下麵是章節決策樹的目錄(其他內容參見全文目錄)
決策樹以及決策樹的集成是很受歡迎的機器學習算法,經常用於解決分類和回歸任務。決策樹因為下列原因被廣泛使用:
- 模型容易解釋。決策樹模型是可閱讀的,從根到葉節點,每一步都可以看出決策依據。
- 能夠處理類別型特征(跟連續特征相對)。
- 能解決多分類問題
- 不需要特征尺度變換(特征值隻參入比較而不參入數值計算)
- are able to capture non-linearities and feature interactions[還沒想好這個該怎麽翻譯啊]
像隨機森林和迭代決策樹這樣的集成樹算法在分類和回歸任務上也位居前列。
MLlib支持使用決策樹做二分類、多分類和回歸,既能使用連續特征又能使用類別特征。具體實現中按行對數據分區,允許對百萬級的實例進行分布式訓練。
集成樹(隨機森林和梯度迭代樹)將會在下一節中介紹。
基礎算法
決策樹是一個貪心算法,它遞歸地對特征空間做分裂處理(不一定是二分,單屬性多個值的時候是多分)。決策樹中每個底層(葉節點)分區對應一個相同的標簽。每個分區都是通過從可能的分裂中貪心地選擇一個最好的分裂,從而最大化當前節點的信息增益。也就是說,在每個樹節點上選擇的分裂是從集合argmaxsIG(D,s)中選出來的,其中IG(D, s)是在數據集D上做s切分的信息增益。
節點不純度和信息增益(Node impurity and information gain)
節點不純度是用來衡量通過某節點屬性對樣本做分裂之後每個部分的標簽的一致性的,也就是看每部分中標簽是不是屬於同一個類型(labe)。MLlib當前的實現為分類提供了兩種不純度衡量方法(GINI不純度和熵),為回歸提供了一種不純度衡量方法(方差)。
| Impurity | Task | Formula | Description |
|---|---|---|---|
| Gini | 分類 | fi是某個分區內第i個標簽的頻率,C是該分區中的類別總數數。GINI不純度度量的是類型被分錯的可能性(類型的概率乘以分錯的概率) | |
| 熵 | 分類 | i是某個分區內第i個標簽的頻率,C是該分區中的類別總數數 | |
| 方差 | 分類 | yi是某個實例的標簽,N是實例的總數, μ是所有實例的均值: |
基於信息增益的方法:信息增益是父節點的不純度和兩個子節點的不純度之差。假設一個分裂s將數據集D(大小為N)分為兩個數據集Dleft(大小為Nleft)和Dright(大小為Nright),那麽信息增益可以表示為:
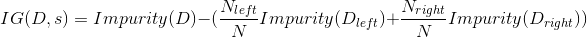
其中Impurity(D)、Impurity(Dleft)、Impurity(Dright)是相應係統的不純度,見上文表格中的三種不純度公式。注意這裏的信息增益跟信息論的專門概率信息增益是不同的,它是父子節點的不純度之差,而不單指熵差。
注:
使用信息增益的決策樹算法實現有ID3、C4.5:ID3使用的是信息增益,它在分裂時可能傾向於屬性值多的節點;C4.5是ID3的改進版,它使用的是信息增益率,另外還基於信息增益對連續型特征做了離散化處理。
使用GINI不純度的決策樹算法實現有CART。
分裂候選集(Split candidates)
連續特征(Continuous features)
在單機版實現中,數據集一般較小,對每個連續特征分裂出的候選集通常是去重之後的所有特征值。為了更快的進行樹計算,某些實現中會對特征值做排序並使用有序的去重值集作為候選集和。
但在大規模分布式數據集上,特征值排序代價是非常昂貴的。決策樹在大數據上的實現,一般會計算出一個近似的分裂候選集,具體做法是在抽樣的部分數據集上做分位點(quantile)計算[分位點是將有序數據集分成N等分的分界點,例如:2分位點是中值或者說中位數],這個其實就是連續特征離散化。有序分裂產生了“區段”(bins),區段的最大數量可以通過maxBins參數設置。
注意:區段的數量不可能超過當前的實例數量。如果不滿足這個條件,算法會自動調整區段參數值(maxBins的最大值是32)。
類別型特征(Categorical features)
對於類別型特征,如果該特征有M個可能的值(類別),那麽我們可以得到高達2M-1-1個候選分裂集和。在二分類(0/1)和回歸中,我們可以按照平均標簽對類別特征值排序(參見《Elements of Statistical Machine Learning 》章節9.2.4),進而將分裂候選集減少到M-1。例如,在一個二分類問題中,一個類別型特征有三種類型A、B和C,對應的標簽(二分類中label 1)分別占比0.2、0.6和0.4,那麽該類別型特征值可以排序為A、C、B。兩種分裂候選集是<A|C,B>和<A,C|B>,其中”|”表示分裂。
In multiclass classification, all 2M−1−1 possible splits are used whenever possible. When 2M−1−1 is greater than the maxBins parameter, we use a (heuristic) method similar to the method used for binary classification and regression. The M categorical feature values are ordered by impurity, and the resulting M−1 split candidates are considered.(對這一段的理解不足,後續再翻譯)
