本文是Spark2.1官方文檔的翻譯:Extracting, transforming and selecting features => Spark特征抽取、特征轉換、特征選擇,全文目錄如下:
- Feature Extractors(特征提取)
- Feature Transformers(特征變換)
- Tokenizer(分詞器)
- StopWordsRemover(停用字清除)
- n-gram
- Binarizer(二元化方法)
- PCA(主成成分分析)
- PolynomialExpansion(多項式擴展)
- Discrete Cosine Transform (DCT-離散餘弦變換)
- StringIndexer(字符串-索引變換)
- IndexToString(索引-字符串變換)
- OneHotEncoder(獨熱編碼)
- VectorIndexer(向量類型索引化)
- Normalizer(範數p-norm規範化)
- StandardScaler
- MinMaxScaler(最大-最小規範化)
- MaxAbsScaler(絕對值規範化)
- Bucketizer(分箱器)
- ElementwiseProduct (Hadamard乘積)
- SQLTransformer(SQL變換)
- VectorAssembler(特征向量合並)
- QuantileDiscretizer(分位數離散化)
- Feature Selectors(特征選擇)
Feature Extractors(特征提取)
TF-IDF
詞頻(Term Frequency)- 逆向文檔頻率(Inverse Document Frequency) 是一種特征矢量化方法,廣泛應用於文本挖掘,用以評估某一字詞對於一個文件集或一個語料庫中的其中一份文件的重要程度。定義:t 表示由一個單詞,d 表示一個文檔,D 表示多個文檔構成的語料庫(corpus),詞頻 TF(t,d)表示某一個給定的單詞 t 在該文件 d 中出現的頻率。文檔頻率 DF(t,D)表示整個語料庫 D 中單詞 t 出現的頻率。如果我們僅使用詞頻 TF 來評估的單詞的重要性,很容易過分強調一些經常出現而並沒有包含太多與文檔有關信息的單詞,例如,“一”,“該”,和“的”。如果一個單詞在整個語料庫中出現的非常頻繁,這意味著它並沒有攜帶特定文檔的某些特殊信息,換句話說,該單詞對整個文檔的重要程度低。逆向文檔頻度是衡量一個詞語對文檔重要性的度量。某一特定詞語的IDF,可以由總文件數目除以包含該詞語之文件的數目,再將得到的商取對數得到
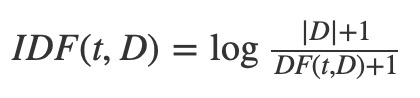
其中,|D| 是在語料庫中文檔總數。因為使用了對數,所以如果一個單詞出現在所有的文件,其IDF值變為0。注意,為了防止分母為0,分母需要加1。因此,對TF-IDF定義為TF和IDF的乘積:

關於詞頻TF和文檔頻率DF的定義有多種形式。在MLlib,我們會根據需要獨立使用TF和IDF。
TF(詞頻Term Frequency):HashingTF與CountVectorizer都可以用於生成詞頻TF矢量。
HashingTF是一個轉換器(Transformer),它可以將特征詞組轉換成給定長度的(詞頻)特征向量組。在文本處理中,“特征詞組”有一係列的特征詞構成。HashingTF利用hashing trick將原始的特征(raw feature)通過哈希函數映射到低維向量的索引(index)中。這裏使用的哈希函數是murmurHash 3。詞頻(TF)是通過映射後的低維向量計算獲得。通過這種方法避免了直接計算(通過特征詞建立向量term-to-index產生的)巨大特征數量。(直接計算term-to-index 向量)對一個比較大的語料庫的計算來說開銷是非常巨大的。但這種降維方法也可能存在哈希衝突:不同的原始特征通過哈希函數後得到相同的值( f(x1) = f(x2) )。為了降低出現哈希衝突的概率,我們可以增大哈希值的特征維度,例如:增加哈希表中的bucket的數量。一個簡單的例子:通過哈希函數變換到列的索引,這種方法適用於2的冪(函數)作為特征維度,否則(采用其他的映射方法)就會出現特征不能均勻地映射到哈希值上。默認的特征維度是218=262,144。一個可選的二進製切換參數控製詞頻計數。當設置為true時,所有非零詞頻設置為1。這對離散的二進製概率模型計算非常有用。
CountVectorizer可以將文本文檔轉換成關鍵詞的向量集。請閱讀英文原文CountVectorizer 了解更多詳情。
IDF(逆文檔頻率):IDF是的權重評估器(Estimator),用於對數據集產生相應的IDFModel(不同的詞頻對應不同的權重)。 IDFModel對特征向量集(一般由HashingTF或CountVectorizer產生)做取對數(log)處理。直觀地看,特征詞出現的文檔越多,權重越低(down-weights colume)。
注: spark.ml沒有為文本提供分詞工具和方法。我們推薦用戶參考Stanford NLP Group 和 scalanlp/chalk。
例子
在下麵的代碼段裏,我們先從一組句子處理開始。我們使用分解器Tokenizer將每個句子拆分成一係列的單詞。對於每一個句子(詞袋,詞集:bag of words),我們使用HashingTF將一個句子轉換成一個特征向量。最後使用IDF重新調整的特征向量(的維度)。通過這種方法提高文本特征的(運算)性能。然後我們提取的特征向量可以作為輸入參數傳遞到學習算法中。
import org.apache.spark.ml.feature.{HashingTF, IDF, Tokenizer}
val sentenceData = spark.createDataFrame(Seq(
(0, "Hi I heard about Spark"),
(0, "I wish Java could use case classes"),
(1, "Logistic regression models are neat")
)).toDF("label", "sentence")
val tokenizer = new Tokenizer().setInputCol("sentence").setOutputCol("words")
val wordsData = tokenizer.transform(sentenceData)
val hashingTF = new HashingTF()
.setInputCol("words").setOutputCol("rawFeatures").setNumFeatures(20)
val featurizedData = hashingTF.transform(wordsData)
// alternatively, CountVectorizer can also be used to get term frequency vectors
val idf = new IDF().setInputCol("rawFeatures").setOutputCol("features")
val idfModel = idf.fit(featurizedData)
val rescaledData = idfModel.transform(featurizedData)
rescaledData.select("features", "label").take(3).foreach(println)
在Spark repo中”examples/src/main/scala/org/apache/spark/examples/ml/TfIdfExample.scala”下可以找到完整的示例代碼。
Word2Vec
Word2Vec是一個通過詞向量來表示文檔語義上相似度的Estimator(模型評估器),它會訓練出Word2VecModel模型。該模型將(文本的)每個單詞映射到一個單獨的大小固定的詞向量(該文本對應的)上。Word2VecModel通過文本單詞的平均數(條件概率)將每個文檔轉換為詞向量; 此向量可以用作特征預測、 文檔相似度計算等。請閱讀英文原文Word2Vec MLlib 用戶指南了解更多的細節。
在下麵的代碼段中,我們以一組文檔為例,每一組都由一係列的詞(序列)構成。通過Word2Vec把每個文檔變成一個特征詞向量。這個特征矢量就可以(當做輸入參數)傳遞給機器學習算法。
import org.apache.spark.ml.feature.Word2Vec
// Input data: Each row is a bag of words from a sentence or document.
