问题描述
最近观察网站(Powered By WordPress)后台日志发现,Googlebot大量请求/wp-login.php?redirect_to=xxx(xxx表示某个文章页的URL)这一类页面。这些请求最后都直接返回/wp-login.php登陆页面的简短内容,无论请求多少次,返回的内容都大同小异。这个情况,一方面对搜索引擎非常不友好,大量URL对应的内容一致;另外一方面,这种对网站搜索排名没有意义的请求,却浪费了较多的带宽资源。问题截图如下:

可能看不太清楚,这里再贴几条日志:
"GET /wp-login.php?redirect_to=https%3A%2F%2Fvimsky.com%2Farticle%2F8140.html HTTP/1.1" 200 4689 "vimsky.com" "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" "-"
"GET /wp-login.php?redirect_to=https%3A%2F%2Fvimsky.com%2Farticle%2F8145.html HTTP/1.1" 200 4689 "vimsky.com" "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" "-"
"GET /wp-login.php?redirect_to=https%3A%2F%2Fvimsky.com%2Farticle%2F8144.html HTTP/1.1" 200 4688 "vimsky.com" "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" "-"
"GET /wp-login.php?redirect_to=https%3A%2F%2Fvimsky.com%2Farticle%2F8142.html HTTP/1.1" 200 9775 "vimsky.com" "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" "-"
"GET /wp-login.php?redirect_to=https%3A%2F%2Fvimsky.com%2Farticle%2F8136.html HTTP/1.1" 200 6666 "vimsky.com" "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" "-"
"GET /wp-login.php?redirect_to=https%3A%2F%2Fvimsky.com%2Farticle%2F8143.html HTTP/1.1" 200 9781 "vimsky.com" "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" "-"
"GET /wp-login.php?redirect_to=https%3A%2F%2Fvimsky.com%2Farticle%2F8129.html HTTP/1.1" 200 4687 "vimsky.com" "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" "-"
"GET /wp-login.php?redirect_to=https%3A%2F%2Fvimsky.com%2Farticle%2F8135.html HTTP/1.1" 200 4687 "vimsky.com" "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" "-"
"GET /wp-login.php?redirect_to=https%3A%2F%2Fvimsky.com%2Farticle%2F8133.html HTTP/1.1" 200 6008 "vimsky.com" "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" "-"
"GET /wp-login.php?redirect_to=https%3A%2F%2Fvimsky.com%2Farticle%2F8128.html HTTP/1.1" 200 6766 "vimsky.com" "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" "-"
解决方案
刚看到这个问题的时候,还以为是有人在攻击本站,想要暴力破解login账号。但仔细分析之后,从请求的IP池、使用GET而非POST协议、以及访问频率等来看:这些应该是Googlebot的正常请求,问题可能出在vimsky站点本身页面上带有这种链接。基于这个思路,经过一番查找,发现问题症结如下图所示:
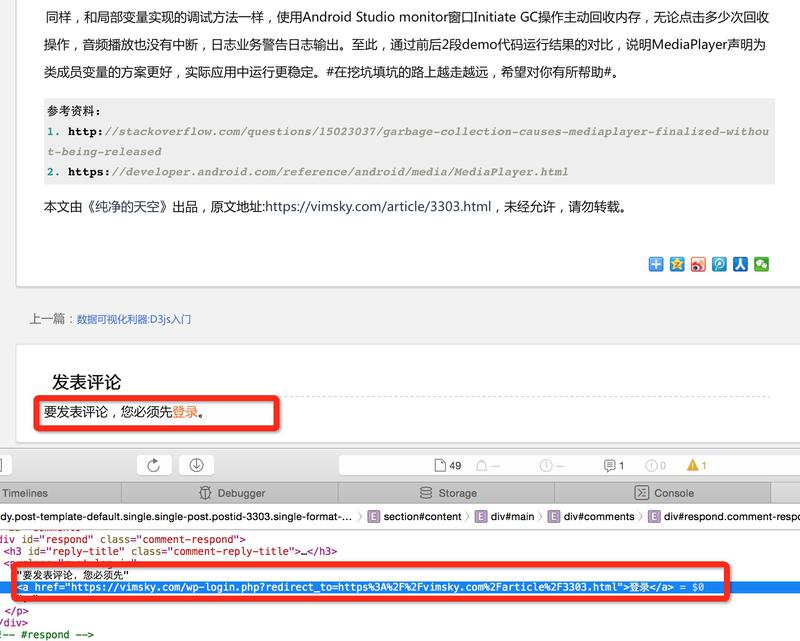
本站设置了登陆才能发表评论,所以这个地方有一个向登陆页的重定向,所以Googlebot能发现这个链接并尝试下载。那么接下来的问题是,如何禁止Googlebot或者Baiduspider这样的爬虫抓取这样的网页呢?
通常来说一般有两个方法:
一、给链接加上 rel="nofollow"属性。
在链接上加上nofollow这个属性,是告诉搜索引擎不要跟踪这个链接。Wordpress的“登陆之后才能评论”对应的链接,位于文件wp-includes/comment-template.php大约2220行,修改之后如下:
2217 /** This filter is documented in wp-includes/link-template.php */
2218 'must_log_in' => '< p class="must-log-in" >' . sprintf(
2219 /* translators: %s: login URL */
2220 str_replace("\">", "\" rel=\"nofollow\">", __( 'You must be logged in to post a comment.' )),
2221 wp_login_url( apply_filters( 'the_permalink', get_permalink( $post_id ) ) )
2222 ) . '< /p>',
2223 /** This filter is documented in wp-includes/link-template.php */
考虑到不影响Wordpress原始代码中的汉化(涉及./wp-content/languages/zh_CN.po文件),这里简单的对字符串做了str_replace替换,替换之后加上了rel="nofollow"属性。
二、在网站的robots.txt文件中设置禁止访问wp-login相关URL
在robots.txt加上禁止访问wp-login相关的URL
User-agent: *
Disallow: /wp-admin
Disallow: /comments/feed
Disallow: /wp-login
最好二种方法都用上,更彻底地避免爬虫对wp-login.php相关URL的请求。