停止規則(Stopping rule)
遞歸樹的構建在節點滿足下列條件時停止:
- 節點深度等於maxDepth這個訓練參數。
- 沒有分裂候選集能產生比minInfoGain更大的信息增益。
- 沒有分裂候選集產生的子節點都至少對應
minInstancesPerNode個訓練樣本。
使用建議(Usage tips)
為了更好地使用決策樹,在下文中我們會討論各種參數的用法。下麵列舉的參數大致按重要程度排序。新手應該主要關注“問題規格參數”這一節以及“最大深度”這個參數。
問題規格參數(Problem specification parameters)
問題規格參數描述了要解決的問題和數據集。這些參數隻需要指定即可不需要調優。
algo:Classification或者RegressionnumClasses: 分類的類型數量Number of classes (隻用於Classification)categoricalFeaturesInfo: 指明哪些特征是類別型的以及每個類別型特征對應值(類別)的數量。通過map來指定,map的key是特征索引,value是特征值數量。不在這個map中的特征默認是連續型的。- 例如:Map(0 -> 2, 4->10)表示特征0有兩個特征值(0和1),特征4有10個特征值{0,1,2,3,…,9}。注意特征索引是從0開始的,0和4表示第1和第5個特征。
- 注意可以不指定參數
categoricalFeaturesInfo。算法這個時候仍然會正常執行。但是類別型特征顯示說明的話應該會訓練出更好的模型。
停止條件(Stopping criteria)
這些參數決定了何時停止構建樹(添加新節點)。當調整這些參數的時候,要謹慎使用測試集做校驗防止過擬合。
maxDepth: 樹的最大深度。越深的樹表達能力越強(潛在允許更高的準確率),但是訓練的代價也越大並更容易過擬合。minInstancesPerNode: 如果一個節點需要分裂的話,它的每個子節點必須至少有minInstancesPerNode個訓練樣本。這個通常在隨機森林中用到,因為隨機森林比獨立樹有更大的訓練深度。minInfoGain: 如果一個節點需要分裂的話,必須最少有minInfoGain的信息增益。
可調參數(Tunable parameters)
這些參數可用於調優。調優時要在測試集上小心測試以免過擬合。
maxBins: 連續特征離散化時用到的最大區段(bins)數。- 增加maxBins的值,可以讓算法考察跟多的分裂候選集,從而做耕細粒度的分裂。但是,這會增加計算量和通信開銷。
- 對於類別型特征,maxBins參數必須至少是特征值(類的數量M)的數量。
maxMemoryInMB: 存儲統計信息的內存大小。- 默認值保守地設置為256MB,這個大小在絕大多數應用場景下夠用。增加
maxMemoryInMB(如果增加的內存可用的話)允許更少的數據遍曆,可以提升訓練速度。但是,這也可能降低匯報,因為當maxMemoryInMB增長時,每次體的帶的通信開銷也會成比例增長。 - 實現上的細節:為了處理更好,決策樹算法會收集一組需要分裂節點的統計信息(而不是一次一個節點)。一個組中能夠處理的節點數量取決於內存需求(不同的特征差異大)。MaxMemoryInMB參數指定了每個worker上用於統計的內存限製(單位是MB)。
- 默認值保守地設置為256MB,這個大小在絕大多數應用場景下夠用。增加
subsamplingRate: 用於學習決策樹的訓練樣本比例。這個參數跟樹的集成(隨機森林,梯度提升樹)最相關,用於從原始數據中抽取子樣本。對於單個決策樹,這個參數用途不大,因為訓練樣本的數量通常不是主要約束。impurity: 用於選擇候選分裂的不純度度量標準。這個參數需要跟algo參數匹配。它的取值在上文表格中有討論。
緩存和檢查點(Caching and checkpointing)
MLlib 1.2添加了幾個特性用來擴展到更大的樹以及數的集成。當maxDepth設置得比較大,開啟節點ID緩存和檢查點就比較有用了。這些參數在numThrees設置得比較大的隨機森林算法中也比較有用。
useNodeIdCache:當這個參數設置為true,算法會避免在每次迭代中將當前模型傳給spark執行器(excutors)。- 這對深度大的樹(加速計算)和大的隨機森林(減少每次迭代的通信開銷)比較有用。
- 實現上的細節:默認情況下,算法向執行器傳達當前模型的信息以便執行器匹配訓練樣本和樹節點。如果這個設置開啟,模型信息直接緩存而不需要傳送。
節點ID緩存產生了一個RDD序列(每次迭代1個)。這個長序列會導致性能問題,但是為RDD設置檢查點(checkpoitng)可以緩解這個問題。注意檢查點隻在useNodeIdCache開啟時可用。
checkpointDir: 設置檢查點的保存目錄checkpointInterval: 設置檢查點的頻率。過高會導致大量集群寫操作。過低的話,如果執行器失敗,RDD需要重新計算。
擴展性(Scaling)
在計算方麵,擴展能力跟訓練樣本數、特征數量、maxBins參數有著近似線性的關係。在通信方麵,擴展能力跟特征數量以及maxBins有著近似線性的關係。
The implemented algorithm reads both sparse and dense data. However, it is not optimized for sparse input.
