tune_race_anova() 為一組預定義的調整參數計算一組性能指標(例如,準確性或 RMSE),這些參數對應於一次或多次數據重采樣的模型或配方。在評估初始數量的重采樣後,該過程消除了使用重複測量方差分析模型不太可能獲得最佳結果的調整參數組合。
用法
tune_race_anova(object, ...)
# S3 method for model_spec
tune_race_anova(
object,
preprocessor,
resamples,
...,
param_info = NULL,
grid = 10,
metrics = NULL,
control = control_race()
)
# S3 method for workflow
tune_race_anova(
object,
resamples,
...,
param_info = NULL,
grid = 10,
metrics = NULL,
control = control_race()
)參數
- object
-
parsnip模型規範或workflows::workflow()。 - ...
-
目前未使用。
- preprocessor
-
使用
recipes::recipe()創建的傳統模型公式或配方。僅當object不是工作流程時才需要這樣做。 - resamples
-
具有多次重采樣的
rset()對象(即不是驗證集)。 - param_info
-
dials::parameters()對象或NULL。如果沒有給出,則從其他參數派生參數集。當需要自定義參數範圍時,傳遞此參數可能很有用。 - grid
-
調諧組合或正整數的 DataFrame 。 DataFrame 應具有用於調整每個參數的列和用於調整候選參數的行。整數表示要自動創建的候選參數集的數量。
- metrics
-
一個
yardstick::metric_set()或NULL。 - control
-
用於修改調整過程的對象。有關更多詳細信息,請參閱
control_race()。
值
具有主類 tune_race 的對象,其標準格式與 tune::tune_grid() 生成的對象相同。
細節
Kuhn (2014) 說明了該方法的技術細節。
競賽方法是網格搜索的有效方法。最初,該函數評估一小組初始重采樣的所有調整參數。 control_race() 的 burn_in 參數設置初始重新采樣的數量。
對這些重新采樣的性能統計數據進行分析,以確定哪些調整參數在統計上與當前最佳設置沒有差異。如果參數在統計上不同,則將其排除在進一步重采樣之外。
下一次重新采樣將與剩餘的參數組合一起使用,並更新統計分析。處理每個新的重采樣時可以排除更多候選參數。
該函數使用重複測量方差分析模型確定統計顯著性,其中性能統計數據(例如 RMSE、準確性等)是結果數據,隨機效應是由於重新采樣造成的。 control_race() 函數包含應用於方差分析結果的顯著性截止參數以及其他相關參數。
將競賽方法與並行處理結合使用是有好處的。下一節顯示了一個數據集和模型的結果基準。
基準測試結果
為了進行演示,我們使用帶有 kernlab 包的 SVM 模型。
library(kernlab)
library(tidymodels)
library(finetune)
library(doParallel)
## -----------------------------------------------------------------------------
data(cells, package = "modeldata")
cells <- cells %>% select(-case)
## -----------------------------------------------------------------------------
set.seed(6376)
rs <- bootstraps(cells, times = 25)我們隻會調整模型參數(即不調整配方):
## -----------------------------------------------------------------------------
svm_spec <-
svm_rbf(cost = tune(), rbf_sigma = tune()) %>%
set_engine("kernlab") %>%
set_mode("classification")
svm_rec <-