val documentDF = spark.createDataFrame(Seq(
"Hi I heard about Spark".split(" "),
"I wish Java could use case classes".split(" "),
"Logistic regression models are neat".split(" ")
).map(Tuple1.apply)).toDF("text")
// Learn a mapping from words to Vectors.
val word2Vec = new Word2Vec()
.setInputCol("text")
.setOutputCol("result")
.setVectorSize(3)
.setMinCount(0)
val model = word2Vec.fit(documentDF)
val result = model.transform(documentDF)
result.select("result").take(3).foreach(println)請閱讀英文原文Word2Vec Scala 文檔有關的 API 的詳細信息。
在Spark repo中”examples/src/main/scala/org/apache/spark/examples/ml/Word2VecExample.scala”下可以找到完整的示例代碼。
CountVectorizer
CountVectorizer和CountVectorizerModel旨在通過計數將文本文檔轉換為特征向量。當不存在先驗字典時,CountVectorizer可以作為Estimator提取詞匯,並生成CountVectorizerModel。該模型產生關於該文檔詞匯的稀疏表示(稀疏特征向量),這個表示(特征向量)可以傳遞給其他像 LDA 算法。
在擬合fitting過程中, CountVectorizer將根據語料庫中的詞頻排序選出前vocabSize個詞。其中一個配置參數minDF通過指定詞匯表中的詞語在文檔中出現的最小次數 (或詞頻 if < 1.0) ,影響擬合(fitting)的過程。另一個可配置的二進製toggle參數控製輸出向量。如果設置為 true 那麽所有非零計數設置為 1。這對於二元型離散概率模型非常有用。
Examples
假設我們有如下的DataFrame包含id和texts兩列:
id | texts
----|----------
0 | Array("a", "b", "c")
1 | Array("a", "b", "b", "c", "a")文本中每行都是一個文本類型的數組(字符串)。調用CountVectorizer產生詞匯表(a, b, c)的CountVectorizerModel模型,轉後後的輸出向量如下:
id | texts | vector
----|---------------------------------|---------------
0 | Array("a", "b", "c") | (3,[0,1,2],[1.0,1.0,1.0])
1 | Array("a", "b", "b", "c", "a") | (3,[0,1,2],[2.0,2.0,1.0])每個向量表示文檔詞匯表中每個詞語出現的次數
import org.apache.spark.ml.feature.{CountVectorizer, CountVectorizerModel}
val df = spark.createDataFrame(Seq(
(0, Array("a", "b", "c")),
(1, Array("a", "b", "b", "c", "a"))
)).toDF("id", "words")
// fit a CountVectorizerModel from the corpus
val cvModel: CountVectorizerModel = new CountVectorizer()
.setInputCol("words")
.setOutputCol("features")
.setVocabSize(3)
.setMinDF(2)
.fit(df)
// alternatively, define CountVectorizerModel with a-priori vocabulary
val cvm = new CountVectorizerModel(Array("a", "b", "c"))
.setInputCol("words")
.setOutputCol("features")
cvModel.transform(df).select("features").show()
請閱讀英文原文CountVectorizer Scala 文檔和CountVectorizerModel Scala 文檔了解相關的 API 的詳細信息。
在Spark repo中在”examples/src/main/scala/org/apache/spark/examples/ml/CountVectorizerExample.scala”找到完整的示例代碼。
Feature Transformers(特征變換)
Tokenizer(分詞器)
Tokenization(文本符號化)是將文本 (如一個句子)拆分成單詞的過程。(在Spark ML中)Tokenizer(分詞器)提供此功能。下麵的示例演示如何將句子拆分為詞的序列。
RegexTokenizer提供了(更高級的)基於正則表達式 (regex) 匹配的(對句子或文本的)單詞拆分。默認情況下,參數”pattern”(默認的正則表達式: “\\s+”) 作為分隔符用於拆分輸入的文本。或者,用戶可以將參數“gaps”設置為 false ,指定正則表達式”pattern”表示”tokens”,而不是分隔符,這樣作為分詞結果找到的所有匹配項。
import org.apache.spark.ml.feature.{RegexTokenizer, Tokenizer}
val sentenceDataFrame = spark.createDataFrame(Seq(
(0, "Hi I heard about Spark"),
(1, "I wish Java could use case classes"),
(2, "Logistic,regression,models,are,neat")
)).toDF("label", "sentence")
val tokenizer = new Tokenizer().setInputCol("sentence").setOutputCol("words")
val regexTokenizer = new RegexTokenizer()
.setInputCol("sentence")
.setOutputCol("words")
.setPattern("\\W") // alternatively .setPattern("\\w+").setGaps(false)
val tokenized = tokenizer.transform(sentenceDataFrame)
tokenized.select("words", "label").take(3).foreach(println)
val regexTokenized = regexTokenizer.transform(sentenceDataFrame)
regexTokenized.select("words", "label").take(3).foreach(println)
請閱讀英文原文Tokenizer Scala docs 和RegexTokenizer Scala docs了解相關的 API 的詳細信息。
|
[0,Hi I heard about Spark]
[1,I wish Java could use case classes]
[2,Logistic,regression,models,are,neat]
[WrappedArray(hi, i, heard, about, spark),0]
[WrappedArray(i, wish, java, could, use, case, classes),1]
[WrappedArray(logistic,regression,models,are,neat),2]
|
在Spark repo中在”examples/src/main/scala/org/apache/spark/examples/ml/TokenizerExample.scala”找到完整的示例代碼。
StopWordsRemover(停用字清除)
Stop words (停用字)是(在文檔中)頻繁出現,但未攜帶太多意義的詞語,它們不應該參與算法運算。
StopWordsRemover(的作用是)將輸入的字符串 (如分詞器Tokenizer的輸出)中的停用字刪除(後輸出)。停用字表由stopWords參數指定。對於某些語言的默認停止詞是通過調用StopWordsRemover.loadDefaultStopWords(language)設置的,可用的選項為”丹麥”,”荷蘭語”、”英語”、”芬蘭語”,”法國”,”德國”、”匈牙利”、”意大利”、”挪威”、”葡萄牙”、”俄羅斯”、”西班牙”、”瑞典”和”土耳其”。布爾型參數caseSensitive指示是否區分大小寫 (默認為否)。
Examples
假設有如下DataFrame,有id和raw兩列:
|
id | raw
—-|———-
0 | [I, saw, the, red, baloon]
1 | [Mary, had, a, little, lamb]
|
通過對raw列調用StopWordsRemover,我們可以得到篩選出的結果列如下:
|
id | raw | filtered
—-|—————————–|——————–
0 | [I, saw, the, red, baloon] | [saw, red, baloon]
1 | [Mary, had, a, little, lamb]|[Mary, little, lamb]
|
其中,“I”, “the”, “had”以及“a”被移除。
