tune_sim_anneal() 使用迭代搜索過程根據先前的結果生成新的候選調整參數組合。它使用 Bohachevsky、Johnson 和 Stein (1986) 的廣義模擬退火方法。
用法
tune_sim_anneal(object, ...)
# S3 method for model_spec
tune_sim_anneal(
object,
preprocessor,
resamples,
...,
iter = 10,
param_info = NULL,
metrics = NULL,
initial = 1,
control = control_sim_anneal()
)
# S3 method for workflow
tune_sim_anneal(
object,
resamples,
...,
iter = 10,
param_info = NULL,
metrics = NULL,
initial = 1,
control = control_sim_anneal()
)參數
- object
-
parsnip模型規範或workflows::workflow()。 - ...
-
目前未使用。
- preprocessor
-
使用
recipes::recipe()創建的傳統模型公式或配方。僅當object不是工作流程時才需要這樣做。 - resamples
-
rset()對象。 - iter
-
搜索迭代的最大次數。
- param_info
-
dials::parameters()對象或NULL。如果沒有給出,則從其他參數派生參數集。當需要自定義參數範圍時,傳遞此參數可能很有用。 - metrics
-
yardstick::metric_set()對象,包含有關如何評估模型性能的信息。metrics中的第一個指標是要優化的指標。 - initial
-
整齊格式的初始結果集(如
tune_grid()、tune_bayes()、tune_race_win_loss()或tune_race_anova()的結果)或正整數。如果初始對象是順序搜索方法,則模擬退火迭代在初始結果的最後一次迭代之後開始。 - control
-
control_sim_anneal()的結果。
細節
模擬退火是一種全局優化方法。對於模型調整,它可用於迭代搜索參數空間以獲得最佳調整參數組合。在每次迭代中,通過以某種小的方式擾動當前參數來創建新的參數組合,使它們位於一個小鄰域內。這種新的參數組合用於擬合模型,並使用重采樣(或簡單的驗證集)來測量模型的性能。
如果新設置比當前設置具有更好的結果,則會接受它們並繼續該過程。
如果新設置的性能較差,則計算概率閾值以接受這些次優值。概率是結果次優程度以及迭代次數的函數。這被稱為算法的"cooling schedule"。如果次優結果被接受,則下一次迭代設置將基於這些較差的結果。否則,將從先前迭代的設置生成新的參數值。
此過程會持續進行預定義的迭代次數,並建議使用總體最佳設置。 control_sim_anneal() 函數可以指定迭代次數,而無需改進提前停止。此外,該函數還可用於指定重新啟動閾值;如果在一定次數的迭代內沒有發現全局最佳結果,則該過程可以使用最後已知的全局最佳設置重新啟動。
創建新設置
對於每個數字參數,可能值的範圍以及任何轉換都是已知的。當前值經過轉換並縮放為 0 到 1 之間的值(基於可能的值範圍)。生成位於rmin 和rmax 之間隨機半徑的球體上的一組候選值。刪除不可行的值並隨機選擇一個值。該值將重新轉換為原始單位和比例,並用作新設置。 control_sim_anneal() 的參數 radius 控製範圍鄰域大小。
對於分類參數和整數參數,每個參數都會以預定義的概率發生變化。 control_sim_anneal() 的 flip 參數可用於指定此概率。對於整數參數,使用附近的整數值。
當許多參數是非數字或唯一值很少的整數時,模擬退火搜索可能不是首選方法。在這些情況下,同一候選集可能會被測試多次。
冷卻時間表
為了確定接受新值的概率,需要計算性能差異百分比。如果要最大化性能指標,則為 d = (new-old)/old*100 。概率計算為 p = exp(d * coef * iter),而 coef 是用戶定義的常量,可用於增加或減少概率。
control_sim_anneal() 的cooling_coef 可用於此目的。
例子
# \donttest{
library(finetune)
library(rpart)
#>
#> Attaching package: ‘rpart’
#> The following object is masked from ‘package:dials’:
#>
#> prune
library(dplyr)
#>
#> Attaching package: ‘dplyr’
#> The following object is masked from ‘package:MASS’:
#>
#> select
#> The following objects are masked from ‘package:stats’:
#>
#> filter, lag
#> The following objects are masked from ‘package:base’:
#>
#> intersect, setdiff, setequal, union
library(tune)
library(rsample)
library(parsnip)
library(workflows)
library(ggplot2)
## -----------------------------------------------------------------------------
if (rlang::is_installed("modeldata")) {
data(two_class_dat, package = "modeldata")
set.seed(5046)
bt <- bootstraps(two_class_dat, times = 5)
## -----------------------------------------------------------------------------
cart_mod <-
decision_tree(cost_complexity = tune(), min_n = tune()) %>%
set_engine("rpart") %>%
set_mode("classification")
