tidy函数从扫帚包可用于rset和rsplit用于生成 tibbles 的对象,其中的行位于分析和评估集中。
用法
# S3 method for rsplit
tidy(x, unique_ind = TRUE, ...)
# S3 method for rset
tidy(x, unique_ind = TRUE, ...)
# S3 method for vfold_cv
tidy(x, ...)
# S3 method for nested_cv
tidy(x, unique_ind = TRUE, ...)参数
- x
-
rset或rsplit对象 - unique_ind
-
是否应该返回唯一的行标识符?例如,如果
FALSE,则引导结果将包括原始数据中同一行的样本中的多行。 - ...
-
这些点用于将来的扩展,并且必须为空。
值
包含 Row 和 Data 列的小标题。后者的可能值是"Analysis" 或"Assessment"。对于 rset 输入,还会返回标识列,但它们的名称和值取决于重采样的类型。 vfold_cv 包含一列 "Fold",如果使用重复,则另一列称为 "Repeats"。 bootstraps 和mc_cv 使用列"Resample"。
例子
library(ggplot2)
theme_set(theme_bw())
set.seed(4121)
cv <- tidy(vfold_cv(mtcars, v = 5))
ggplot(cv, aes(x = Fold, y = Row, fill = Data)) +
geom_tile() +
scale_fill_brewer()
 set.seed(4121)
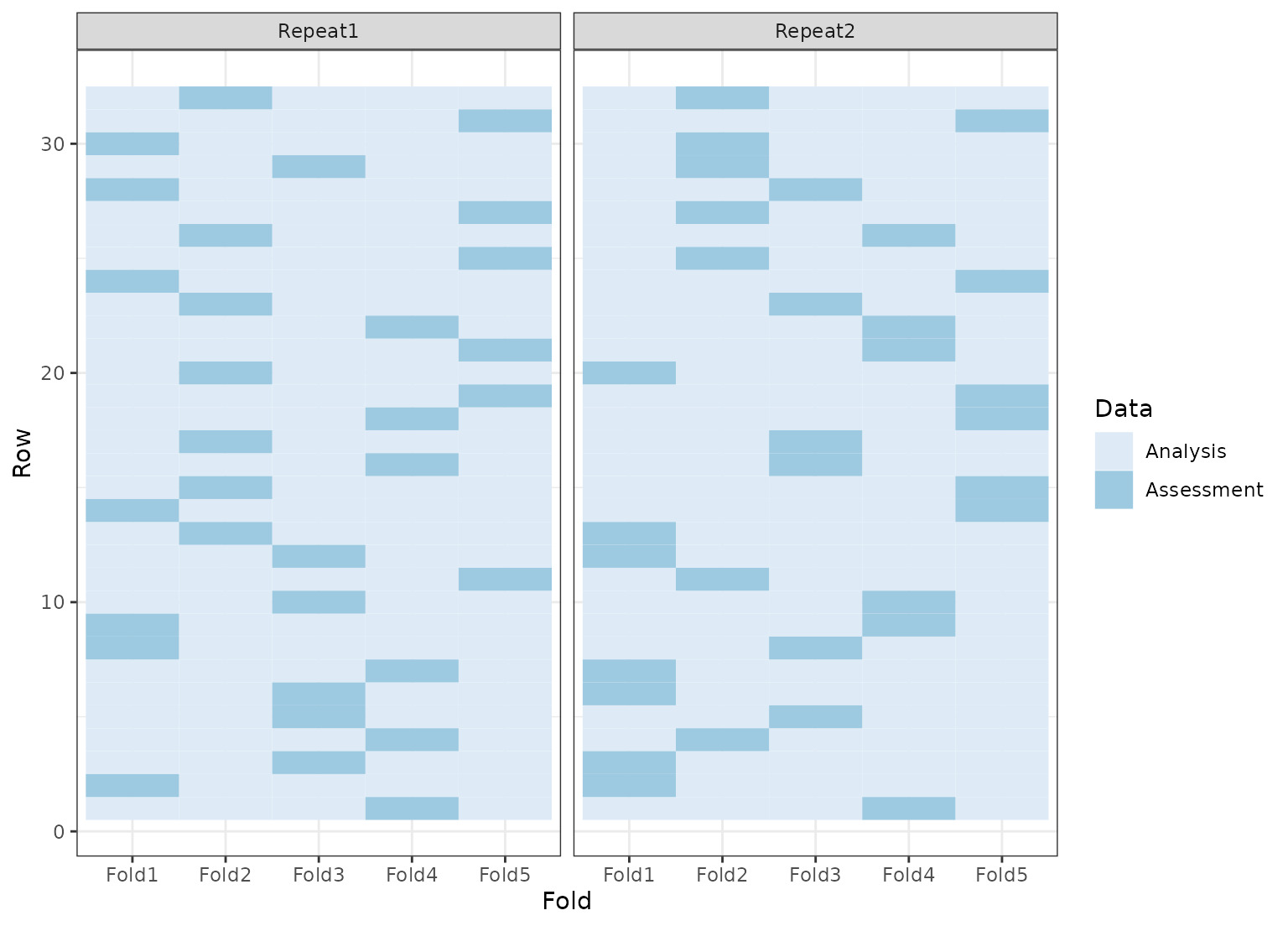
rcv <- tidy(vfold_cv(mtcars, v = 5, repeats = 2))
