XGB調參,實戰經驗總結!
XGBoost(或eXtreme Gradient Boosting)很強大,它在太多的數據科學競賽中被證明是有用的。

調參是一個需要經驗的活,如果蠻幹的話事倍功半:譬如要處理大型數據集,要對5個不同的參數進行了樸素的網格搜索,並且每個參數都有5個可能的值,那麽您將有5的5次方= 3,125次迭代。如果一次迭代要花10分鍾才能運行,那麽在獲取到靠譜參數之前,您將有21天以上的等待時間。
注:在這裏假設您首先正確完成了特征工程。特別是對於類別特征,因為XGBoost不擅長處理類別特征。
1. Train-test訓練集和測試集拆分,評估指標和提前停止[early-stoping]
在進行參數優化之前,首先要花一些時間來設計模型的診斷框架。
XGBoost Python api提供了一種通過增加樹的個數來評估增加的性能的方法。它使用兩個參數:“eval_set”(通常是訓練集和測試集)以及關聯的“eval_metric”來衡量這些評估集上的誤差。
訓練集合測試集誤差,繪製結果出來一般如下圖所示:
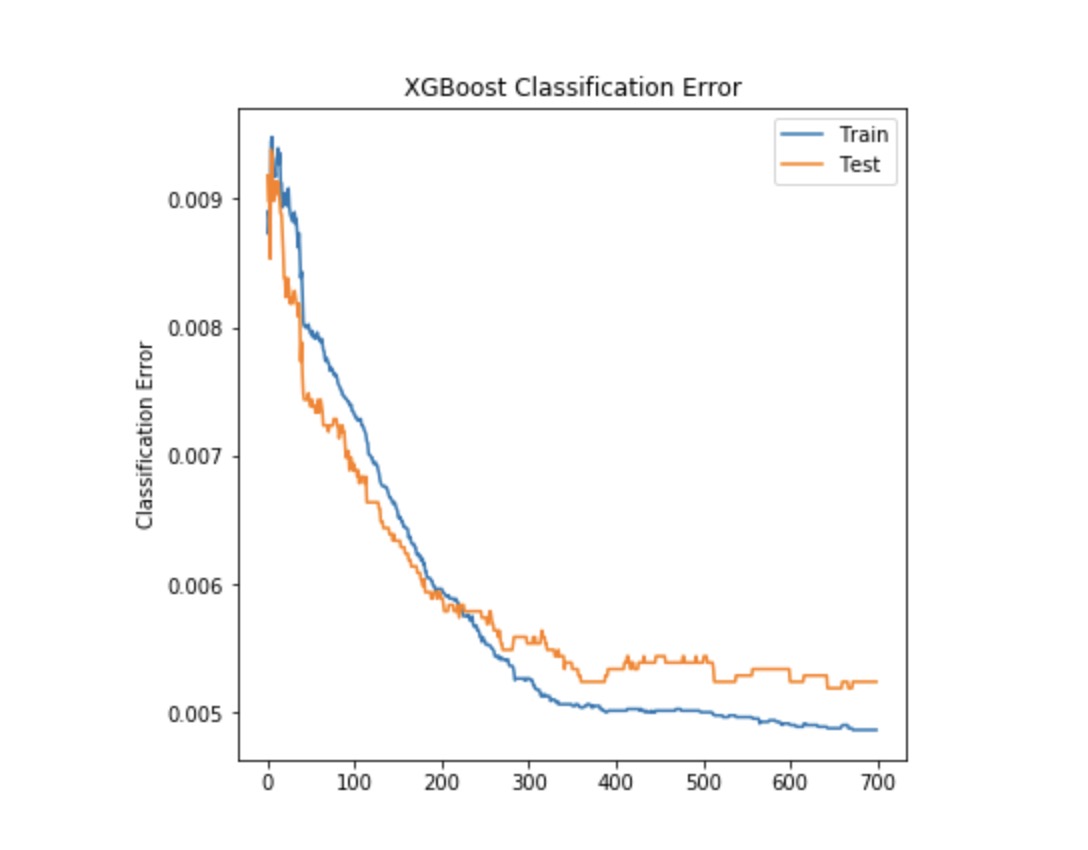
在上圖所示的分類誤差圖上:我們的模型持續學習直到350次迭代,然後誤差非常緩慢地減小。也就是說,可以考慮砍掉350之後的樹,節省以後的參數調整時間。
如果您不使用scikit-learn API,而是使用純XGBoost Python API,那麽提前停止參數,可幫助您自動減少樹的數量。
2.具體如何調參?
當還沒有運行任何模型時從哪裏開始?
- 為關鍵輸入填寫合理的值:
learning_rate:0.01
n_estimators:如果數據量很大,則為100,如果為中等規模,則為1000
max_depth:3
subsample:0.8
colsample_bytree:1
gamma:1 - 運行model.fit(eval_set,eval_metric)並診斷您的首次運行,特別是n_estimators
- 優化max_depth參數。它表示每棵樹的深度,這也是每棵樹中使用的不同特征的最大數量。我建議從小的max_depth開始(例如3),然後將其遞增1,並在沒有性能提高的情況下停止。這將有助於簡化模型並避免過度擬合
- 現在嘗試學習率和避免過擬合的功能:
learning_rate:通常在0.1到0.01之間。如果您專注於性能並且有很多時間在前麵,那麽在增加樹數量的同時逐步降低學習率。
subsample: 這是樹構建樹所占的行數[樣本量]的百分比。我建議不要丟掉太多行[樣本],因為性能會下降很多。通常取0.8到1。
colsample_bytree:每棵樹使用的列數[特征數]。如果您有很多列(尤其是您進行了one-hot編碼),則值為0.3到0.8;如果隻有幾列,則值為0.8到1。
gamma:通常被誤解的參數,它充當正則化參數。 可以取0、1或5。
把上麵這些主要參數調好,模型效果通常就很不錯了!
