您配置為使用的端口,默認值為5050。或者,對於使用ZooKeeper的Mesos集群,請使用mesos://zk://....要使用--deploy-mode集群提交,HOST:PORT應配置為連接到MesosClusterDispatcher。 |
yarn |
根據-deploy-mode的值,以客戶端(client)或集群(cluster)模式連接到YARN群集。將基於HADOOP_CONF_DIR或YARN_CONF_DIR變量找到集群位置。 |
從文件加載配置
spark-submit腳本可以從屬性文件加載默認的Spark配置值,並將它們傳遞到應用程序。默認情況下,它將從Spark目錄中的conf/spark-defaults.conf中讀取選項。有關詳細信息,請參閱有關加載默認配置的部分。
以這種方式加載默認Spark配置可以避免需要某些標誌來引發提交。例如,如果設置了spark.master屬性,則可以從spark-submit中安全地省略--master標誌。通常,在SparkConf上顯式設置的配置值具有最高優先級,然後將標誌傳遞給spark-submit,然後將該值設置為默認值。
如果您不清楚配置選項的來源,您可以使用--verbose選項運行spark-submit來打印出細粒度的調試信息。
高級依賴管理
當使用spark-submit時,應用程序jar以及-jars選項中包含的任何jar將被自動傳輸到群集。 --jars之後提供的URL必須用逗號分隔。該列表包含在驅動程序和執行器類路徑上。目錄擴展不適用於--jars。
Spark使用以下URL方案來允許不同的策略來傳播jar:
file:– 絕對路徑和file:/URI由驅動程序的HTTP文件服務器提供,每個執行程序從驅動程序HTTP服務器提取文件。hdfs:, http:, https:, ftp:– 這些按照預期從URI中下拉文件和JARlocal:– 以local:/開頭的URI預計作為每個工作節點上的本地文件存在。這意味著不會出現網絡IO,並且適用於推送到每個工作者的大型文件/ JAR,或通過NFS,GlusterFS等共享。
請注意,JAR和文件將複製到執行程序節點上每個SparkContext的工作目錄。這可能會隨著時間的推移占用大量空間,並需要清理。使用YARN,清理將自動進行處理,並且通過Spark standalone,可以使用spark.worker.cleanup.appDataTtl屬性配置自動清理。
用戶可以通過提供逗號分隔的maven坐標列表與--packages來包含任何其他的依賴關係。使用此命令時將處理所有傳遞依賴關係。可以使用標記--repositories以逗號分隔的方式添加附加存儲庫(或SBT中的解析器)。 (請注意,在某些情況下,可以在存儲庫URI中提供受密碼保護的存儲庫的憑據,例如https://user:password@host/....在以這種方式提供憑據時請小心。)這些命令可以是與pyspark,spark-shell和spark-submit一起使用,包括Spark Packages。
對於Python,等效的--py-files選項可用於將.egg,.zip和.py庫分發到執行程序。
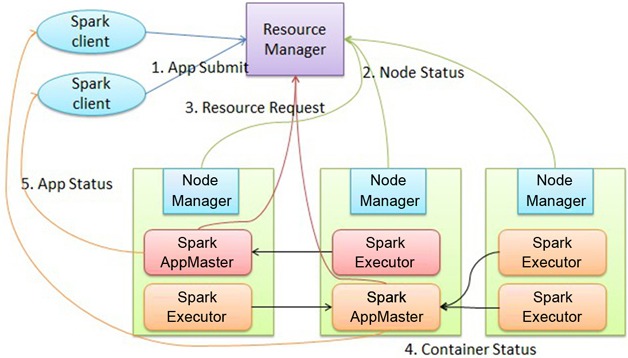
spark submit示意圖
進階閱讀
部署應用程序後,[集群模式概述][http://spark.apache.org/docs/latest/cluster-overview.html]將介紹分布式執行中涉及的組件以及如何監視和調試應用程序。