ggplot(rcv, aes(x = Fold, y = Row, fill = Data)) +
geom_tile() +
facet_wrap(~Repeat) +
scale_fill_brewer()
set.seed(4121)
rcv <- tidy(vfold_cv(mtcars, v = 5, repeats = 2))
ggplot(rcv, aes(x = Fold, y = Row, fill = Data)) +
geom_tile() +
facet_wrap(~Repeat) +
scale_fill_brewer()
 set.seed(4121)
mccv <- tidy(mc_cv(mtcars, times = 5))
ggplot(mccv, aes(x = Resample, y = Row, fill = Data)) +
geom_tile() +
scale_fill_brewer()
set.seed(4121)
mccv <- tidy(mc_cv(mtcars, times = 5))
ggplot(mccv, aes(x = Resample, y = Row, fill = Data)) +
geom_tile() +
scale_fill_brewer()
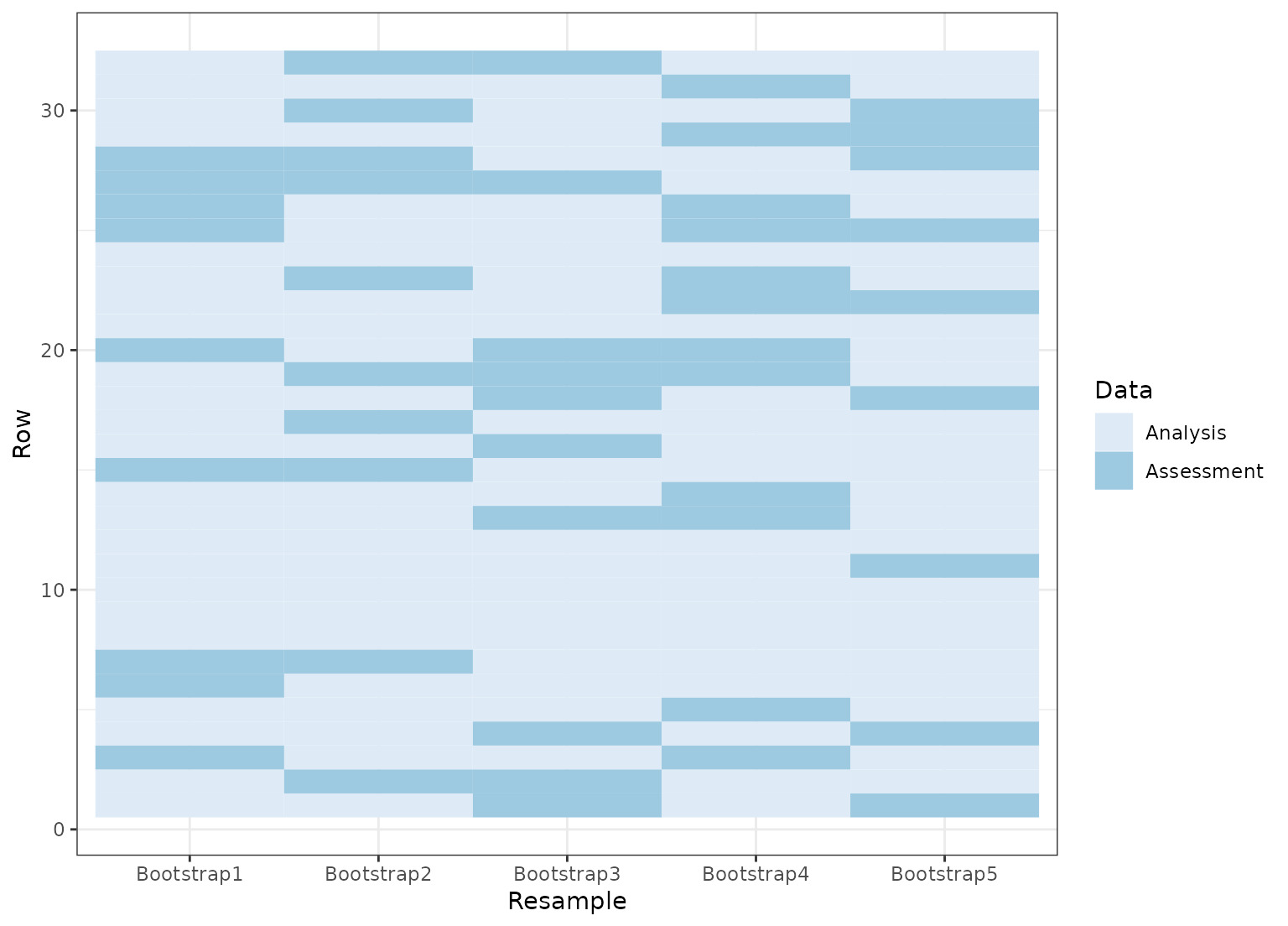
 set.seed(4121)
bt <- tidy(bootstraps(mtcars, time = 5))
ggplot(bt, aes(x = Resample, y = Row, fill = Data)) +
geom_tile() +
scale_fill_brewer()
set.seed(4121)
bt <- tidy(bootstraps(mtcars, time = 5))
ggplot(bt, aes(x = Resample, y = Row, fill = Data)) +
