工作需要在大數據下進行數據挖掘,因此在開發機器進行了開發環境的搭建:IntelliJ IDEA + Spark; 這樣就可以使用IntelliJ IDEA在本地進行開發調試,之後再將作業提交到集群生產環境中運行,提升工作效率;本文對自己安裝步驟以進行了簡單的記錄
0. 安裝spark-1.3.0
因機器上已經安裝了JDK(如果沒安裝先安裝JDK),所以安裝spark就簡單兩步:
a、下載解壓:https://spark.apache.org/downloads.html
b、配係統路徑:在 ~/.bashrc 文件中寫入 , export PATH=$PATH:/spark解壓路徑/spark/bin
1.安裝IntelliJ IDEA
a、官網 下載IntelliJ IDEA , 最新版本的IntelliJ IDEA支持新建SBT工程,安裝scala插件
b、在IntelliJ IDEA的“Configure”菜單中,選擇“Plugins”,安裝“Scala”插件。
2.跑Spark demo程序
a、創建New Project -> Scala -> Project SDK 選擇JDK目錄,Scala SDK 選擇Scala目錄。

b、選擇菜單中的 File -> Project Structure -> libraries -> java,導入Spark安裝目錄 下的“spark-assembly-1.3.0-hadoop1.0.4.jar”

c、運行Scala示例程序SparkPi: Spark安裝目錄的examples目錄下/src/main/scala/org/apache/spark/examples,可以找到Scala編寫的示例程序SparkPi.scala,該程序計算Pi值並輸出。在Project的main目錄下新建test.scala,複製Spark示例程序代碼