recipe(class ~ ., data = cells) %>%
step_YeoJohnson(all_predictors()) %>%
step_normalize(all_predictors())
svm_wflow <-
workflow() %>%
add_model(svm_spec) %>%
add_recipe(svm_rec)
set.seed(1)
svm_grid <-
svm_spec %>%
parameters() %>%
grid_latin_hypercube(size = 25)我們將獲得有和沒有並行處理的網格搜索和方差分析競賽的時間:
## -----------------------------------------------------------------------------
## Regular grid search
system.time({
set.seed(2)
svm_wflow %>% tune_grid(resamples = rs, grid = svm_grid)
})## user system elapsed
## 741.660 19.654 761.357 ## -----------------------------------------------------------------------------
## With racing
system.time({
set.seed(2)
svm_wflow %>% tune_race_anova(resamples = rs, grid = svm_grid)
})## user system elapsed
## 133.143 3.675 136.822 賽車加速 5.56 倍。
## -----------------------------------------------------------------------------
## Parallel processing setup
cores <- parallel::detectCores(logical = FALSE)
cores## [1] 10cl <- makePSOCKcluster(cores)
registerDoParallel(cl)## -----------------------------------------------------------------------------
## Parallel grid search
system.time({
set.seed(2)
svm_wflow %>% tune_grid(resamples = rs, grid = svm_grid)
})## user system elapsed
## 1.112 0.190 126.650 網格搜索並行處理比順序網格搜索快 6.01 倍。
## -----------------------------------------------------------------------------
## Parallel racing
system.time({
set.seed(2)
svm_wflow %>% tune_race_anova(resamples = rs, grid = svm_grid)
})## user system elapsed
## 1.908 0.261 21.442 與賽車並行處理比順序網格搜索快 35.51 倍。
競速和並行處理會產生複合效應,但其大小取決於模型類型、重采樣次數、調整參數數量等。
參考
Kuhn, M 2014。“機器學習模型交叉驗證中的無效性分析”。 https://arxiv.org/abs/1405.6974。
例子
# \donttest{
library(parsnip)
library(rsample)
library(dials)
#> Loading required package: scales
## -----------------------------------------------------------------------------
if (rlang::is_installed(c("discrim", "lme4", "modeldata"))) {
library(discrim)
data(two_class_dat, package = "modeldata")
set.seed(6376)