geom_tile() +
scale_fill_brewer()
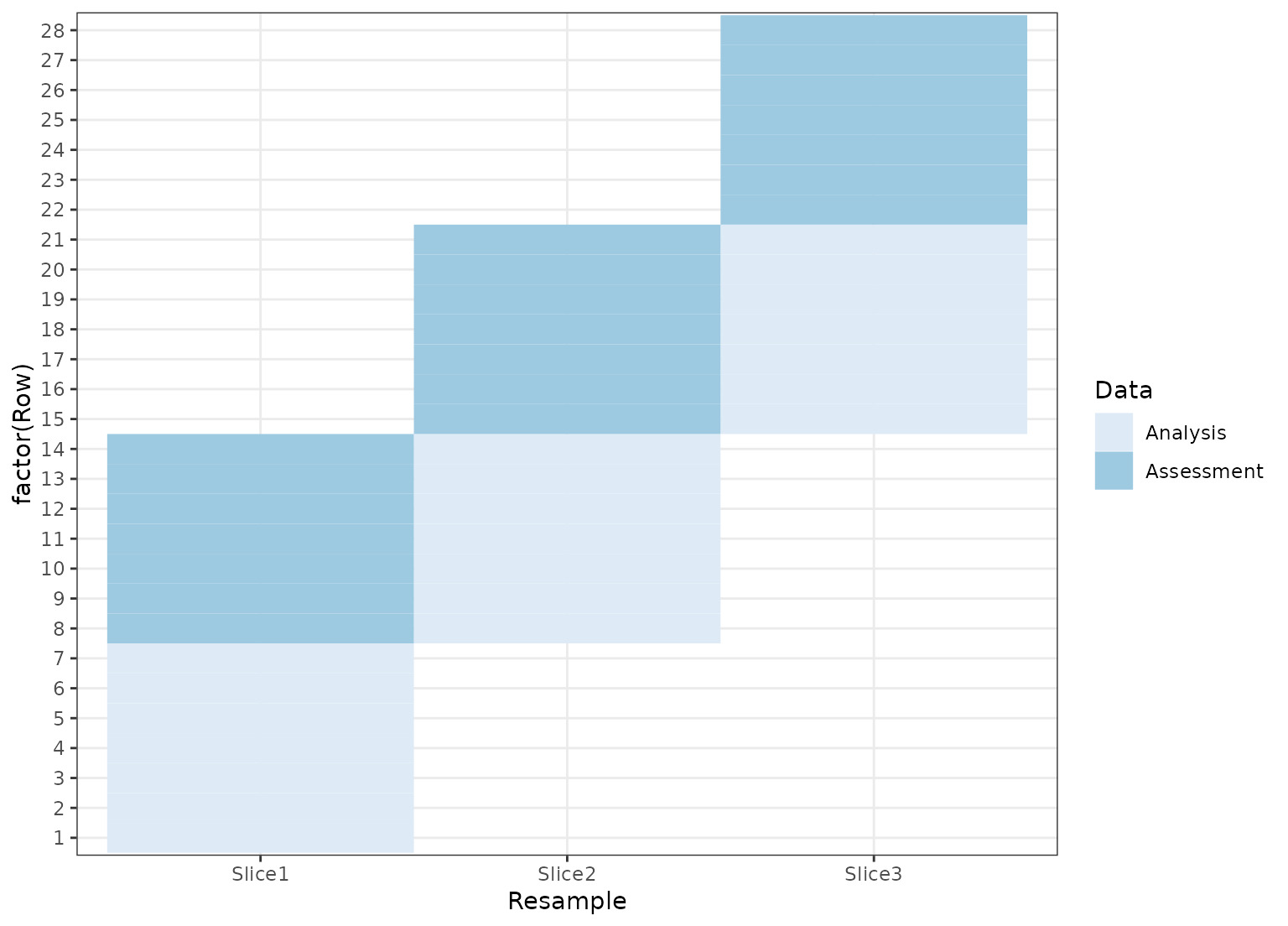
 dat <- data.frame(day = 1:30)
# Resample by week instead of day
ts_cv <- rolling_origin(dat,
initial = 7, assess = 7,
skip = 6, cumulative = FALSE
)
ts_cv <- tidy(ts_cv)
ggplot(ts_cv, aes(x = Resample, y = factor(Row), fill = Data)) +
geom_tile() +
scale_fill_brewer()
dat <- data.frame(day = 1:30)
# Resample by week instead of day
ts_cv <- rolling_origin(dat,
initial = 7, assess = 7,
skip = 6, cumulative = FALSE
)
ts_cv <- tidy(ts_cv)
ggplot(ts_cv, aes(x = Resample, y = factor(Row), fill = Data)) +
geom_tile() +
scale_fill_brewer()
相关用法
- R rsample validation_set 创建验证拆分以进行调整
- R rsample initial_split 简单的训练/测试集分割
- R rsample populate 添加评估指标
- R rsample int_pctl 自举置信区间
- R rsample vfold_cv V 折交叉验证
- R rsample rset_reconstruct 使用新的 rset 子类扩展 rsample