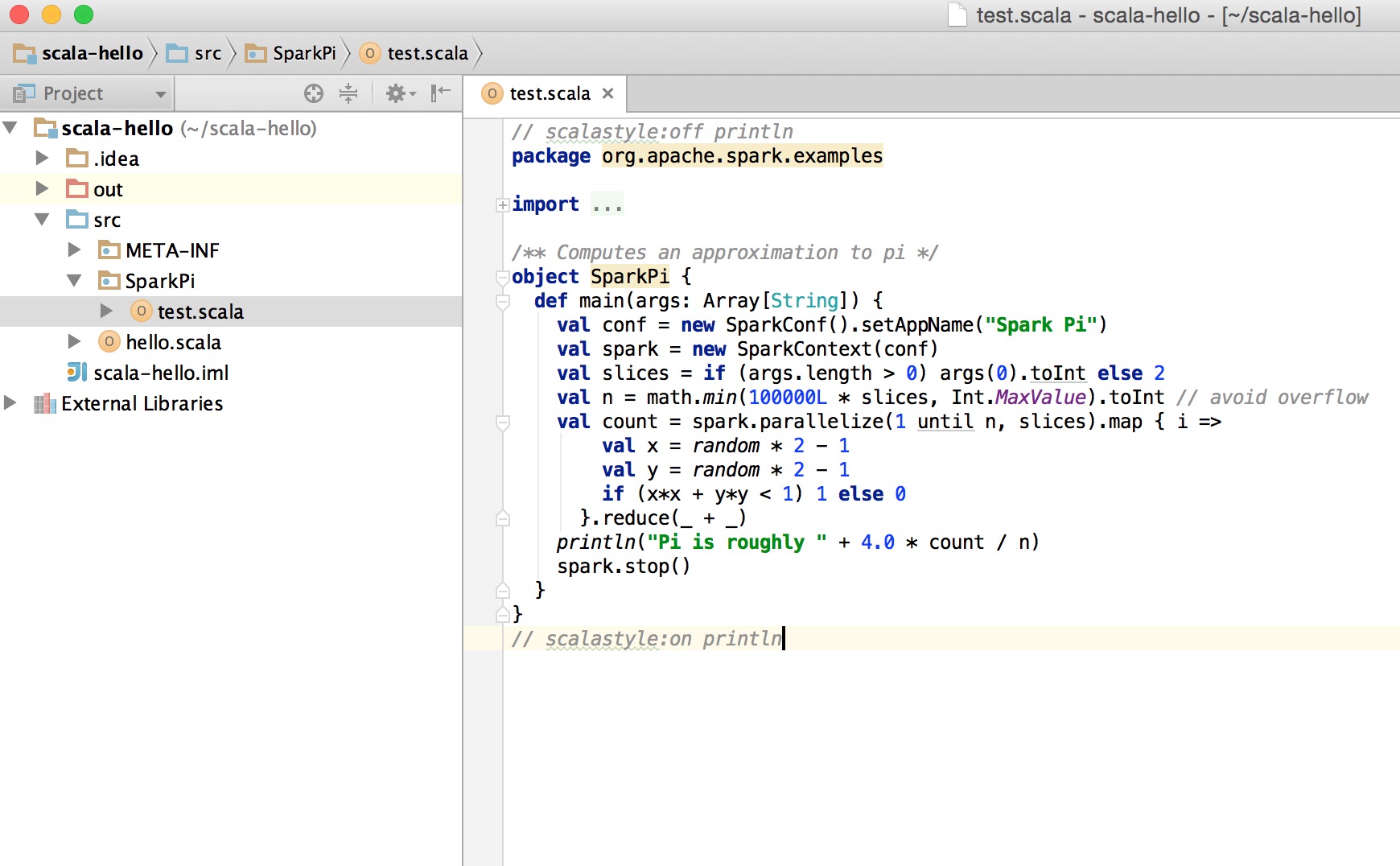
d、編譯運行:會出現了如下錯誤: Exception in thread “main” org.apache.spark.SparkException: A master URL must be set in your configuration 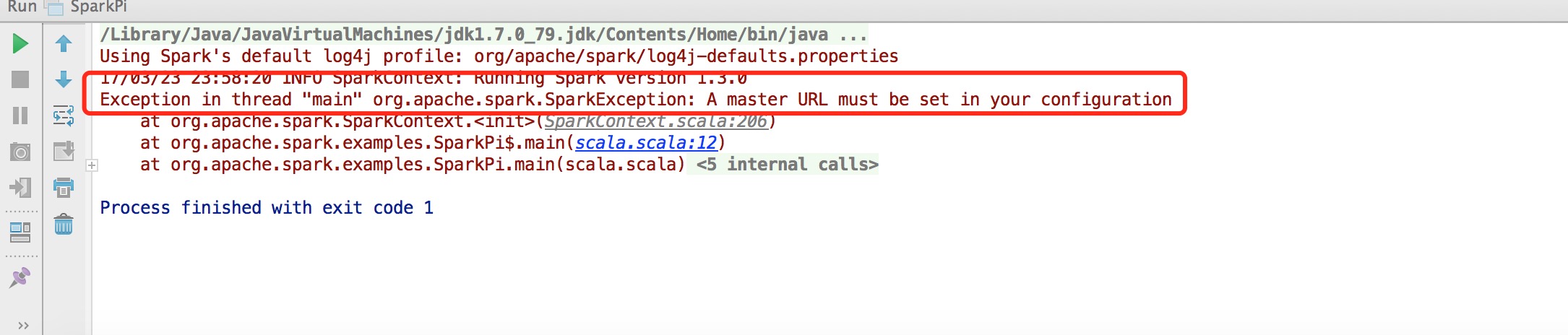
此時需要配置環境變量,選擇菜單中的Run->Edit Configurations,修改Main class和VM options。 在VM options中輸入“-Dspark.master=local”指示本程序本地單線程運行。具體可以查看Spark官方文檔http://spark.apache.org/docs/latest/running-on-yarn.html