import org.apache.spark.ml.feature.StopWordsRemover
val remover = new StopWordsRemover()
.setInputCol("raw")
.setOutputCol("filtered")
val dataSet = spark.createDataFrame(Seq(
(0, Seq("I", "saw", "the", "red", "baloon")),
(1, Seq("Mary", "had", "a", "little", "lamb"))
)).toDF("id", "raw")
remover.transform(dataSet).show()
在Spark repo中路徑”examples/src/main/scala/org/apache/spark/examples/ml/StopWordsRemoverExample.scala”可以找到完整的示例代碼。
n-gram
一個 n-gram是一個長度為n(整數)的字的序列。NGram可以用來將輸入特征轉換成n-grams。
NGram 的輸入為一係列的字符串(例如:Tokenizer分詞器的輸出)。參數n表示每個n-gram中單詞(terms)的數量。NGram的輸出結果是多個n-grams構成的序列,其中,每個n-gram表示被空格分割出來的n個連續的單詞。如果輸入的字符串少於n個單詞,NGram輸出為空。
import org.apache.spark.ml.feature.NGram
val wordDataFrame = spark.createDataFrame(Seq(
(0, Array("Hi", "I", "heard", "about", "Spark")),
(1, Array("I", "wish", "Java", "could", "use", "case", "classes")),
(2, Array("Logistic", "regression", "models", "are", "neat"))
)).toDF("label", "words")
val ngram = new NGram().setInputCol("words").setOutputCol("ngrams").setN(2)
val ngramDataFrame = ngram.transform(wordDataFrame)
ngramDataFrame.take(3).map(_.getAs[Stream[String]]("ngrams").toList).foreach(println)
請閱讀英文原文 NGram Scala docs了解相關的 API 的詳細信息。
在Spark repo中路徑”examples/src/main/scala/org/apache/spark/examples/ml/NGramExample.scala”裏可以找到完整的示例代碼。
Binarizer(二元化方法)
二元化(Binarization)是通過(選定的)閾值將數值化的特征轉換成二進製(0/1)特征表示的過程。
Binarizer(ML提供的二元化方法)二元化涉及的參數有inputCol(輸入)、outputCol(輸出)以及threshold(閥值)。(輸入的)特征值大於閥值將映射為1.0,特征值小於等於閥值將映射為0.0。(Binarizer)支持向量(Vector)和雙精度(Double)類型的輸出
import org.apache.spark.ml.feature.Binarizer
val data = Array((0, 0.1), (1, 0.8), (2, 0.2))
val dataFrame = spark.createDataFrame(data).toDF("label", "feature")
val binarizer: Binarizer = new Binarizer()
.setInputCol("feature")
.setOutputCol("binarized_feature")
.setThreshold(0.5)
val binarizedDataFrame = binarizer.transform(dataFrame)
val binarizedFeatures = binarizedDataFrame.select("binarized_feature")
binarizedFeatures.collect().foreach(println)
請閱讀英文原文 Binarizer Scala docs了解相關的 API 的詳細信息。
在Spark repo中路徑”examples/src/main/scala/org/apache/spark/examples/ml/BinarizerExample.scala”裏可以找到完整的示例代碼
PCA(主成成分分析)
主成分分析是一種統計學方法,它使用正交轉換從一係列可能線性相關的變量中提取線性無關變量集,提取出的變量集中的元素稱為主成分(principal components)。(ML中)PCA 類通過PCA
方法對項目向量進行降維。下麵的示例介紹如何將5維特征向量轉換為3維主成分向量。
import org.apache.spark.ml.feature.PCA
import org.apache.spark.ml.linalg.Vectors
val data = Array(
Vectors.sparse(5, Seq((1, 1.0), (3, 7.0))),
Vectors.dense(2.0, 0.0, 3.0, 4.0, 5.0),
Vectors.dense(4.0, 0.0, 0.0, 6.0, 7.0)
)
val df = spark.createDataFrame(data.map(Tuple1.apply)).toDF("features")
val pca = new PCA()
.setInputCol("features")
.setOutputCol("pcaFeatures")
.setK(3)
.fit(df)
val pcaDF = pca.transform(df)
val result = pcaDF.select("pcaFeatures")
result.show()
請閱讀英文原文 PCA Scala docs了解相關的 API 的詳細信息。
在Spark repo中路徑”examples/src/main/scala/org/apache/spark/examples/ml/PCAExample.scala”裏可以找到完整的示例代碼
PolynomialExpansion(多項式擴展)
多項式擴展(Polynomial expansion)是將n維的原始特征組合擴展到多項式空間的過程。(ML中) PolynomialExpansion 提供多項式擴展的功能。下麵的示例會介紹如何將你的特征集拓展到3維多項式空間。
import org.apache.spark.ml.feature.PolynomialExpansion
import org.apache.spark.ml.linalg.Vectors
val data = Array(
Vectors.dense(-2.0, 2.3),
Vectors.dense(0.0, 0.0),
Vectors.dense(0.6, -1.1)
)
val df = spark.createDataFrame(data.map(Tuple1.apply)).toDF("features")
val polynomialExpansion = new PolynomialExpansion()
.setInputCol("features")
.setOutputCol("polyFeatures")
.setDegree(3)
val polyDF = polynomialExpansion.transform(df)
polyDF.select("polyFeatures").take(3).foreach(println)
請閱讀英文原文 PolynomialExpansion Scala docs 了解相關的 API 的詳細信息。
在Spark repo中路徑”examples/src/main/scala/org/apache/spark/examples/ml/PolynomialExpansionExample.scala”裏可以找到完整的示例代碼
Discrete Cosine Transform (DCT-離散餘弦變換)
The Discrete Cosine Transform transforms a length N N real-valued sequence in the time domain into another length N N real-valued sequence in the frequency domain. A DCT class provides this functionality, implementing the DCT-II and scaling the result by 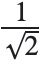 such that the representing matrix for the transform is unitary. No shift is applied to the transformed sequence (e.g. the 0 0th element of the transformed sequence is the 0 0th DCT coefficient and not the N /2 N/2th).
such that the representing matrix for the transform is unitary. No shift is applied to the transformed sequence (e.g. the 0 0th element of the transformed sequence is the 0 0th DCT coefficient and not the N /2 N/2th).
