工作需要在大数据下进行数据挖掘,因此在开发机器进行了开发环境的搭建:IntelliJ IDEA + Spark; 这样就可以使用IntelliJ IDEA在本地进行开发调试,之后再将作业提交到集群生产环境中运行,提升工作效率;本文对自己安装步骤以进行了简单的记录
0. 安装spark-1.3.0
因机器上已经安装了JDK(如果没安装先安装JDK),所以安装spark就简单两步:
a、下载解压:https://spark.apache.org/downloads.html
b、配系统路径:在 ~/.bashrc 文件中写入 , export PATH=$PATH:/spark解压路径/spark/bin
1.安装IntelliJ IDEA
a、官网 下载IntelliJ IDEA , 最新版本的IntelliJ IDEA支持新建SBT工程,安装scala插件
b、在IntelliJ IDEA的“Configure”菜单中,选择“Plugins”,安装“Scala”插件。
2.跑Spark demo程序
a、创建New Project -> Scala -> Project SDK 选择JDK目录,Scala SDK 选择Scala目录。

b、选择菜单中的 File -> Project Structure -> libraries -> java,导入Spark安装目录 下的“spark-assembly-1.3.0-hadoop1.0.4.jar”

c、运行Scala示例程序SparkPi: Spark安装目录的examples目录下/src/main/scala/org/apache/spark/examples,可以找到Scala编写的示例程序SparkPi.scala,该程序计算Pi值并输出。在Project的main目录下新建test.scala,复制Spark示例程序代码
d、编译运行:会出现了如下错误: Exception in thread “main” org.apache.spark.SparkException: A master URL must be set in your configuration 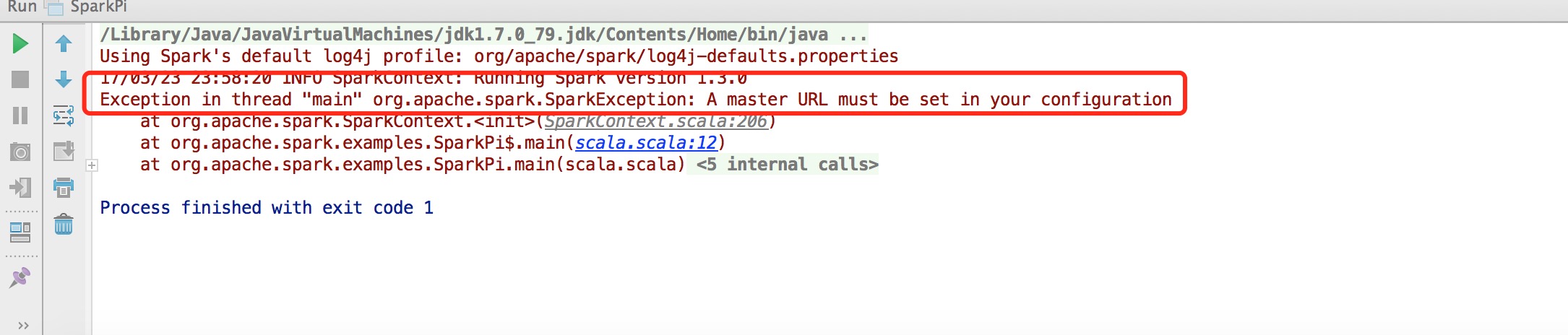
此时需要配置环境变量,选择菜单中的Run->Edit Configurations,修改Main class和VM options。 在VM options中输入“-Dspark.master=local”指示本程序本地单线程运行。具体可以查看Spark官方文档http://spark.apache.org/docs/latest/running-on-yarn.html

