假设我们有一个数据集,如下:
import numpy as np
x = np.linspace(0,2*np.pi,100)
y = np.sin(x) + np.random.random(100) * 0.2
因此,我们的数据集有20%的变化。我的第一个想法是使用scipy的UnivariateSpline函数,但问题是这并没有考虑到小噪声的好处。如果考虑频率,背景比信号小得多,所以只有截断的样条可能是一个想法,但是这涉及到来回傅里叶变换,这可能导致不良行为。另一种方式是移动平均线,但这也需要正确的延迟选择。
有任何提示/书籍或链接关于如何解决这个问题的吗?
最佳解决方法
我更喜欢Savitzky-Golay filter。它使用最小二乘法将数据的一个小窗口回归到多项式上,然后使用多项式来估计窗口中心的点。最后窗口向前移动一个数据点,重复这个过程。这样继续下去,直到每个点相对于邻居都进行了最佳调整。即使来自non-periodic(非周期)和non-linear(非线性)来源的噪音样本也很好。
这是一个例子:thorough cookbook example。看看我的代码,以了解它是多么容易使用。注:我没有定义savitzky_golay()函数的代码,因为你可以从上面链接的手册例子中复制/粘贴它。
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0,2*np.pi,100)
y = np.sin(x) + np.random.random(100) * 0.2
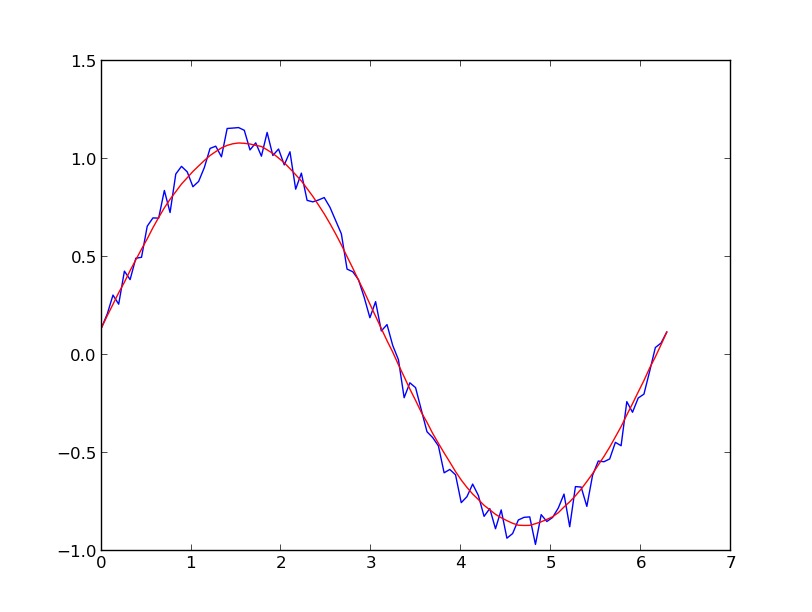
yhat = savitzky_golay(y, 51, 3) # window size 51, polynomial order 3
plt.plot(x,y)
plt.plot(x,yhat, color='red')
plt.show()
更新:我注意到,我所链接的例子已被删除。幸运的是,@dodohjk指出,Savitzky-Golay过滤器已经包含在into the SciPy library中。
次佳解决方法
如果你要”smooth”版本的信号是周期性的(例如你的例子),那么FFT是正确的选择。进行傅里叶变换,然后减去low-contributing频率:
import numpy as np
import scipy.fftpack
N = 100
x = np.linspace(0,2*np.pi,N)
y = np.sin(x) + np.random.random(N) * 0.2
w = scipy.fftpack.rfft(y)
f = scipy.fftpack.rfftfreq(N, x[1]-x[0])
spectrum = w**2
cutoff_idx = spectrum < (spectrum.max()/5)
w2 = w.copy()
w2[cutoff_idx] = 0
y2 = scipy.fftpack.irfft(w2)