## -----------------------------------------------------------------------------
# For reproducibility, set the seed before running.
set.seed(10)
sa_search <-
cart_mod %>%
tune_sim_anneal(Class ~ ., resamples = bt, iter = 10)
autoplot(sa_search, metric = "roc_auc", type = "parameters") +
theme_bw()
## -----------------------------------------------------------------------------
# More iterations. `initial` can be any other tune_* object or an integer
# (for new values).
set.seed(11)
more_search <-
cart_mod %>%
tune_sim_anneal(Class ~ ., resamples = bt, iter = 10, initial = sa_search)
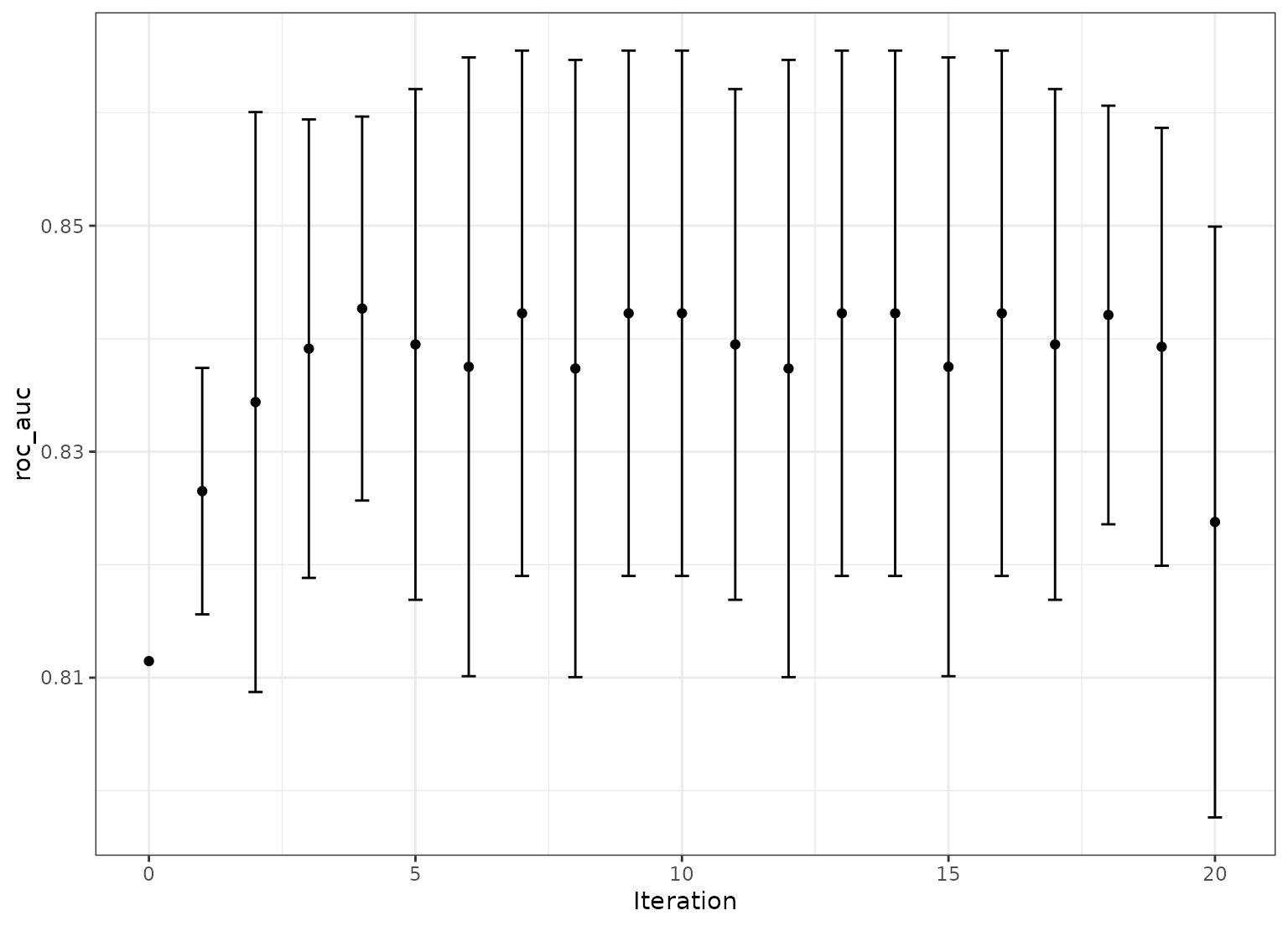
autoplot(more_search, metric = "roc_auc", type = "performance") +
theme_bw()
}
#> Optimizing roc_auc
#> Initial best: 0.81147
#> 1 ♥ new best roc_auc=0.82651 (+/-0.004242)
#> 2 ♥ new best roc_auc=0.83439 (+/-0.009983)
#> 3 ♥ new best roc_auc=0.83912 (+/-0.007893)
#> 4 ♥ new best roc_auc=0.84267 (+/-0.006609)
#> 5 ◯ accept suboptimal roc_auc=0.83949 (+/-0.008792)
#> 6 ◯ accept suboptimal roc_auc=0.83751 (+/-0.01065)
#> 7 + better suboptimal roc_auc=0.84225 (+/-0.009044)
#> 8 ◯ accept suboptimal roc_auc=0.83736 (+/-0.01063)
#> 9 + better suboptimal roc_auc=0.84225 (+/-0.009044)
#> 10 ◯ accept suboptimal roc_auc=0.84225 (+/-0.009044)
#> There were 10 previous iterations
#> Optimizing roc_auc
#> 10 ✔ initial roc_auc=0.84267 (+/-0.006609)
#> 11 ◯ accept suboptimal roc_auc=0.83949 (+/-0.008792)
#> 12 ◯ accept suboptimal roc_auc=0.83736 (+/-0.01063)
