在處理類別和連續因變量時,XGBoost表現很好。那麽,使用XGBoost建模問題時,如何選擇和優化參數呢?
這是最近我為Kaggle問題應用參數的方法:
param <- list( objective = "reg:linear",
booster = "gbtree",
eta = 0.02, # 0.06, #0.01,
max_depth = 10, #changed from default of 8
subsample = 0.5, # 0.7
colsample_bytree = 0.7, # 0.7
num_parallel_tree = 5
# alpha = 0.0001,
# lambda = 1
)
clf <- xgb.train( params = param,
data = dtrain,
nrounds = 3000, #300, #280, #125, #250, # changed from 300
verbose = 0,
early.stop.round = 100,
watchlist = watchlist,
maximize = FALSE,
feval=RMPSE
)
我所做的所有實驗都是隨機選擇(直覺)另一組參數來改善結果。
那麽,是否能自動選擇優化(最佳)參數集呢?
解決辦法
每當我使用xgboost時,我經常進行自己的自定義的參數搜索,當然,也可以使用Caret包或其他類似的插件方法來解決這個問題。
-
Caret
有關如何在xgboost上使用Caret包進行超參數搜索的詳細說明,請參閱Cross Validated上的這個答案。 How to tune hyperparameters of xgboost trees?
-
自定義網格搜索
我經常根據Owen Zhang在tips for data science P.14上的幻燈片做一些啟動設定。

在這裏你可以看到,你最需要調整行采樣,列采樣和最大樹深度。這就是我如何進行自定義行采樣和列采樣搜索我正在處理的問題:
searchGridSubCol <- expand.grid(subsample = c(0.5, 0.75, 1),
colsample_bytree = c(0.6, 0.8, 1))
ntrees <- 100
#Build a xgb.DMatrix object
DMMatrixTrain <- xgb.DMatrix(data = yourMatrix, label = yourTarget)
rmseErrorsHyperparameters <- apply(searchGridSubCol, 1, function(parameterList){
#Extract Parameters to test
currentSubsampleRate <- parameterList[["subsample"]]
currentColsampleRate <- parameterList[["colsample_bytree"]]
xgboostModelCV <- xgb.cv(data = DMMatrixTrain, nrounds = ntrees, nfold = 5, showsd = TRUE,
metrics = "rmse", verbose = TRUE, "eval_metric" = "rmse",
"objective" = "reg:linear", "max.depth" = 15, "eta" = 2/ntrees,
"subsample" = currentSubsampleRate, "colsample_bytree" = currentColsampleRate)
xvalidationScores <- as.data.frame(xgboostModelCV)
#Save rmse of the last iteration
rmse <- tail(xvalidationScores$test.rmse.mean, 1)
return(c(rmse, currentSubsampleRate, currentColsampleRate))
})
結合使用應用函數結果的一些ggplot2方法,您可以繪製搜索的圖形表示。
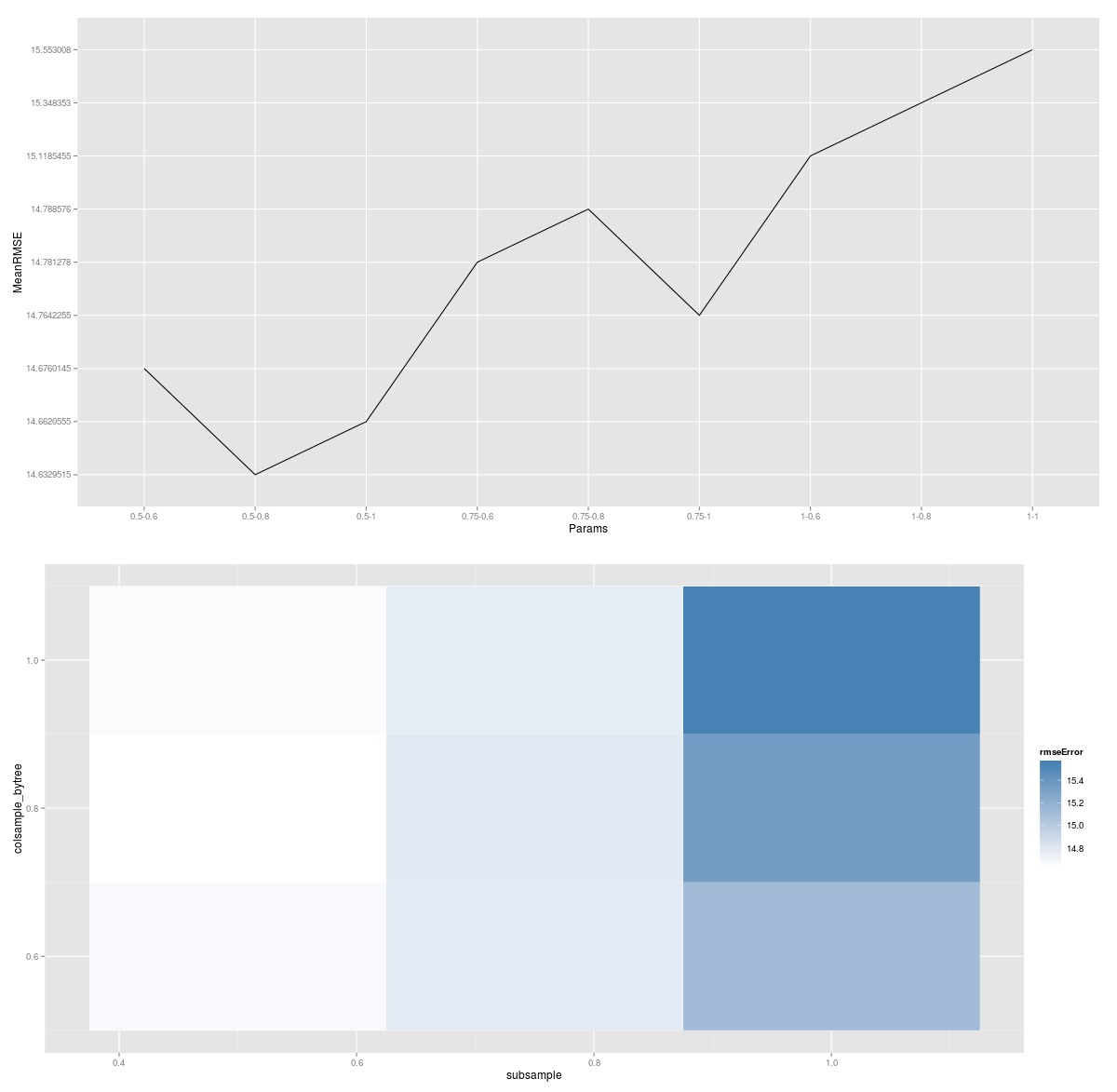
在該圖中,較淺的顏色表示較低的誤差,並且每個塊表示列采樣和行采樣的獨特組合。因此,如果您想對eta(或樹深度)進行額外搜索,您將最終得到測試的每個eta參數的繪圖。
對於一個不同的評估指標(RMPSE),隻需在交叉驗證功能中插入它,就會得到所需的結果。除此之外,不用過分擔心微調其他參數,因為這樣做不會太多地改善性能。至少與花費更多時間做特征工程或清理數據相比,收益沒那麽大。
-
其他
隨機搜索和貝葉斯參數選擇也是可能的,但我還沒有製作/找到它們的實現。
以下是Max Kuhn(Caret創建者)對貝葉斯優化超參數的一個很好的入門。
http://blog.revolutionanalytics.com/2016/06/bayesian-optimization-of-machine-learning-models.html