離散餘弦變換(Discrete Cosine Transform) 是將時域的N維實數序列轉換成頻域的N維實數序列的過程(有點類似離散傅裏葉變換)。(ML中的)DCT類提供了離散餘弦變換DCT-II的功能,將離散餘弦變換後結果乘以得到一個與時域矩陣長度一致的矩陣。輸入序列與輸出之間是一一對應的。
import org.apache.spark.ml.feature.DCT
import org.apache.spark.ml.linalg.Vectors
val data = Seq(
Vectors.dense(0.0, 1.0, -2.0, 3.0),
Vectors.dense(-1.0, 2.0, 4.0, -7.0),
Vectors.dense(14.0, -2.0, -5.0, 1.0))
val df = spark.createDataFrame(data.map(Tuple1.apply)).toDF("features")
val dct = new DCT()
.setInputCol("features")
.setOutputCol("featuresDCT")
.setInverse(false)
val dctDf = dct.transform(df)
dctDf.select("featuresDCT").show(3)
請閱讀英文原文 DCT Scala docs 了解相關的 API 的詳細信息。
在Spark repo中路徑”examples/src/main/scala/org/apache/spark/examples/ml/DCTExample.scala”裏可以找到完整的示例代碼
StringIndexer(字符串-索引變換)
StringIndexer(字符串-索引變換)將字符串的(以單詞為)標簽編碼成標簽索引(表示)。標簽索引序列的取值範圍是[0,numLabels(字符串中所有出現的單詞去掉重複的詞後的總和)],按照標簽出現頻率排序,出現最多的標簽索引為0。如果輸入是數值型,我們先將數值映射到字符串,再對字符串進行索引化。如果下遊的pipeline(例如:Estimator或者Transformer)需要用到索引化後的標簽序列,則需要將這個pipeline的輸入列名字指定為索引化序列的名字。大部分情況下,通過setInputCol設置輸入的列名。
Examples
假設我們有如下的DataFrame,包含有id和category兩列
|
id | category
—-|———-
0 | a
1 | b
2 | c
3 | a
4 | a
5 | c
|
標簽類別(category)是有3種取值的標簽:“a”,“b”,“c”。使用StringIndexer通過category進行轉換成categoryIndex後可以得到如下結果:
|
id | category | categoryIndex
—-|———-|—————
0 | a | 0.0
1 | b | 2.0
2 | c | 1.0
3 | a | 0.0
4 | a | 0.0
5 | c | 1.0
|
“a”因為出現的次數最多,所以得到為0的索引(index)。“c”得到1的索引,“b”得到2的索引
另外,StringIndexer在轉換新數據時提供兩種容錯機製處理訓練中沒有出現的標簽
- StringIndexer拋出異常錯誤(默認值)
- 跳過未出現的標簽實例。
Examples
回顧一下上一個例子,這次我們將繼續使用上一個例子訓練出來的StringIndexer處理下麵的數據集
|
id | category
—-|———-
0 | a
1 | b
2 | c
3 | d
|
如果沒有在StringIndexer裏麵設置未訓練過(unseen)的標簽的處理或者設置未“error”,運行時會遇到程序拋出異常。當然,也可以通過設置setHandleInvalid(“skip”),得到如下的結果
|
id | category | categoryIndex
—-|———-|—————
0 | a | 0.0
1 | b | 2.0
2 | c | 1.0
|
注意:輸出裏麵沒有出現“d”
import org.apache.spark.ml.feature.StringIndexer
val df = spark.createDataFrame(
Seq((0, "a"), (1, "b"), (2, "c"), (3, "a"), (4, "a"), (5, "c"))
).toDF("id", "category")
val indexer = new StringIndexer()
.setInputCol("category")
.setOutputCol("categoryIndex")
val indexed = indexer.fit(df).transform(df)
indexed.show()
請閱讀英文原文 StringIndexer Scala docs了解相關的 API 的詳細信息。
在Spark repo中路徑”examples/src/main/scala/org/apache/spark/examples/ml/StringIndexerExample.scala”裏可以找到完整的示例代碼
IndexToString(索引-字符串變換)
與StringIndexer對應,IndexToString將索引化標簽還原成原始字符串。一個常用的場景是先通過StringIndexer產生索引化標簽,然後使用索引化標簽進行訓練,最後再對預測結果使用IndexToString來獲取其原始的標簽字符串。
Examples
假設我們有如下的DataFrame包含id和categoryIndex兩列:
|
id | categoryIndex
—-|—————
0 | 0.0
1 | 2.0
2 | 1.0
3 | 0.0
4 | 0.0
5 | 1.0
|
使用IndexToString我們可以獲取其原始的標簽字符串如下:
|
id | categoryIndex | originalCategory
—-|—————|—————–
0 | 0.0 | a
1 | 2.0 | b
2 | 1.0 | c
3 | 0.0 | a
4 | 0.0 | a
5 | 1.0 | c
|
import org.apache.spark.ml.feature.{IndexToString, StringIndexer}
val df = spark.createDataFrame(Seq(
(0, "a"),
(1, "b"),
(2, "c"),
(3, "a"),
(4, "a"),
(5, "c")
)).toDF("id", "category")
val indexer = new StringIndexer()
.setInputCol("category")
.setOutputCol("categoryIndex")
.fit(df)
val indexed = indexer.transform(df)
val converter = new IndexToString()
.setInputCol("categoryIndex")
.setOutputCol("originalCategory")
val converted = converter.transform(indexed)
converted.select("id", "originalCategory").show()
請閱讀英文原文 IndexToString Scala docs 了解相關的 API 的詳細信息。
在Spark repo中路徑”examples/src/main/scala/org/apache/spark/examples/ml/IndexToStringExample.scala”裏可以找到完整的示例代碼
OneHotEncoder(獨熱編碼)
獨熱編碼(One-hot encoding)將類別特征映射為二進製向量,其中隻有一個有效值(為1,其餘為0)。這樣在諸如Logistic回歸這樣需要連續數值值作為特征輸入的分類器中也可以使用類別(離散)特征
import org.apache.spark.ml.feature.{OneHotEncoder, StringIndexer}
val df = spark.createDataFrame(Seq(
(0, "a"),
(1, "b"),
(2, "c"),
(3, "a"),
(4, "a"),
(5, "c")
)).toDF("id", "category")
val indexer = new StringIndexer()
.setInputCol("category")
.setOutputCol("categoryIndex")
.fit(df)