3.生成jar包提交到集群
a、與本地local模式運行相同,創建 New project
b、選擇菜單中的File->Project Structure->Artifact->jar->From Modules with dependencies,之後選擇Main Class和輸出jar的Directory。
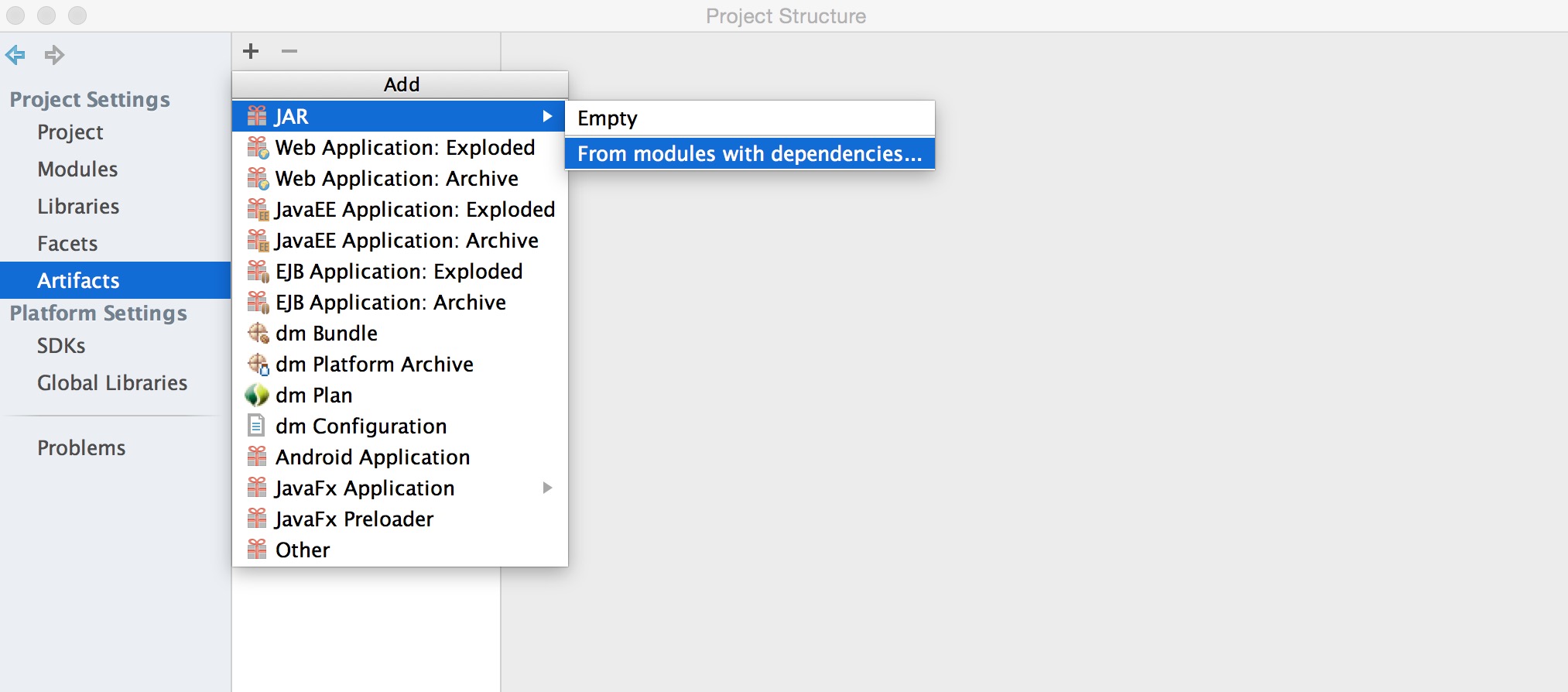
c、在主菜單選擇Build->Build Artifact編譯生成jar包
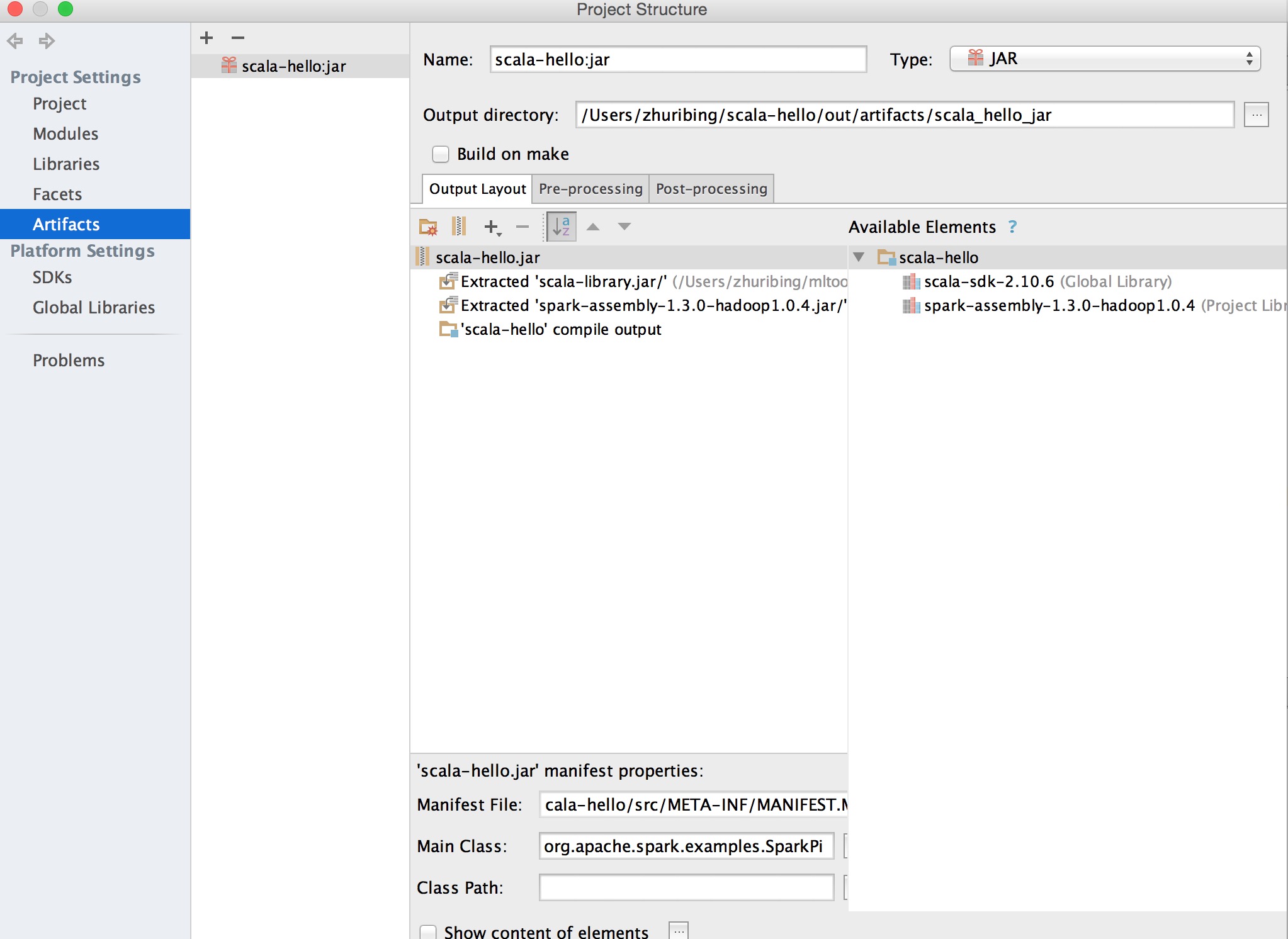
d、將jar包使用spark-submit提交 $SPARK_HOME/bin/spark-submit –class “com.path.**.類名” –master local[] “jar包”