#> 13 + better suboptimal roc_auc=0.84225 (+/-0.009044)
#> 14 ◯ accept suboptimal roc_auc=0.84225 (+/-0.009044)
#> 15 ◯ accept suboptimal roc_auc=0.83751 (+/-0.01065)
#> 16 + better suboptimal roc_auc=0.84225 (+/-0.009044)
#> 17 ◯ accept suboptimal roc_auc=0.83949 (+/-0.008792)
#> 18 ✖ restart from best roc_auc=0.8421 (+/-0.007206)
#> 19 ◯ accept suboptimal roc_auc=0.83928 (+/-0.007538)
#> 20 ─ discard suboptimal roc_auc=0.82378 (+/-0.01017)
 # }
# }
相關用法
- R finetune tune_race_anova 通過方差分析模型進行高效網格搜索
- R finetune tune_race_win_loss 通過帶有輸贏統計數據的比賽進行高效的網格搜索
- R finetune control_race 網格搜索競賽過程的控製方麵
- R finetune control_sim_anneal 模擬退火搜索過程的控製方麵
- R SparkR first用法及代碼示例
- R SparkR fitted用法及代碼示例
- R SparkR filter用法及代碼示例
- R SparkR freqItems用法及代碼示例
- R write.dbf 寫入 DBF 文件
- R forcats fct_relevel 手動重新排序因子級別
- R forcats as_factor 將輸入轉換為因子
- R forcats fct_anon 匿名因子水平
- R write.foreign 編寫文本文件和代碼來讀取它們
- R forcats fct_inorder 按首次出現、頻率或數字順序對因子水平重新排序
- R forcats fct_rev 因子水平的倒序
- R write.dta 以 Stata 二進製格式寫入文件
- R forcats fct_match 測試因子中是否存在水平
- R forcats fct_relabel 使用函數重新標記因子水平,並根據需要折疊
- R S3 讀取 S3 二進製或 data.dump 文件
- R forcats fct_drop 刪除未使用的級別
- R forcats fct_c 連接因子,組合級別
- R forcats fct_collapse 將因子級別折疊為手動定義的組
- R read.ssd 通過 read.xport 從 SAS 永久數據集中獲取數據幀
- R read.dbf 讀取 DBF 文件
- R read.mtp 閱讀 Minitab 便攜式工作表
注:本文由純淨天空篩選整理自Max Kuhn等大神的英文原創作品 Optimization of model parameters via simulated annealing。非經特殊聲明,原始代碼版權歸原作者所有,本譯文未經允許或授權,請勿轉載或複製。