rs <- bootstraps(two_class_dat, times = 10)
## -----------------------------------------------------------------------------
# optimize an regularized discriminant analysis model
rda_spec <-
discrim_regularized(frac_common_cov = tune(), frac_identity = tune()) %>%
set_engine("klaR")
## -----------------------------------------------------------------------------
ctrl <- control_race(verbose_elim = TRUE)
set.seed(11)
grid_anova <-
rda_spec %>%
tune_race_anova(Class ~ ., resamples = rs, grid = 10, control = ctrl)
# Shows only the fully resampled parameters
show_best(grid_anova, metric = "roc_auc", n = 2)
plot_race(grid_anova)
}
#>
#> Attaching package: ‘discrim’
#> The following object is masked from ‘package:dials’:
#>
#> smoothness
#> ℹ Racing will maximize the roc_auc metric.
#> ℹ Resamples are analyzed in a random order.
#> ℹ Bootstrap05: All but one parameter combination were eliminated.
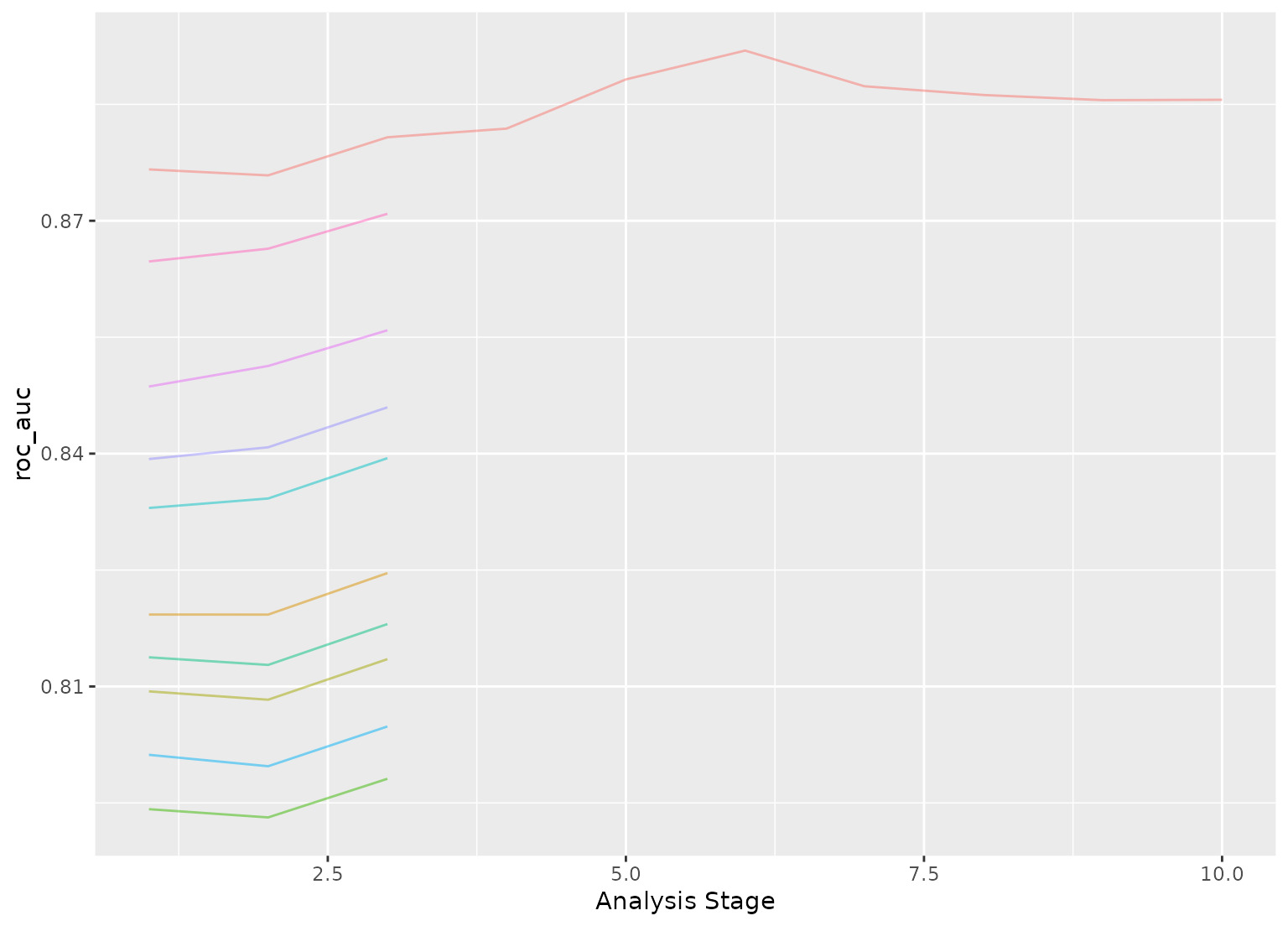 # }
# }
相關用法
- R finetune tune_race_win_loss 通過帶有輸贏統計數據的比賽進行高效的網格搜索
- R finetune tune_sim_anneal 通過模擬退火優化模型參數
- R finetune control_race 網格搜索競賽過程的控製方麵
- R finetune control_sim_anneal 模擬退火搜索過程的控製方麵
- R SparkR first用法及代碼示例
- R SparkR fitted用法及代碼示例
- R SparkR filter用法及代碼示例
- R SparkR freqItems用法及代碼示例
- R write.dbf 寫入 DBF 文件
- R forcats fct_relevel 手動重新排序因子級別
- R forcats as_factor 將輸入轉換為因子
- R forcats fct_anon 匿名因子水平
- R write.foreign 編寫文本文件和代碼來讀取它們
- R forcats fct_inorder 按首次出現、頻率或數字順序對因子水平重新排序
- R forcats fct_rev 因子水平的倒序
- R write.dta 以 Stata 二進製格式寫入文件
- R forcats fct_match 測試因子中是否存在水平
- R forcats fct_relabel 使用函數重新標記因子水平,並根據需要折疊
- R S3 讀取 S3 二進製或 data.dump 文件
- R forcats fct_drop 刪除未使用的級別
- R forcats fct_c 連接因子,組合級別
- R forcats fct_collapse 將因子級別折疊為手動定義的組
- R read.ssd 通過 read.xport 從 SAS 永久數據集中獲取數據幀
- R read.dbf 讀取 DBF 文件
- R read.mtp 閱讀 Minitab 便攜式工作表
注:本文由純淨天空篩選整理自Max Kuhn等大神的英文原創作品 Efficient grid search via racing with ANOVA models。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。