val indexed = indexer.transform(df)
val encoder = new OneHotEncoder()
.setInputCol("categoryIndex")
.setOutputCol("categoryVec")
val encoded = encoder.transform(indexed)
encoded.select("id", "categoryVec").show()
請閱讀英文原文 OneHotEncoder Scala docs了解相關的 API 的詳細信息。
在Spark repo中路徑”examples/src/main/scala/org/apache/spark/examples/ml/OneHotEncoderExample.scala”裏可以找到完整的示例代碼
VectorIndexer(向量類型索引化)
VectorIndexer是對數據集特征向量中的類別特征(index categorical features categorical features ,eg:枚舉類型)進行編號索引。它能夠自動判斷那些特征是可以重新編號的類別型,並對他們進行重新編號索引,具體做法如下:
1.獲得一個向量類型的輸入以及maxCategories參數。
2.基於原始向量數值識別哪些特征需要被類別化:特征向量中某一個特征不重複取值個數小於等於maxCategories則認為是可以重新編號索引的。某一個特征不重複取值個數大於maxCategories,則該特征視為連續值,不會重新編號(不會發生任何改變)
3.對於每一個可編號索引的類別特征重新編號為0~K(K<=maxCategories-1)。
4.對類別特征原始值用編號後的索引替換掉。
索引後的類別特征可以幫助決策樹等算法處理類別型特征,提高性能。
在下麵的例子中,我們讀入一個數據集,然後使用VectorIndexer來決定哪些類別特征需要被作為索引類型處理,將類型特征轉換為他們的索引。轉換後的數據可以傳遞給DecisionTreeRegressor之類的算法出來類型特征。
簡單理解一下:以C為例,假如一個星期的枚舉型的類型enum weekday{ sun = 4,mou =5, tue =6, wed = 7, thu =8, fri = 9, sat =10 };如果需要進行這個特征帶入運算,可以將這些枚舉數值重新編號為 { sun = 0 , mou =1, tue =2, wed = 3, thu =4, fri = 5, sat =6 },通常是出現次數越多的枚舉,編號越小(從0開始)
import org.apache.spark.ml.feature.VectorIndexer
//val data = spark.read.format("libsvm").load("data/mllib/sample_libsvm_data.txt")
val data1 = Seq(
Vectors.dense(2, 5, 7, 3),
Vectors.dense(4, 2, 4, 7),
Vectors.dense(5, 3, 4, 7),
Vectors.dense(6, 2, 4, 7),
Vectors.dense(7, 2, 4, 7),
Vectors.dense(8, 2, 5, 1))
val data = spark.createDataFrame(data1.map(Tuple1.apply)).toDF("features")
val indexer = new VectorIndexer()
.setInputCol("features")
.setOutputCol("indexed")
.setMaxCategories(10)
val indexerModel = indexer.fit(data)
val categoricalFeatures: Set[Int] = indexerModel.categoryMaps.keys.toSet
println(s"Chose ${categoricalFeatures.size} categorical features: " +
categoricalFeatures.mkString(", "))
// Create new column "indexed" with categorical values transformed to indices
val indexedData = indexerModel.transform(data)
indexedData.show()
請閱讀英文原文 VectorIndexer Scala docs 了解相關的 API 的詳細信息。
在Spark repo中路徑”examples/src/main/scala/org/apache/spark/examples/ml/VectorIndexerExample.scala”裏可以找到完整的示例代碼
Normalizer(範數p-norm規範化)
Normalizer是一個轉換器,它可以將一組特征向量(通過計算p-範數)規範化。參數為p(默認值:2)來指定規範化中使用的p-norm。規範化操作可以使輸入數據標準化,對後期機器學習算法的結果也有更好的表現。
下麵的例子展示如何讀入一個libsvm格式的數據,然後將每一行轉換為L2以及L∞形式。
import org.apache.spark.ml.feature.Normalizer
val dataFrame = spark.read.format("libsvm").load("data/mllib/sample_multiclass_classification_data.txt")
// Normalize each Vector using $L^1$ norm.
val normalizer = new Normalizer()
.setInputCol("features")
.setOutputCol("normFeatures")
.setP(1.0)
val l1NormData = normalizer.transform(dataFrame)
l1NormData.show()
val l2NormData = normalizer.transform(dataFrame, normalizer.p -> 2)
l2NormData.show(10, false)
// Normalize each Vector using $L^\infty$ norm.
val lInfNormData = normalizer.transform(dataFrame, normalizer.p -> Double.PositiveInfinity)
lInfNormData.show()
請閱讀英文原文 Normalizer Scala docs 了解相關的 API 的詳細信息。
在Spark repo中路徑”examples/src/main/scala/org/apache/spark/examples/ml/NormalizerExample.scala”裏可以找到完整的示例代碼
StandardScaler
StandardScaler(z-score規範化:零均值標準化)可以將輸入的一組Vector特征向量規範化(標準化),使其有統一的的標準差(均方差?)以及均值為0。它需要如下參數:
1. withStd:默認值為真,將數據縮放到統一標準差方式。
2. withMean:默認為假。將均值為0。該方法將產出一個稠密的輸出向量,所以不適用於稀疏向量。
StandardScaler是一個Estimator,它可以通過擬合(fit)數據集產生一個StandardScalerModel,用來統計匯總。StandardScalerModel可以用來將向量轉換至統一的標準差以及(或者)零均值特征。
注意如果特征的標準差為零,則該特征在向量中返回的默認值為0.0。
下麵的示例展示如果讀入一個libsvm形式的數據以及返回有統一標準差的標準化特征。
import org.apache.spark.ml.feature.StandardScaler
val dataFrame = spark.read.format("libsvm").load("data/mllib/sample_libsvm_data.txt")
val scaler = new StandardScaler()
.setInputCol("features")
.setOutputCol("scaledFeatures")
.setWithStd(true)
.setWithMean(false)
// Compute summary statistics by fitting the StandardScaler.
