这篇文章是参考:https://github.com/ceys/jdml/wiki/ALS 改写的,由于原文Latex公式没有正常展现+少量笔误,妨碍阅读,所以这里重新整理了一下。
ALS是alternating least squares的缩写 , 意为交替最小二乘法;而ALS-WR是alternating-least-squares with weighted-λ -regularization的缩写,意为加权正则化交替最小二乘法。该方法常用于基于矩阵分解的推荐系统中。例如:将用户(user)对商品(item)的评分矩阵分解为两个矩阵:一个是用户对商品隐含特征的偏好矩阵,另一个是商品所包含的隐含特征的矩阵。在这个矩阵分解的过程中,评分缺失项得到了填充,也就是说我们可以基于这个填充的评分来给用户最商品推荐了。
ALS
由于评分数据中有大量的缺失项,传统的矩阵分解SVD(奇异值分解)不方便处理这个问题,而ALS能够很好的解决这个问题。对于R(m×n)的矩阵,ALS旨在找到两个低维矩阵X(m×k)和矩阵Y(n×k),来近似逼近R(m×n),即:
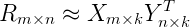 其中R(m×n)代表用户对商品的评分矩阵,X(m×k)代表用户对隐含特征的偏好矩阵,Y(n×k)表示商品所包含隐含特征的矩阵,T表示矩阵Y的转置。实际中,一般取k<<min(m, n), 也就是相当于降维了。这里的低维矩阵,有的地方也叫低秩矩阵。
其中R(m×n)代表用户对商品的评分矩阵,X(m×k)代表用户对隐含特征的偏好矩阵,Y(n×k)表示商品所包含隐含特征的矩阵,T表示矩阵Y的转置。实际中,一般取k<<min(m, n), 也就是相当于降维了。这里的低维矩阵,有的地方也叫低秩矩阵。
为了找到使低秩矩阵X和Y尽可能地逼近R,需要最小化下面的平方误差损失函数:
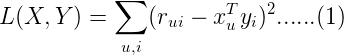 其中xu(1×k)表示示用户u的偏好的隐含特征向量,yi(1×k)表示商品i包含的隐含特征向量, rui表示用户u对商品i的评分, 向量xu和yi的内积xuTyi是用户u对商品i评分的近似。
其中xu(1×k)表示示用户u的偏好的隐含特征向量,yi(1×k)表示商品i包含的隐含特征向量, rui表示用户u对商品i的评分, 向量xu和yi的内积xuTyi是用户u对商品i评分的近似。
损失函数一般需要加入正则化项来避免过拟合等问题,我们使用L2正则化,所以上面的公式改造为:
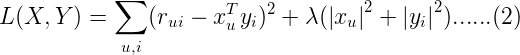 其中λ是正则化项的系数。
其中λ是正则化项的系数。
到这里,协同过滤就成功转化成了一个优化问题。由于变量xu和yi耦合到一起,这个问题并不好求解,所以我们引入了ALS,也就是说我们可以先固定Y(例如随机初始化X),然后利用公式(2)先求解X,然后固定X,再求解Y,如此交替往复直至收敛,即所谓的交替最小二乘法求解法。
具体求解方法说明如下:
- 先固定Y, 将损失函数L(X,Y)对xu求偏导,并令导数=0,得到:
![]()
- 同理固定X,可得:
![]() 其中ru(1×n)是R的第u行,ri(1×m)是R的第i列, I是k×k的单位矩阵。
其中ru(1×n)是R的第u行,ri(1×m)是R的第i列, I是k×k的单位矩阵。
- 迭代步骤:首先随机初始化Y,利用公式(3)更新得到X, 然后利用公式(4)更新Y, 直到均方根误差变RMSE化很小或者到达最大迭代次数。
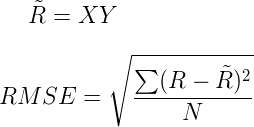
ALS-WR
上文提到的模型适用于解决有明确评分矩阵的应用场景,然而很多情况下,用户没有明确反馈对商品的偏好,也就是没有直接打分,我们只能通过用户的某些行为来推断他对商品的偏好。比如,在电视节目推荐的问题中,对电视节目收看的次数或者时长,这时我们可以推测次数越多,看得时间越长,用户的偏好程度越高,但是对于没有收看的节目,可能是由于用户不知道有该节目,或者没有途径获取该节目,我们不能确定的推测用户不喜欢该节目。ALS-WR通过置信度权重来解决这些问题:对于更确信用户偏好的项赋以较大的权重,对于没有反馈的项,赋以较小的权重。ALS-WR模型的形式化说明如下:
- ALS-WR的目标函数:
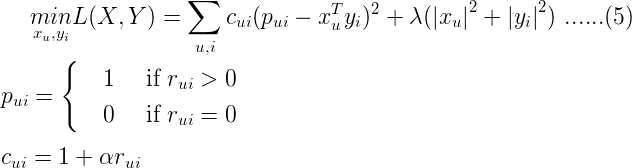 其中α是置信度系数。
其中α是置信度系数。
- 求解方式还是最小二乘法:
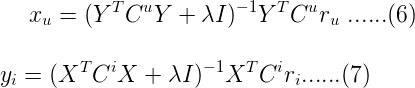 其中Cu是n×n的对角矩阵,Ci是m×m的对角矩阵;Cuii = cui, Ciii = cii。
其中Cu是n×n的对角矩阵,Ci是m×m的对角矩阵;Cuii = cui, Ciii = cii。
具体实现待补充。
本文参考:
[1] https://github.com/ceys/jdml/wiki/ALS
[2] http://mt.sohu.com/20150507/n412633357.shtml