- R rsample group_mc_cv 小组蒙特卡罗交叉验证
- R rsample group_vfold_cv V 组交叉验证
- R rsample rolling_origin 滚动原点预测重采样
- R rsample reverse_splits 反转分析和评估集
- R rsample group_bootstraps 团体自举
- R rsample labels.rset 从 rset 对象中查找标签
- R rsample get_fingerprint 获取重采样的标识符
- R rsample bootstraps 引导抽样
- R rsample validation_split 创建验证集
- R rsample reg_intervals 具有线性参数模型的置信区间的便捷函数
- R rsample clustering_cv 集群交叉验证
- R rsample initial_validation_split 创建初始训练/验证/测试拆分
- R rsample get_rsplit 从 rset 中检索单个 rsplit 对象
- R rsample loo_cv 留一交叉验证
- R rsample complement 确定评估样本
- R rsample slide-resampling 基于时间的重采样
- R rsample as.data.frame.rsplit 将 rsplit 对象转换为 DataFrame
- R rsample labels.rsplit 从 rsplit 对象中查找标签
- R rsample mc_cv 蒙特卡罗交叉验证
注:本文由纯净天空筛选整理自Hannah Frick等大神的英文原创作品 Tidy Resampling Object。非经特殊声明,原始代码版权归原作者所有,本译文未经允许或授权,请勿转载或复制。