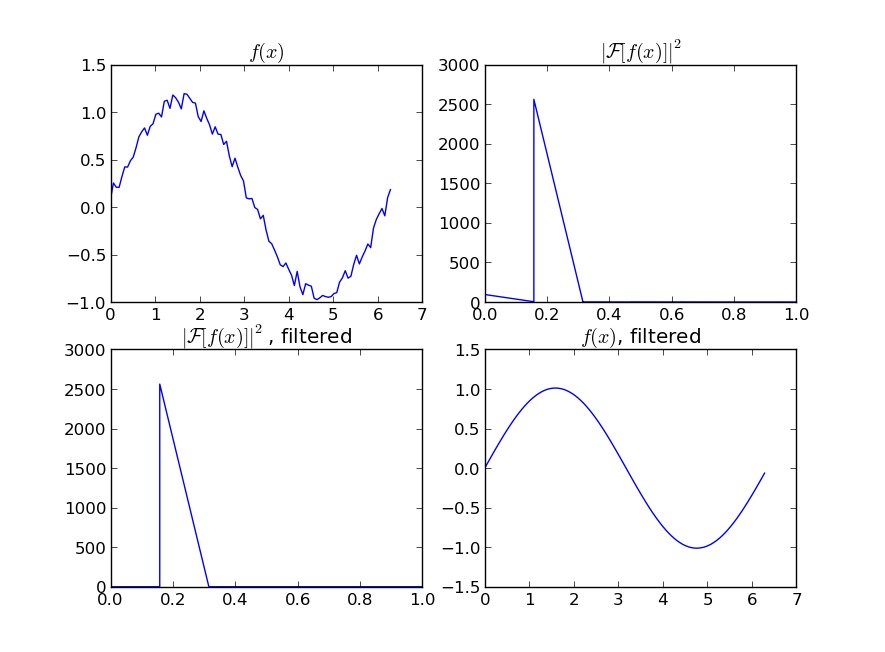
即使你的信号不完全是周期性的,这也能很好的减少白噪声。有许多类型的过滤器可以使用(high-pass,low-pass等),适当的那个取决于你在找什么。
第三种解决方法
一个快速和粗暴的方式来平滑我使用的数据,基于移动平均框(通过卷积):
x = np.linspace(0,2*np.pi,100)
y = np.sin(x) + np.random.random(100) * 0.8
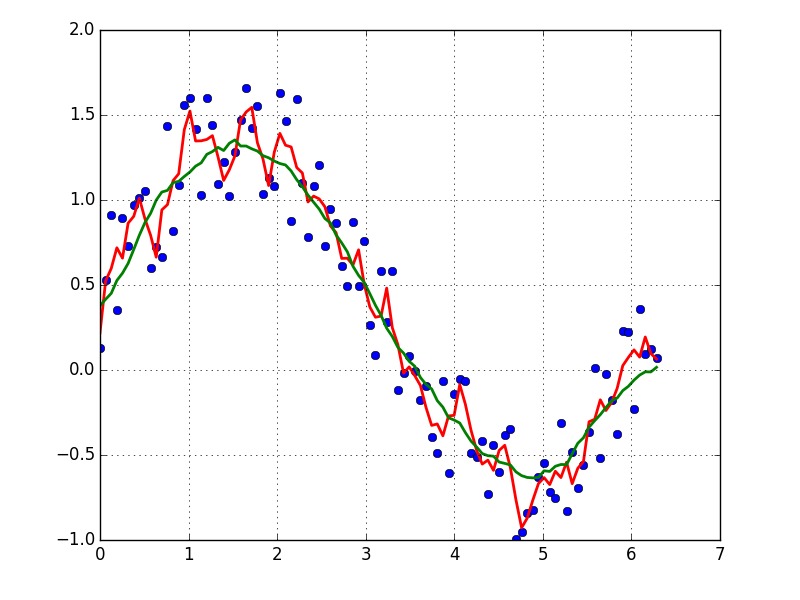
def smooth(y, box_pts):
box = np.ones(box_pts)/box_pts
y_smooth = np.convolve(y, box, mode='same')
return y_smooth
plot(x, y,'o')
plot(x, smooth(y,3), 'r-', lw=2)
plot(x, smooth(y,19), 'g-', lw=2)
第四种方法
将移动平均值拟合到您的数据将消除噪音,请参阅this answer了解如何操作。
如果您想要使用LOWESS来拟合您的数据(它类似于移动平均数,但更复杂),您可以使用statsmodels库来实现:
import numpy as np
import pylab as plt
import statsmodels.api as sm
x = np.linspace(0,2*np.pi,100)
y = np.sin(x) + np.random.random(100) * 0.2
lowess = sm.nonparametric.lowess(y, x, frac=0.1)
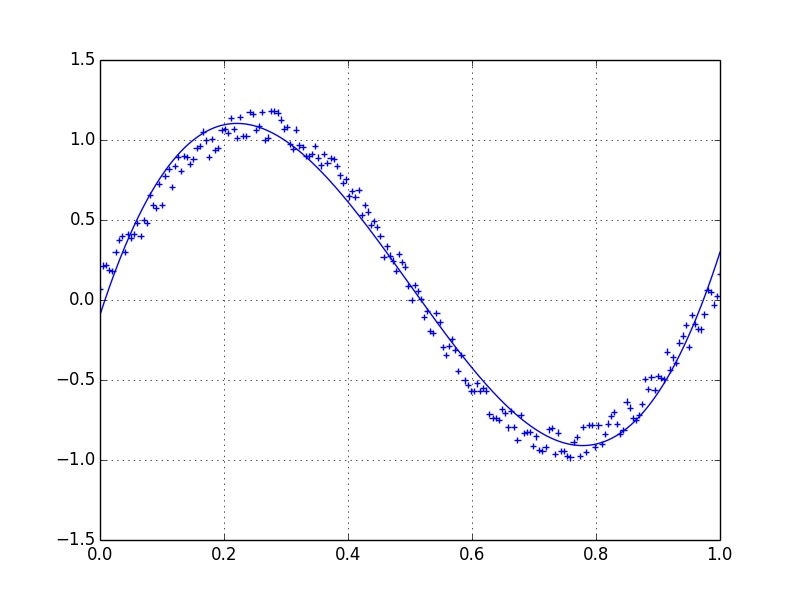
plt.plot(x, y, '+')
plt.plot(lowess[:, 0], lowess[:, 1])
plt.show()
最后,如果您知道信号的功能形式,则可以为数据拟合曲线,这可能是最好的选择。
第五种方法
另一种选择是在statsmodel中使用KernelReg:
from statsmodels.nonparametric.kernel_regression import KernelReg
import numpy as np
import matplotlib.pyplot as plt
x = np.linspace(0,2*np.pi,100)
y = np.sin(x) + np.random.random(100) * 0.2
# The third parameter specifies the type of the variable x;
# 'c' stands for continuous
kr = KernelReg(y,x,'c')
plt.plot(x, y, '+')
y_pred, y_std = kr.fit(x)
plt.plot(x, y_pred)
plt.show()