val scalerModel = scaler.fit(dataFrame)
// Normalize each feature to have unit standard deviation.
val scaledData = scalerModel.transform(dataFrame)
scaledData.show()
請閱讀英文原文StandardScaler Scala docs了解相關的 API 的詳細信息。
在Spark repo中路徑”examples/src/main/scala/org/apache/spark/examples/ml/StandardScalerExample.scala”裏可以找到完整的示例代碼
MinMaxScaler(最大-最小規範化)
2. max:默認為1.0,為轉換後所有特征的上邊界。
MinMaxScaler根據數據集的匯總統計產生一個MinMaxScalerModel。在計算時,該模型將特征向量一個一個分開計算並轉換到指定的範圍內的。
對於特征E來說,調整後的特征值如下:
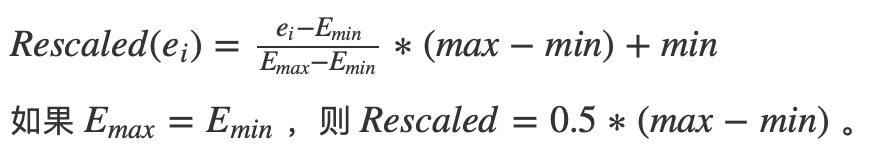
注意:(1)最大最小值可能受到離群值的左右。(2)零值可能會轉換成一個非零值,因此稀疏矩陣將變成一個稠密矩陣。
下麵的示例展示如何讀入一個libsvm形式的數據以及調整其特征值到[0,1]之間。
import org.apache.spark.ml.feature.MinMaxScaler
val dataFrame = spark.read.format("libsvm").load("data/mllib/sample_libsvm_data.txt")
val scaler = new MinMaxScaler()
.setInputCol("features")
.setOutputCol("scaledFeatures")
// Compute summary statistics and generate MinMaxScalerModel
val scalerModel = scaler.fit(dataFrame)
// rescale each feature to range [min, max].
val scaledData = scalerModel.transform(dataFrame)
scaledData.show()
請閱讀英文原文MinMaxScaler Scala docs 和 MinMaxScalerModel Scala docs 了解相關的 API 的詳細信息。
在Spark repo中路徑”examples/src/main/scala/org/apache/spark/examples/ml/MinMaxScalerExample.scala”裏可以找到完整的示例代碼
MaxAbsScaler(絕對值規範化)
MaxAbsScaler使用每個特征的最大值的絕對值將輸入向量的特征值(各特征值除以最大絕對值)轉換到[-1,1]之間。因為它不會轉移/集中數據,所以不會破壞數據的稀疏性。
下麵的示例展示如果讀入一個libsvm形式的數據以及調整其特征值到[-1,1]之間。
import org.apache.spark.ml.feature.MaxAbsScaler
val dataFrame = spark.read.format("libsvm").load("data/mllib/sample_libsvm_data.txt")
val scaler = new MaxAbsScaler()
.setInputCol("features")
.setOutputCol("scaledFeatures")
// Compute summary statistics and generate MaxAbsScalerModel
val scalerModel = scaler.fit(dataFrame)
// rescale each feature to range [-1, 1]
val scaledData = scalerModel.transform(dataFrame)
scaledData.show()
請閱讀英文原文 MaxAbsScaler Scala docs 和 MaxAbsScalerModel Scala docs 了解相關的 API 的詳細信息。
在Spark repo中路徑”examples/src/main/scala/org/apache/spark/examples/ml/MaxAbsScalerExample.scala”裏可以找到完整的示例代碼
Bucketizer(分箱器)
Bucketizer將一列連續的特征轉換為(離散的)特征區間,區間由用戶指定。參數如下:
splits(分箱數):分箱數為n+1時,將產生n個區間。除了最後一個區間外,每個區間範圍[x,y]由分箱的x,y決定。分箱必須是嚴格遞增的。分箱(區間)見在分箱(區間)指定外的值將被歸為錯誤。兩個分裂的例子為Array(Double.NegativeInfinity, 0.0, 1.0, Double.PositiveInfinity)以及Array(0.0, 1.0, 2.0)。
注意:
- 當不確定分裂的上下邊界時,應當添加Double.NegativeInfinity和Double.PositiveInfinity以免越界。
- 分箱區間必須嚴格遞增,例如: s0 < s1 < s2 < … < sn
下麵將展示Bucketizer的使用方法。
import org.apache.spark.ml.feature.Bucketizer
val splits = Array(Double.NegativeInfinity, -0.5, 0.0, 0.5, Double.PositiveInfinity)
val data = Array(-0.5, -0.3, 0.0, 0.2)
val dataFrame = spark.createDataFrame(data.map(Tuple1.apply)).toDF("features")
val bucketizer = new Bucketizer()
.setInputCol("features")
.setOutputCol("bucketedFeatures")
.setSplits(splits)
// Transform original data into its bucket index.
