
时间是每个涉及时间序列的机器学习问题中的黄金信息。作为数据科学家,我们必须尽最大努力提取时间模式。对于时间的预处理,常用的方法有:示例标准化(平稳性检查,自相关删除…),创建和编码类别时间特征(天,周,月,季节…),手动特征工程(傅立叶变换…)等。这些方法并非总是有效,因为在建模期间,我们选择的模型可能无法将时间本身正确地视为一项特征。
在这篇文章中,我尝试重现论文“Time2Vec:学习时间的向量表示’(‘Time2Vec: Learning a Vector Representation of Time’), 最终目的是为时间开发一个通用的表示形式,该表示形式可以在任何体系结构中潜在使用(我使用此解决方案在Keras中开发了神经网络)。作者不想提出一个用于时间序列分析的新模型,而是以向量嵌入的形式提供时间表示,以便自动进行特征工程过程并以更好的方式对时间建模。
数据集
为了验证整个解决方案的实用性,我们需要一个足够的数据集。这里我们需要纯粹的时间序列格式的数据,不需要任何冗余信息。这种情况在自回归问题中很常见,在该问题中,我们只有一个时间序列特征,我们将其用作预测未来的特征。在现实生活中,这是一项常见的任务,因此查找数据集并不困难。我们在Kaggle上发现了一个不错的数据集,它存储了威尼斯这个城市大量的历史水位信息。预测这些值是一项艰巨的任务——在这里,我们必须使用唯一的历史时序水位数据以提供对下一小时水位的预测。
TIME2VEC的实现
从数学上讲,实现Time2Vec非常容易:
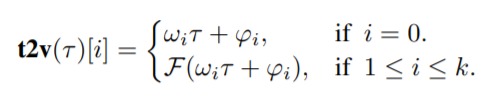
其中ķ是time2vec维度,τ是原始时间序列特征,F是周期性激活函数,ω和φ是一组可学习的参数。在实验中,为了使得算法能够捕获数据中的周期性行为,F选定为一个正弦函数。与此同时线性项(对应i=0)表示时间的进程,可用于捕获时间输入中的非周期性模式。
简单性使得该时间向量表示可以通过不同体系结构轻松使用。这里,我尝试通过简单修改Keras Dense层以便在神经网络结构中使用它。
class T2V(Layer):
def __init__(self, output_dim=None, **kwargs):
self.output_dim = output_dim
super(T2V, self).__init__(**kwargs)
def build(self, input_shape):
self.W = self.add_weight(name='W',
shape=(self.output_dim,
self.output_dim),
initializer='uniform',
trainable=True)
self.B = self.add_weight(name='B',
shape=(input_shape[1],
self.output_dim),
initializer='uniform',
trainable=True)
self.w = self.add_weight(name='w',
shape=(1, 1),
initializer='uniform',
trainable=True)
self.b = self.add_weight(name='b',
shape=(input_shape[1], 1),
initializer='uniform',
trainable=True)
super(T2V, self).build(input_shape)
def call(self, x):
original = self.w * x + self.b
x = K.repeat_elements(x, self.output_dim, -1)
sin_trans = K.sin(K.dot(x, self.W) + self.B)
return K.concatenate([sin_trans,original], -1)
def compute_output_shape(self, input_shape):
return (input_shape[0], input_shape[1], self.output_dim+1)这个用户自定义层的输出维度是用户指定的维度(1≤i≤k),即从网络学到的正弦波,加上输入的线性表示(i = 0)。有了这个组件,我们只需要将它与其他层堆叠在一起,然后在案例研究中尝试使用它的强大功能。
模型
Time2Vec是否可以很好地表示时间?为了回答这个问题,我建立了两种不同的序列神经网络模型,比较了在预测任务中获得的性能指标。第一个输入是我们的自定义Time2Vec层作为输入,该层堆叠在一个简单的LSTM层上。第二层仅由先前结构中使用的简单LSTM层组成。
def T2V_NN(dim, t2v_dim):
inp = Input(shape=(dim,1))
x = T2V(t2v_dim)(inp)
x = LSTM(32)(x)
x = Dense(1)(x)
m = Model(inp, x)
return m
def NN(dim):
inp = Input(shape=(dim,1))
x = LSTM(32)(inp)
x = Dense(1)(x)
m = Model(inp, x)
return m结果
我将数据的前70%用作训练集,将其余30%用作测试集。然后将模型训练了100轮(epochs),对于LSTM + T2V,MSE约为10.09,对于简单LSTM,MSE约为13.12。
为了提供性能差异的证据,我决定比较最终预测的分布:
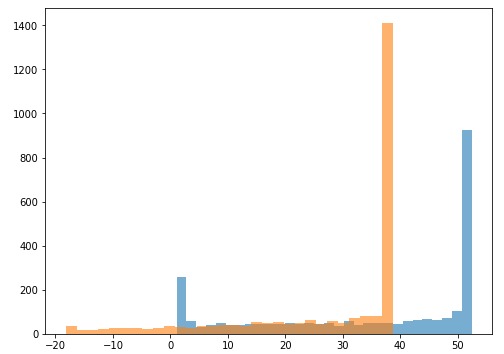
乍一看,分布之间有很多重叠。但是,我们无法看到两个样本之间在统计上是否存在显著差异。在这种情况下自举(bootstrapping )方法可以帮助我们弄清楚这个差异!
自举是一种随机重采样的直观技术,它允许估计几乎所有统计信息的采样分布。它的实现非常容易。在我们的情况下,我们必须从预测分布中提取重复的小样本,计算每个样本的均值,创建这些均值的新分布,然后再做比较:
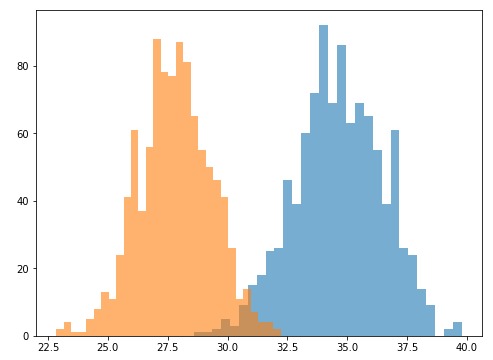
这两个新的重采样分布对我们来说很熟悉。它们是正太分布,因此比较起来更容易。为了方便比较,我将第一个分布的90分位数和第二个分布的10分位数进行比较,并检查是否存在重叠。我们可以看到29.77(来自没有T2V的LSTM)小于32.23(来自带有T2V的LSTM)。换句话说,我们可以得出90%的置信度,即预测分布之间存在统计差异,并且Time2Vec能够显著提高性能。
总结
在这篇文章中,我介绍了一种自动学习时间特征的方法。特别是我们重现了论文中的Time2Vec,一种时间的向量表示,并调整使其适用于神经网络架构。并且,我们能够在实际任务中展示这种时间表示的有效性。正如论文的作者所建议的,Time2Vec(T2V)并不是用于时间序列分析的新模型,而是一种简单的向量表示形式,可以轻松地将其导入许多现有和未来的模型体系结构中并改善其性能。
参考资料
Time2Vec:Learning a Vector Representation of Time(学习时间的向量表示)。 Seyed Mehran Kazemi,Rishab Goel,Sepehr Eghbali,Janahan Ramanan,Jaspreet Sahota,Sanjay Thakur,Stella Wu,Cathal Smyth,Pascal Poupart,Marcus Brubaker