在大數據處理中,有時候要將spark集群上處理好的數據拷貝到本地做進一步處理:比如本地單機運算或者作為在線服務的數據。如果直接拷貝字符串文本,耗費帶寬和時間。如何來優化這個拷貝性能呢?假設要拷貝的是海量整數數據,比如Int32, 如果我們用字符串傳遞,可能需要10個Byte;如果使用二進製字節傳遞,我們隻需要4個Byte。
不同的傳遞方式,有2.5倍的空間節省,在海量數據的情況下,這個優化是非常可觀的。那麽,問題變成了:如何使用spark將數據存成二進製格式,並且這個二進製在本地是可以解析的呢?
我們知道,目前spark[version<=1.6]可以比較方便地讀取二進製文件,使用的接口是:
sc.binaryRecords但是並沒有saveAsBinaryFile之類的方法,隻是有
sc.saveAsSequenceFile之類的方法可以保存二進製文件,但是這個方法保存的結果是sequence格式,在本地不借助第三方庫解析起來非常不便。
事實上,通過一些簡單繼承和重載,我們可以實現自己的saveAsBinaryFile:隻需要自己實現一個hadoop文件的OutputFormat。
假設我們現在要保存RDD[(Long, Long)], 以scala語言為例,簡要coding說明如下:
首先定義一個自己的hadoop文件輸出類BinaryFileOutputFormat[java語言],繼承自FileOutputFormat ,參考Spark源碼中的TextOutputFormat。
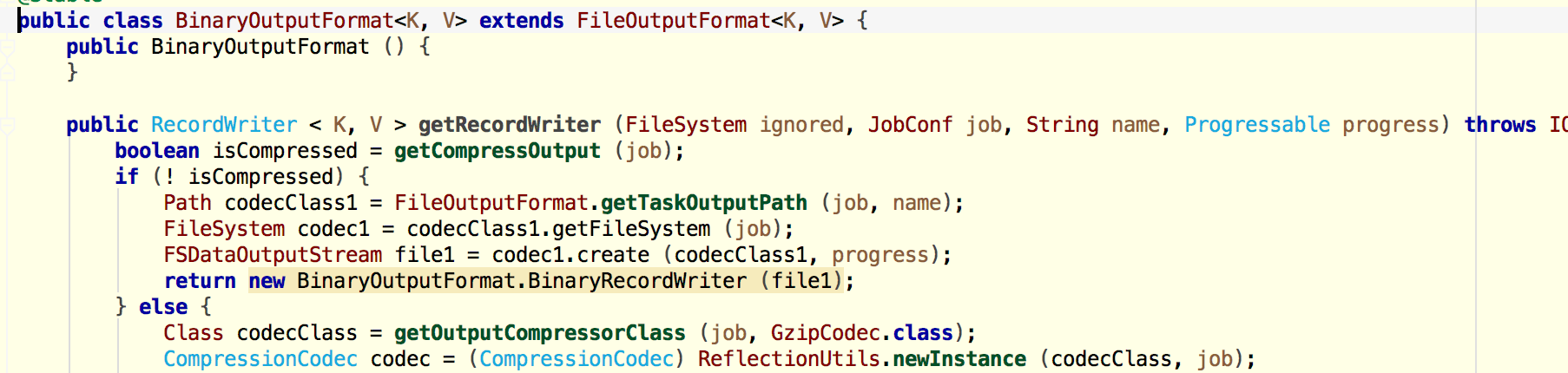
上麵隻圖示了部分代碼,最關鍵的是:重寫writeObject方法,改為將(Long, Long)序列化為java的Byte[]之後再輸出,其他變量和方法適當修改。
然後定義一個saveAsBinaryFile[scala語言]方法。

最後生成的文件可以使用hadoop fs -cat /xxx/* 拷貝到本地,再使用各種語言解析, 例如使用C/C++的fread讀取8+8 Bytes,然後反序列化為長整數。