3.其他說明
為了讓模型效果及性能[運行速度]更好,除了上麵比較常規的調參之外,根據特征重要性做特征選擇也很重要!
xgboost提供了特征重要性統計函數:plot_importance(),其用法如下:
# plot feature importance using built-in function
from numpy import loadtxt
from xgboost import XGBClassifier
from xgboost import plot_importance
from matplotlib import pyplot
# load data
dataset = loadtxt('data.csv', delimiter=",")
# split data into X and y
X = dataset[:,0:8]
y = dataset[:,8]
# fit model no training data
model = XGBClassifier()
model.fit(X, y)
# plot feature importance
plot_importance(model)
pyplot.show()
運行得到的特征重要性圖像如下:
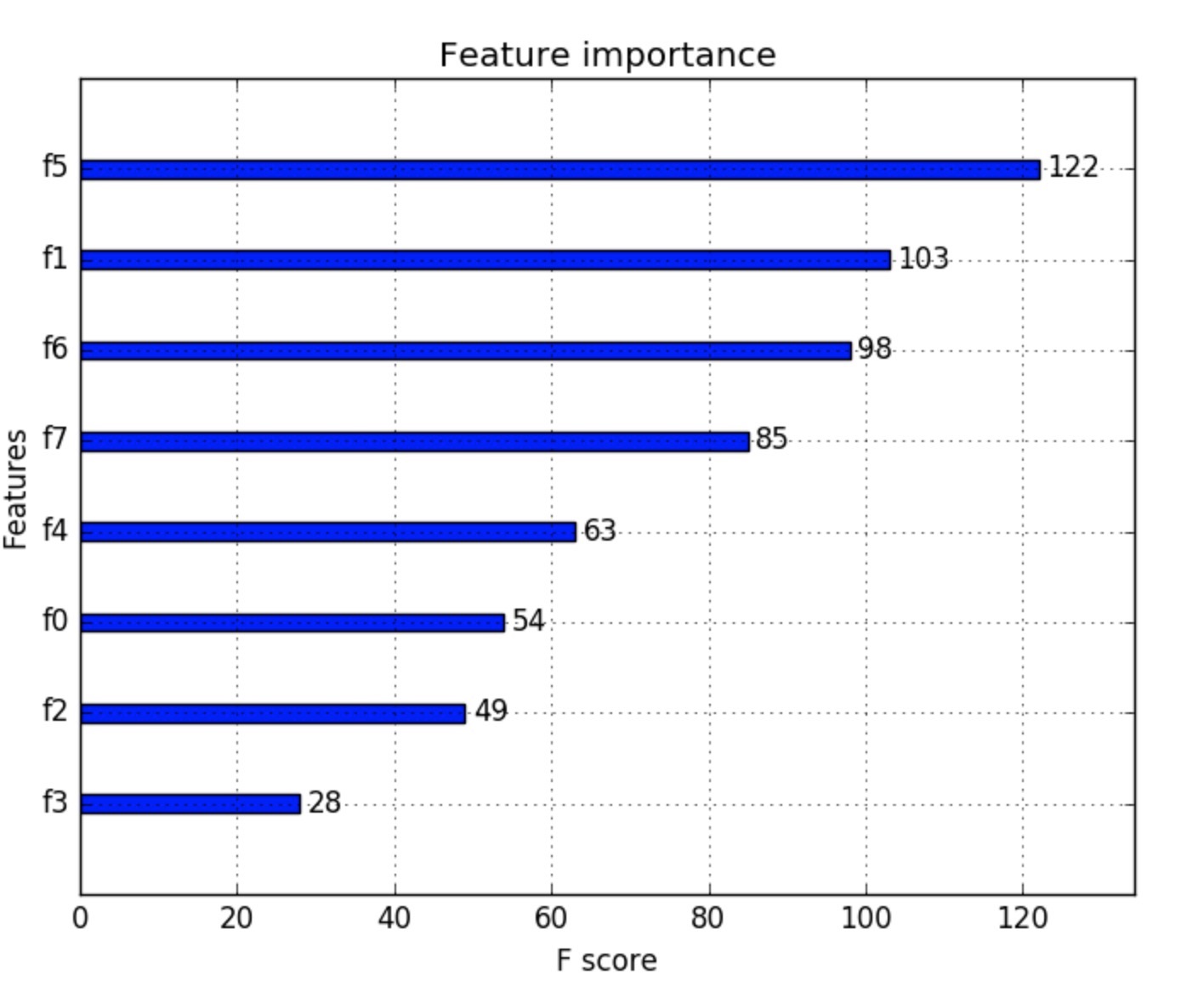
注:根據其在輸入數組中的索引,plot_importance自動將特征被命名為f0-f7。可以自行對應到具體的特征名。