在处理类别和连续因变量时,XGBoost表现很好。那么,使用XGBoost建模问题时,如何选择和优化参数呢?
这是最近我为Kaggle问题应用参数的方法:
param <- list( objective = "reg:linear",
booster = "gbtree",
eta = 0.02, # 0.06, #0.01,
max_depth = 10, #changed from default of 8
subsample = 0.5, # 0.7
colsample_bytree = 0.7, # 0.7
num_parallel_tree = 5
# alpha = 0.0001,
# lambda = 1
)
clf <- xgb.train( params = param,
data = dtrain,
nrounds = 3000, #300, #280, #125, #250, # changed from 300
verbose = 0,
early.stop.round = 100,
watchlist = watchlist,
maximize = FALSE,
feval=RMPSE
)
我所做的所有实验都是随机选择(直觉)另一组参数来改善结果。
那么,是否能自动选择优化(最佳)参数集呢?
解决办法
每当我使用xgboost时,我经常进行自己的自定义的参数搜索,当然,也可以使用Caret包或其他类似的插件方法来解决这个问题。
-
Caret
有关如何在xgboost上使用Caret包进行超参数搜索的详细说明,请参阅Cross Validated上的这个答案。 How to tune hyperparameters of xgboost trees?
-
自定义网格搜索
我经常根据Owen Zhang在tips for data science P.14上的幻灯片做一些启动设定。

在这里你可以看到,你最需要调整行采样,列采样和最大树深度。这就是我如何进行自定义行采样和列采样搜索我正在处理的问题:
searchGridSubCol <- expand.grid(subsample = c(0.5, 0.75, 1),
colsample_bytree = c(0.6, 0.8, 1))
ntrees <- 100
#Build a xgb.DMatrix object
DMMatrixTrain <- xgb.DMatrix(data = yourMatrix, label = yourTarget)
rmseErrorsHyperparameters <- apply(searchGridSubCol, 1, function(parameterList){
#Extract Parameters to test
currentSubsampleRate <- parameterList[["subsample"]]
currentColsampleRate <- parameterList[["colsample_bytree"]]
xgboostModelCV <- xgb.cv(data = DMMatrixTrain, nrounds = ntrees, nfold = 5, showsd = TRUE,
metrics = "rmse", verbose = TRUE, "eval_metric" = "rmse",
"objective" = "reg:linear", "max.depth" = 15, "eta" = 2/ntrees,
"subsample" = currentSubsampleRate, "colsample_bytree" = currentColsampleRate)
xvalidationScores <- as.data.frame(xgboostModelCV)
#Save rmse of the last iteration
rmse <- tail(xvalidationScores$test.rmse.mean, 1)
return(c(rmse, currentSubsampleRate, currentColsampleRate))
})
结合使用应用函数结果的一些ggplot2方法,您可以绘制搜索的图形表示。
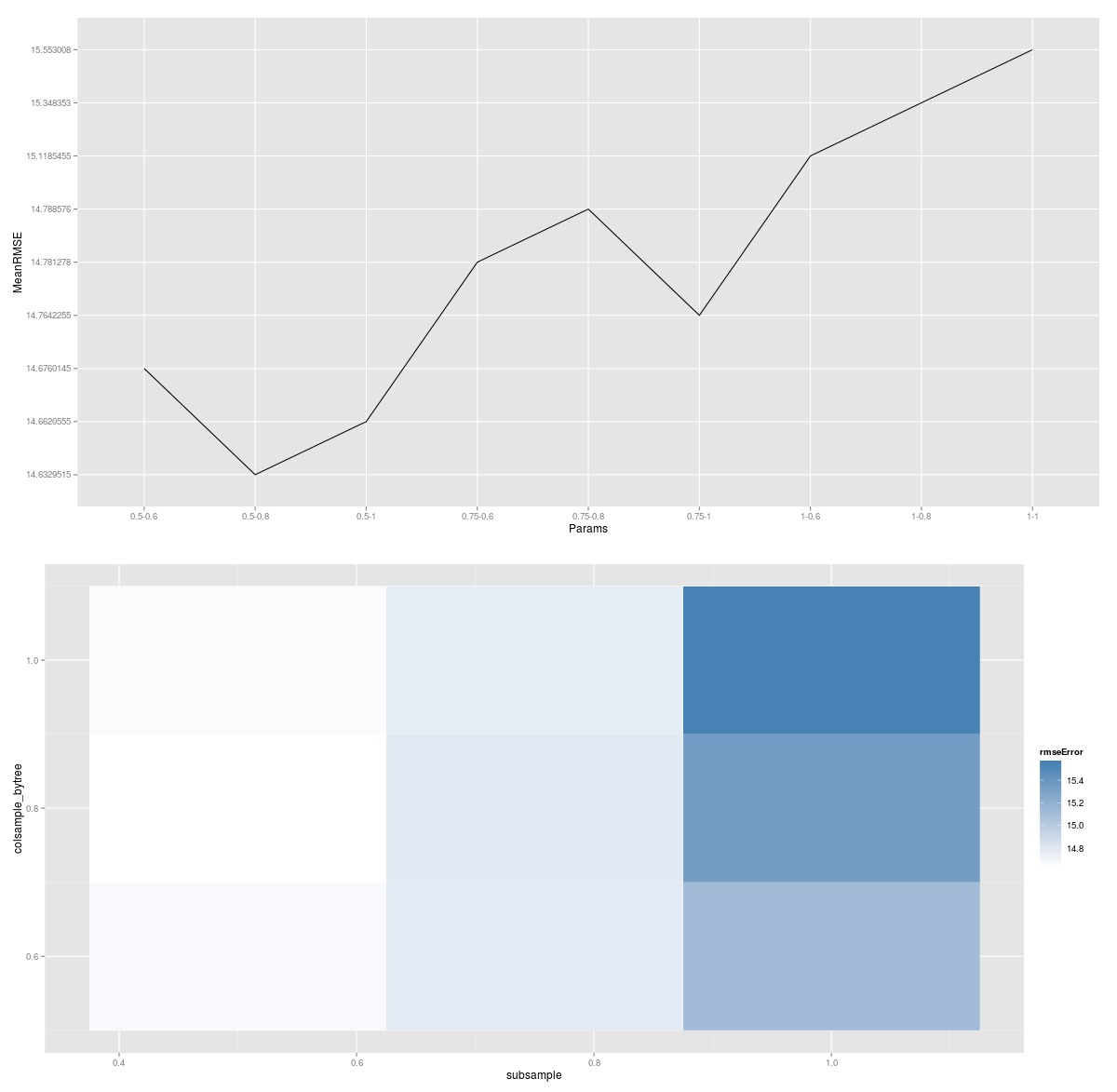
在该图中,较浅的颜色表示较低的误差,并且每个块表示列采样和行采样的独特组合。因此,如果您想对eta(或树深度)进行额外搜索,您将最终得到测试的每个eta参数的绘图。
对于一个不同的评估指标(RMPSE),只需在交叉验证功能中插入它,就会得到所需的结果。除此之外,不用过分担心微调其他参数,因为这样做不会太多地改善性能。至少与花费更多时间做特征工程或清理数据相比,收益没那么大。
-
其他
随机搜索和贝叶斯参数选择也是可能的,但我还没有制作/找到它们的实现。
以下是Max Kuhn(Caret创建者)对贝叶斯优化超参数的一个很好的入门。
http://blog.revolutionanalytics.com/2016/06/bayesian-optimization-of-machine-learning-models.html