3.生成jar包提交到集群
a、与本地local模式运行相同,创建 New project
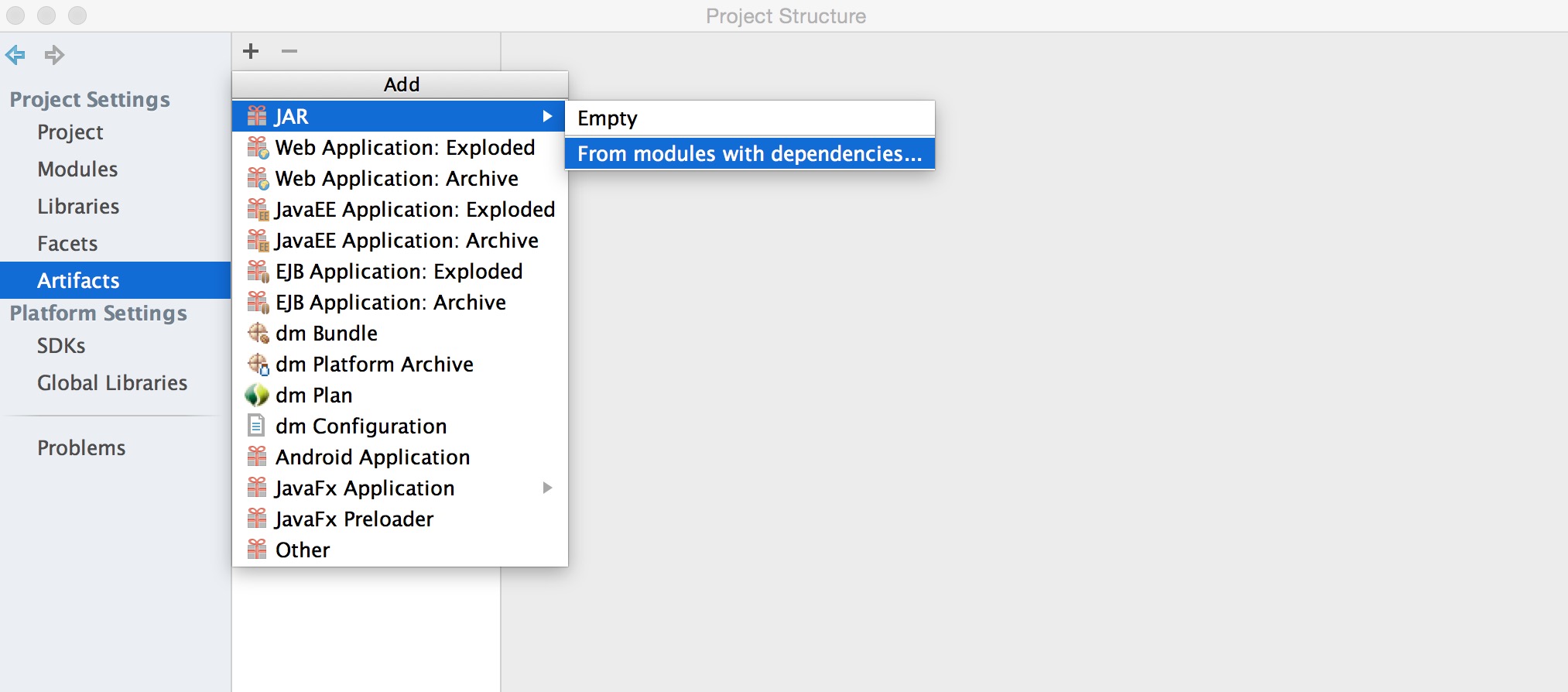
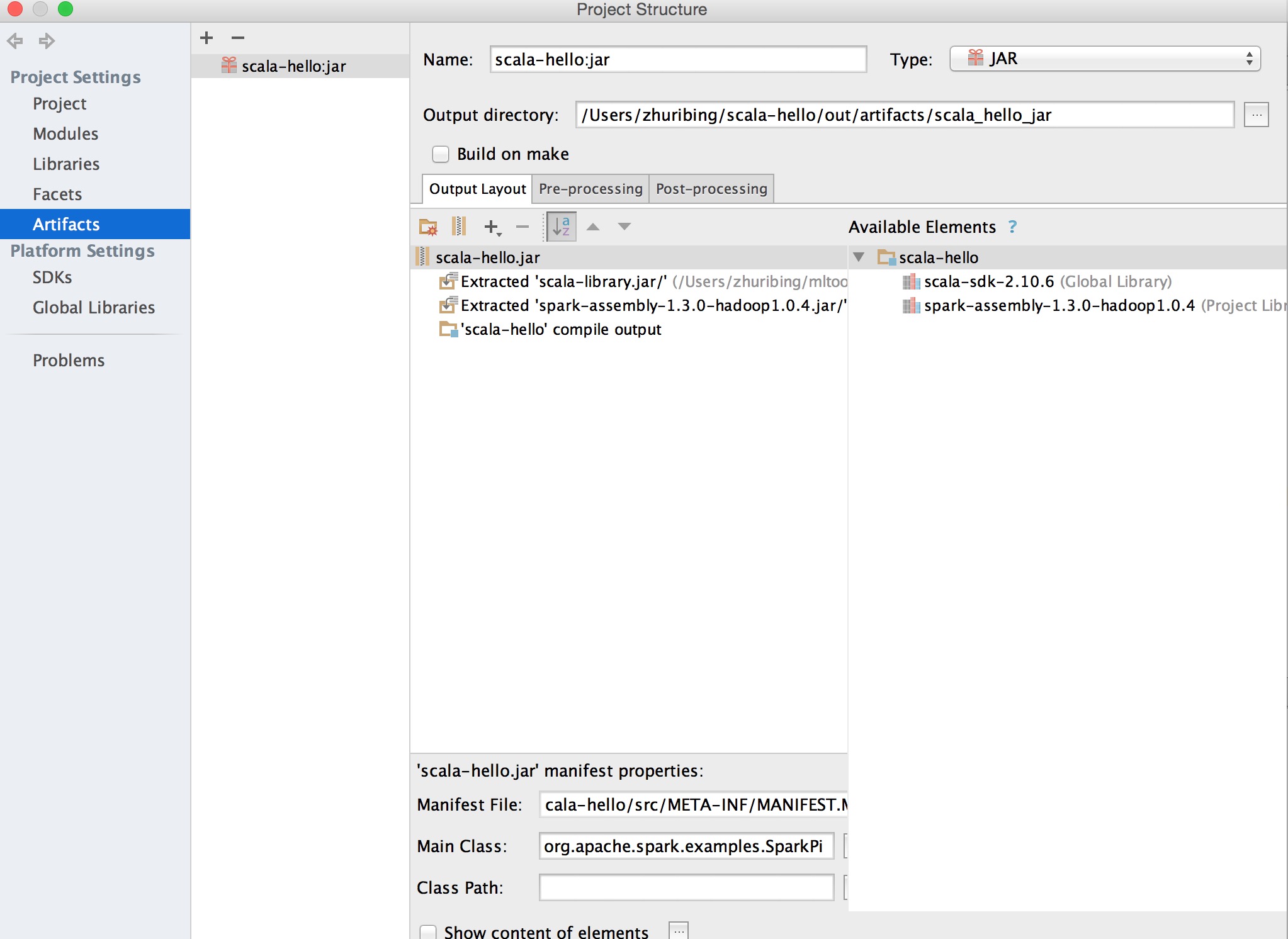
b、选择菜单中的File->Project Structure->Artifact->jar->From Modules with dependencies,之后选择Main Class和输出jar的Directory。
c、在主菜单选择Build->Build Artifact编译生成jar包
d、将jar包使用spark-submit提交 $SPARK_HOME/bin/spark-submit –class “com.path.**.类名” –master local[] “jar包”