val bucketedData = bucketizer.transform(dataFrame)
bucketedData.show()
請閱讀英文原文 Bucketizer Scala docs了解相關的 API 的詳細信息。
在Spark repo中路徑”examples/src/main/scala/org/apache/spark/examples/ml/BucketizerExample.scala”裏可以找到完整的示例代碼
ElementwiseProduct (Hadamard乘積)
ElementwiseProduct對輸入向量的每個元素乘以一個權重(weight),即對輸入向量每個元素逐個進行放縮。對輸入向量v 和變換向量scalingVec 使用Hadamard product(阿達瑪積)進行變換,最終產生一個新的向量。用向量 w 表示 scalingVec ,則Hadamard product可以表示為

下麵例子展示如何通過轉換向量的值來調整向量。
import org.apache.spark.ml.feature.ElementwiseProduct
import org.apache.spark.ml.linalg.Vectors
// Create some vector data; also works for sparse vectors
val dataFrame = spark.createDataFrame(Seq(
("a", Vectors.dense(1.0, 2.0, 3.0)),
("b", Vectors.dense(4.0, 5.0, 6.0)))).toDF("id", "vector")
val transformingVector = Vectors.dense(0.0, 1.0, 2.0)
val transformer = new ElementwiseProduct()
.setScalingVec(transformingVector)
.setInputCol("vector")
.setOutputCol("transformedVector")
// Batch transform the vectors to create new column:
transformer.transform(dataFrame).show()
請閱讀英文原文 ElementwiseProduct Scala docs 了解相關的 API 的詳細信息。
在Spark repo中路徑”examples/src/main/scala/org/apache/spark/examples/ml/ElementwiseProductExample.scala”裏可以找到完整的示例代碼
SQLTransformer(SQL變換)
SQLTransformer用來轉換由SQL定義的陳述。目前僅支持SQL語法如”SELECT … FROM __THIS__ …”,其中”__THIS__”代表輸入數據的基礎表。選擇語句指定輸出中展示的字段、元素和表達式,支持Spark SQL中的所有選擇語句。用戶可以基於選擇結果使用Spark SQL建立方程或者用戶自定義函數(UDFs)。SQLTransformer支持語法示例如下:
- SELECT a, a + b AS a_b FROM __THIS__
- SELECT a, SQRT(b) AS b_sqrt FROM __THIS__ where a > 5
- SELECT a, b, SUM(c) AS c_sum FROM __THIS__ GROUP BY a, b
Examples
假設我們有如下DataFrame包含id,v1,v2列:
|
id | v1 | v2
—-|—–|—–
0 | 1.0 | 3.0
2 | 2.0 | 5.0
|
使用SQLTransformer語句”SELECT *, (v1 + v2) AS v3, (v1 * v2) AS v4 FROM __THIS__”轉換後得到輸出如下:
|
id | v1 | v2 | v3 | v4
—-|—–|—–|—–|—–
0 | 1.0 | 3.0 | 4.0 | 3.0
2 | 2.0 | 5.0 | 7.0 |10.0
|
|
1
2
3
4
5
6
7
8
9
|
import org.apache.spark.ml.feature.SQLTransformer
val df = spark.createDataFrame(
Seq((0, 1.0, 3.0), (2, 2.0, 5.0))).toDF(“id”, “v1”, “v2”)
val sqlTrans = new SQLTransformer().setStatement(
“SELECT *, (v1 + v2) AS v3, (v1 * v2) AS v4 FROM __THIS__”)
sqlTrans.transform(df).show()
|
請閱讀英文原文 SQLTransformer Scala docs 了解相關的 API 的詳細信息。
在Spark repo中路徑”examples/src/main/scala/org/apache/spark/examples/ml/SQLTransformerExample.scala”裏可以找到完整的示例代碼
VectorAssembler(特征向量合並)
Examples
|
id | hour | mobile | userFeatures | clicked
—-|——|——–|——————|———
0 | 18 | 1.0 | [0.0, 10.0, 0.5] | 1.0
|
userFeatures列中含有3個用戶特征,我們將hour, mobile以及userFeatures合並為一個新的單一特征向量。將VectorAssembler的輸入指定為hour, mobile以及userFeatures,輸出指定為features,通過轉換我們將得到以下結果:
|
id | hour | mobile | userFeatures | clicked | features
—-|——|——–|——————|———|—————————–
0 | 18 | 1.0 | [0.0, 10.0, 0.5] | 1.0 | [18.0, 1.0, 0.0, 10.0, 0.5]
|
import org.apache.spark.ml.feature.VectorAssembler
import org.apache.spark.ml.linalg.Vectors
val dataset = spark.createDataFrame(
Seq((0, 18, 1.0, Vectors.dense(0.0, 10.0, 0.5), 1.0))
).toDF("id", "hour", "mobile", "userFeatures", "clicked")
val assembler = new VectorAssembler()
.setInputCols(Array("hour", "mobile", "userFeatures"))
.setOutputCol("features")
val output = assembler.transform(dataset)
println(output.select("features", "clicked").first())
請閱讀英文原文 VectorAssembler Scala docs了解相關的 API 的詳細信息。
在Spark repo中路徑”examples/src/main/scala/org/apache/spark/examples/ml/VectorAssemblerExample.scala”裏可以找到完整的示例代碼
QuantileDiscretizer(分位數離散化)
QuantileDiscretizer(分位數離散化)將一列連續型的特征向量轉換成分類型數據向量。分級的數量由numBuckets參數決定。分級的範圍由漸進算法(approxQuantile )決定。
漸進的精度由relativeError參數決定。當relativeError設置為0時,將會計算精確的分位點(計算代價較高)。分級的上下邊界為負無窮(-Infinity)到正無窮(+Infinity),覆蓋所有的實數值。
Examples
假設我們有如下DataFrame包含id, hour:
|
id | hour
—-|——
0 | 18.0
—-|——
1 | 19.0
—-|——
2 | 8.0
—-|——
3 | 5.0
—-|——
4 | 2.2
|
hour是一個Double類型的連續特征,我們希望將它轉換成分級特征。將參數numBuckets設置為3,可以如下分級特征
|
id | hour | result
—-|——|——
0 | 18.0 | 2.0
—-|——|——
1 | 19.0 | 2.0
—-|——|——
2 | 8.0 | 1.0
—-|——|——
3 | 5.0 | 1.0
—-|——|——
4 | 2.2 | 0.0
|
|
1
2
3
4
5
6
7
8
9
10
11
12
|
import org.apache.spark.ml.feature.QuantileDiscretizer
val data = Array((0, 18.0), (1, 19.0), (2, 8.0), (3, 5.0), (4, 2.2))
var df = spark.createDataFrame(data).toDF(“id”, “hour”)
val discretizer = new QuantileDiscretizer()
.setInputCol(“hour”)
.setOutputCol(“result”)
.setNumBuckets(3)
val result = discretizer.fit(df).transform(df)
result.show()
|
請閱讀英文原文 QuantileDiscretizer Scala docs了解相關的 API 的詳細信息。
在Spark repo中路徑”examples/src/main/scala/org/apache/spark/examples/ml/QuantileDiscretizerExample.scala”裏可以找到完整的示例代碼
Feature Selectors(特征選擇)
VectorSlicer(向量選擇)
- 整數索引,setIndices()。
- 字符串索引,setNames(),此類要求向量列有AttributeGroup,因為該工具根據Attribute來匹配屬性字段。