實現的算法既可以讀取稀疏數據又可以讀取密集型數據。但是,目前沒有為稀疏輸入做優化。
示例
分類(Classification)
下麵的例子說明了怎樣導入LIBSVM 數據文件,解析成RDD[LabeledPoint],然後使用決策樹進行分類。GINI不純度作為不純度衡量標準並且樹的最大深度設置為5。最後計算了測試錯誤率從而評估算法的準確性。
from pyspark.mllib.regression import LabeledPoint
from pyspark.mllib.tree import DecisionTree, DecisionTreeModel
from pyspark.mllib.util import MLUtils
# Load and parse the data file into an RDD of LabeledPoint.
data = MLUtils.loadLibSVMFile(sc, 'data/mllib/sample_libsvm_data.txt')
# Split the data into training and test sets (30% held out for testing)
(trainingData, testData) = data.randomSplit([0.7, 0.3])
# Train a DecisionTree model.
# Empty categoricalFeaturesInfo indicates all features are continuous.
model = DecisionTree.trainClassifier(trainingData, numClasses=2, categoricalFeaturesInfo={},
impurity='gini', maxDepth=5, maxBins=32)
# Evaluate model on test instances and compute test error
predictions = model.predict(testData.map(lambda x: x.features))
labelsAndPredictions = testData.map(lambda lp: lp.label).zip(predictions)
testErr = labelsAndPredictions.filter(lambda (v, p): v != p).count() / float(testData.count())
print('Test Error = ' + str(testErr))
print('Learned classification tree model:')
print(model.toDebugString())
# Save and load model
model.save(sc, "myModelPath")
sameModel = DecisionTreeModel.load(sc, "myModelPath")
回歸(Regression)
下麵的例子說明了如何導入LIBSVM 數據文件,解析為RDD[LabeledPoint],然後使用決策樹執行回歸。方差作為不存度衡量標準,樹最大深度是5。最後計算了均方誤差用來評估擬合度。
from pyspark.mllib.regression import LabeledPoint
from pyspark.mllib.tree import DecisionTree, DecisionTreeModel
from pyspark.mllib.util import MLUtils
# Load and parse the data file into an RDD of LabeledPoint.
data = MLUtils.loadLibSVMFile(sc, 'data/mllib/sample_libsvm_data.txt')
# Split the data into training and test sets (30% held out for testing)
(trainingData, testData) = data.randomSplit([0.7, 0.3])
# Train a DecisionTree model.
# Empty categoricalFeaturesInfo indicates all features are continuous.
model = DecisionTree.trainRegressor(trainingData, categoricalFeaturesInfo={},
impurity='variance', maxDepth=5, maxBins=32)
# Evaluate model on test instances and compute test error
predictions = model.predict(testData.map(lambda x: x.features))
labelsAndPredictions = testData.map(lambda lp: lp.label).zip(predictions)
testMSE = labelsAndPredictions.map(lambda (v, p): (v - p) * (v - p)).sum() / float(testData.count())
print('Test Mean Squared Error = ' + str(testMSE))
print('Learned regression tree model:')
print(model.toDebugString())
# Save and load model
model.save(sc, "myModelPath")
sameModel = DecisionTreeModel.load(sc, "myModelPath")