可以指定整數或者字符串類型。另外,也可以同時使用整數索引和字符串名字。不允許使用重複的特征,所以所選的索引或者名字必須是獨一的。注意如果使用名字特征,當遇到空值的時候將會拋異常。
輸出將會首先按照所選的數字索引排序(按輸入順序),其次按名字排序(按輸入順序)。
|
userFeatures
——————
[0.0, 10.0, 0.5]
|
userFeatures是一個包含3個用戶特征的特征向量。假設userFeatures的第一列全為0,我們希望刪除它並且隻選擇後兩項。我們可以通過索引setIndices(1, 2)來選擇後兩項並產生一個新的features列:
|
userFeatures | features
——————|—————————–
[0.0, 10.0, 0.5] | [10.0, 0.5]
|
假設我們還有如同[“f1”, “f2”, “f3”]的屬性,可以通過名字setNames(“f2”, “f3”)的形式來選擇:
|
userFeatures | features
——————|—————————–
[0.0, 10.0, 0.5] | [10.0, 0.5]
[“f1”, “f2”, “f3”] | [“f2”, “f3”]
|
import java.util.Arrays
import org.apache.spark.ml.attribute.{Attribute, AttributeGroup, NumericAttribute}
import org.apache.spark.ml.feature.VectorSlicer
import org.apache.spark.ml.linalg.Vectors
import org.apache.spark.sql.Row
import org.apache.spark.sql.types.StructType
val data = Arrays.asList(Row(Vectors.dense(-2.0, 2.3, 0.0)))
val defaultAttr = NumericAttribute.defaultAttr
val attrs = Array("f1", "f2", "f3").map(defaultAttr.withName)
val attrGroup = new AttributeGroup("userFeatures", attrs.asInstanceOf[Array[Attribute]])
val dataset = spark.createDataFrame(data, StructType(Array(attrGroup.toStructField())))
val slicer = new VectorSlicer().setInputCol("userFeatures").setOutputCol("features")
slicer.setIndices(Array(1)).setNames(Array("f3"))
// or slicer.setIndices(Array(1, 2)), or slicer.setNames(Array("f2", "f3"))
val output = slicer.transform(dataset)
println(output.select("userFeatures", "features").first())
請閱讀英文原文 VectorSlicer Scala docs了解相關的 API 的詳細信息。
在Spark repo中路徑”examples/src/main/scala/org/apache/spark/examples/ml/VectorSlicerExample.scala”裏可以找到完整的示例代碼
RFormula(R模型公式)
RFormula通過R模型公式(R model formula)來將數據中的字段轉換成特征值。ML隻支持R操作中的部分操作,包括‘~’, ‘.’, ‘:’, ‘+’以及‘-‘,基本操作如下:
- ~分隔目標和對象
- +合並對象,“+ 0”意味著刪除空格
- :交互(數值相乘,類別二元化)
- . 除了目標外的全部列
假設有雙精度的a和b兩列,RFormula的使用用例如下
- y ~ a + b表示模型y ~ w0 + w1 * a +w2 * b其中w0為截距,w1和w2為相關係數。
- y ~a + b + a:b – 1表示模型y ~ w1* a + w2 * b + w3 * a * b,其中w1,w2,w3是相關係數。
RFormula產生一個特征向量和一個double或者字符串標簽列(label)。就如R中使用formulas一樣,字符型的輸入將轉換成one-hot編碼,數字輸入轉換成雙精度。如果類別列是字符串類型,它將通過StringIndexer轉換為double類型索引。如果標簽列不存在,則formulas輸出中將通過特定的響應變量創造一個標簽列。
Examples
假設我們有一個DataFrame含有id,country, hour和clicked四列:
|
id | country | hour | clicked
—|———|——|———
7 | “US” | 18 | 1.0
8 | “CA” | 12 | 0.0
9 | “NZ” | 15 | 0.0
|
如果使用RFormula公式clicked ~ country + hour,則表明我們希望基於country 和hour預測clicked,通過轉換我們可以得到如下DataFrame:
|
id | country | hour | clicked | features | label
—|———|——|———|——————|——-
7 | “US” | 18 | 1.0 | [0.0, 0.0, 18.0] | 1.0
8 | “CA” | 12 | 0.0 | [0.0, 1.0, 12.0] | 0.0
9 | “NZ” | 15 | 0.0 | [1.0, 0.0, 15.0] | 0.0
|
import org.apache.spark.ml.feature.RFormula
val dataset = spark.createDataFrame(Seq(
(7, "US", 18, 1.0),
(8, "CA", 12, 0.0),
(9, "NZ", 15, 0.0)
)).toDF("id", "country", "hour", "clicked")
val formula = new RFormula()
.setFormula("clicked ~ country + hour")
.setFeaturesCol("features")
.setLabelCol("label")
val output = formula.fit(dataset).transform(dataset)
output.select("features", "label").show()
請閱讀英文原文 RFormula Scala docs了解相關的 API 的詳細信息。
在Spark repo中路徑”examples/src/main/scala/org/apache/spark/examples/ml/RFormulaExample.scala”裏可以找到完整的示例代碼
ChiSqSelector(卡方特征選擇)
ChiSqSelector代表卡方特征選擇。它適用於帶有類別特征的標簽數據。ChiSqSelector根據分類的卡方獨立性檢驗來對特征排序,然後選取類別標簽最主要依賴的特征。它類似於選取最有預測能力的特征。
Examples
假設我們有一個DataFrame含有id, features和clicked三列,其中clicked為需要預測的目標:
|
id | features | clicked
—|———————–|———
7 | [0.0, 0.0, 18.0, 1.0] | 1.0
8 | [0.0, 1.0, 12.0, 0.0] | 0.0
9 | [1.0, 0.0, 15.0, 0.1] | 0.0
|
|
id | features | clicked | selectedFeatures
—|———————–|———|——————
7 | [0.0, 0.0, 18.0, 1.0] | 1.0 | [1.0]
8 | [0.0, 1.0, 12.0, 0.0] | 0.0 | [0.0]
9 | [1.0, 0.0, 15.0, 0.1] | 0.0 | [0.1]
|
import org.apache.spark.ml.feature.ChiSqSelector
import org.apache.spark.ml.linalg.Vectors
val data = Seq(
(7, Vectors.dense(0.0, 0.0, 18.0, 1.0), 1.0),
(8, Vectors.dense(0.0, 1.0, 12.0, 0.0), 0.0),
(9, Vectors.dense(1.0, 0.0, 15.0, 0.1), 0.0)
)
val df = spark.createDataset(data).toDF("id", "features", "clicked")
val selector = new ChiSqSelector()
.setNumTopFeatures(1)
.setFeaturesCol("features")
.setLabelCol("clicked")
.setOutputCol("selectedFeatures")
val result = selector.fit(df).transform(df)
result.show()
請閱讀英文原文 ChiSqSelector Scala docs 了解相關的 API 的詳細信息。
在Spark repo中路徑”examples/src/main/scala/org/apache/spark/examples/ml/ChiSqSelectorExample.scala”裏可以找到完整的示例代碼
參考:
[1] https://zhuanlan.zhihu.com/liulingyuan
[2] http://blog.csdn.net/qq_34531825/article/details/52415838
[3] http://www.apache.wiki/display/Spark/Extracting%2C+transforming+and+selecting+features